
1 Themenübersicht
Dieses Dokument beschreibt den Funktionsumfang und die Funktionsweise des Persistenzdienstes in Comarch ERP Enterprise.
Der Persistenzdienst ist die Schnittstelle, um Daten zu öffnen und zu speichern. Er ist Teil der System-Engine und stellt die wesentlichen Funktionen zur Verfügung. Der Persistenzdienst kann auf unterschiedliche Datenbank-Management-Systeme (DBMS) zugreifen. Ein uniformer Zugriff auf Datenbanken in unterschiedlichen DBMS wird gewährleistet. Das teilweise unterschiedliche Verhalten der DBMS wird durch den Persistenzdienst vor den Anwendungs- und Systemprogrammen verborgen. Die Funktionsweise eines Anwendungsprogramms ist damit unabhängig von dem verwendeten DBMS.
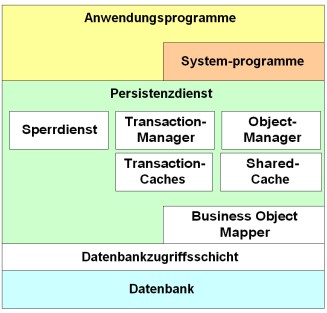
Schichten beim Datenbankzugriff
Ein Anwendungsprogramm (einschließlich Systemprogramme) greift immer über den Persistenzdienst auf die Datenbank zu. Der Persistenzdienst besteht aus mehreren Komponenten und hat einen schichtweisen Aufbau. Ein Programm benutzt immer den Transaction- oder Object-Manager, um Daten zu lesen oder zu speichern. Diese verwenden den Sperrdienst, um den Zugriff auf die Business Objects zu synchronisieren. Die Manager greifen auf die Transaction-Caches der Transaktionen und den Shared Cache zu. Zum Öffnen bzw. Speichern eines Business Objects benutzt der Persistenzdienst die für jedes Business Object generierte Mapper-Klasse, welche die Konvertierung der Daten zwischen dem Objektmodell und dem relationalen Modell der Datenbank vornimmt. Die Datenbankzugriffsschicht (JDBC-Treiber) stellt die Schnittstellen zur Verfügung, um direkt mit der Datenbank zu kommunizieren. Sie führt die Datenbankzugriffe aus und kapselt datenbankspezifische Eigenheiten. Die Datenbank speichert die Daten zu den Business-Object-Instanzen in Tabellen und führt SQL-Anfragen darüber aus.
2 Zielgruppe
Fortgeschrittene Entwickler
3 Voraussetzungen
Zum Verständnis des Dokuments sind die Grundlagen des Persistenzdienstes notwendig. Die Dokumentation „Programmierhandbuch“ vermittelt eine Einführung in die Grundlagen.
4 Abkürzungen
API Application Programming Interface
BO Business Object
BOD Business-Object-Definition
DB Datenbank
DHTML Dynamic HTML
GUI Graphical User Interface
GUID Global Unique Identifier
HTML Hyper Text Markup Language
JDK Java Development Kit
JVM Java Virtual Machine
IDE Integrated Development Environment
MM Message Manager
NLS National Language Support
LDT Logischer Datentyp
OLTP Online-Transaction-Processing
OLAP Online-Analytical-Processing
OM Object-Manager
OQL Object Query Language
SAS ERP-System-Application-Server
SDK ERP-System-Development-Kit
SOM ERP-System-Output-Manager
SQL Structured Query Language
SVM ERP-System-Virtual-Machine,
Synonym für SAS
TM Transaction-Manager
UI User Interface
URI Uniform Resource Identifier
URL Uniform Resource Locator
VE Visual Element
VEC Visual Element Container
5 Relevante Entwicklungsobjekte
Im Folgenden werden die Entwicklungsobjekte genauer beschrieben, mit denen der Persistenzdienst arbeitet.
5.1 Business Object
Ein Business Object ist ein Datencontainer ohne fachliche Logik. Zu einem Business Object werden eine Haupttabelle und Hilfstabellen mit den Zugriffsstrukturen aus den hinterlegten Indexdefinitionen in der Datenbank generiert. Ein Business Object ist eine technische Größe, die der Persistenzdienst lesen, speichern und löschen kann. Es erfolgt die Konvertierung zwischen dem in der Anwendung benutzten objektorientierten Datenmodell und dem relationalen Datenmodell der Datenbank. Business Objects sind die einzige Möglichkeit, um Daten dauerhaft zu speichern.
Jedes Business Object wird in der Anwendung „Entwicklungsobjekte“ beschrieben. Diese Objektbeschreibung umfasst im Wesentlichen die Attribut-, Schlüssel- und Beziehungsdefinitionen. Für diese Objektbeschreibung wird in der Anwendung „Entwicklungsobjekte“ der Entwicklungsobjekttyp „Business Object“ verwendet.
Die folgende Abbildung zeigt als Beispiel die Objektbeschreibung des Business Objects „Item“:
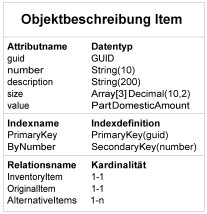
Beispiel für die Objektbeschreibung des Business Objects „Item“
5.1.1 Java-Klassen
Aus der Objektbeschreibung werden beim Aufruf des Tools „crtbo“ drei Java-Klassen generiert, die Haupt-, die State- und die Mapper-Klasse.
Die Java-Klassen werden in dem zum Namensraum korrespondierenden Java-Package unter dem Namen des Business Objects (ggf. mit Suffix „_State“ oder „_Mapper“) gespeichert. Die generierten Java-Klassen kapseln u. a. den Datenbankzugriff und bieten dem Anwendungsprogramm den Zugriff auf die Daten einer Business-Object-Instanz.
Die Hauptklasse, die gleichnamig zum Business Object ist, gewährt Zugriff auf die Eigenschaften einer Business-Object-Instanz. Die Hauptklasse enthält die get…()-, set…()- bzw. is…()-Methoden (bei Boolean) für den Zugriff auf die Attribute des Business Objects. Zu den eindeutigen Indizes werden die entsprechenden build…Key()-Methoden generiert, die zum Lesen einer Instanz über eindeutige Schlüsselwerte mit dem Persistenzdienst dienen. Zu den angegebenen Beziehungen werden die retrieve…()-Methoden generiert, über welche die zugeordneten Business Objects ermittelbar sind. Die öffentlichen Methoden werden allein durch die Objektbeschreibung festgelegt. Eine Klasse eines Business Objects darf nicht geändert werden. Das bedeutet insbesondere, dass keine Logikfunktionen zu der Hauptklasse hinzugefügt werden können. Diese müssen in separaten Logikklassen (im Namensraum mit dem Suffixe.log) implementiert werden.
Zum Business Object „Item“ (Beispiel) werden in der zugehörigen Hauptklasse folgende Methoden zum Zugriff auf die Attribute generiert:
public byte[] getGuid() ;
public void setGuid(byte[]newValue);
public String getNumber() ;
public void setNumber(String newValue);
public String getDescription() ;
public void setDescription(String newValue);
public CisDecimal[] getSize() ;
public setSize(CisDecimal[] newValue);
public DomesticAmount getValue() ;
public DomesticAmountMutable getMutableValue() ;
public void setValue (DomesticAmountMutable newValue);
Zum Erzeugen der Persistenzdienstschlüssel aus den definierten Business-Object-Schlüsseln werden folgende Methoden generiert:
public byte[] buildPrimaryKey(byte[] guid);
public byte[] buildByNumberKey(String number);
Für die Beziehungen werden folgende Methoden generiert:
public InventoryItem retrieveInventoryItem();
public OriginalItem retrieveOriginalItem();
public CisObjectIterator<AlternativeItem> retrieveAlternativeItems();
Erweiterung der Hauptklasse
Die Hauptklasse kann durch Ableitung erweitert werden, um bestimmte Methoden zu überschreiben. Diese Implementierungsklasse ist starken Einschränkungen unterworfen. Nur die in diesem Kapitel beschriebenen Funktionalitäten dürfen in der Klasse implementiert werden.
Die Implementierungsklasse unterliegt der folgenden Namenskonvention: der Namensraum wird von der Parent-Klasse übernommen, der Klassenname wird um das Suffix „Impl“ erweitert. Die Vererbungsbeziehung muss in den Metadaten des Business Objects erfasst werden. In der Anwendung „Entwicklungsobjekte“, Typ „Business Object“, Karteireiter „Editor“, Sub-Karteireiter „Einstellungen“, Rubrik „Sonstige Einstellungen“, Feld „Java-Klasse“ wird der Name der neuen Klasse eingetragen.
Die neu generierten Sourcen verwenden dann intern die abgeleitete Klasse. In der Anwendung darf die neue Klasse (z. B. BookImpl) nicht direkt verwendet werden. Dafür wird immer die Hauptklasse (z. B. Book) benutzt.
Methode get_instanceString():
In der Implementierungsklasse kann die Default-Implementierung durch eine eigene Implementierung ersetzt werden.
Der Persistenzdienst darf nicht verwendet werden mit Ausnahme der Methode resolveForeignKey() der Klasse com.cisag.pgm.datatype.CisObjectUtility. Damit kann zu einem Fremdschlüssel eine Business-Object-Instanz geöffnet werden. Die Methode liefert eine transiente Kopie der Business-Object-Instanz zum übergebenen technischen Schlüssel und Datenbanktyp in der Datenbanksprache der referenzierenden Business-Object-Instanz. Die Methode liefert „null“ für eine nicht existente Instanz. Die Signatur ist:
public static CisObject resolveForeignKey(
CisObject source,
String targetDatabaseAlias,
byte[] targetPrimaryKey);
Exemplarisch wird nachfolgend die Implementierung einer von der Klasse XYZ abgeleiteten Klasse XYZImpl gezeigt, in der der beschreibende „InstanceString” aus dem Business Key eines referenzierten Business Objects und dem eigenen Business Key gebildet wird.
Ein Beispiel:
Bei einem Auftrag ist der Business Key aus einem Typ (GUID des Typs (Fremdschlüssel)) und der Auftragsnummer zusammengesetzt. Der anzuzeigende „InstanceString“ soll aus der Identifikation des Auftragstyps und der Auftragsnummer bestehen.
public class XYZImpl {
…
public String get_instanceString() {
String result = getNumber();
byte[] typeGuid = getTypeGuid();
if (!Guid.isInvalidGuid(typeGuid)) {
// Nicht existierende Objekte auslassen
XYZType t = (XYZType) CisObjectUtility.
resolveForeignKey(this, CisTransactionManager.OLTP,
XYZType.buildPrimaryKey(typeGuid));
if (t != null) {
result = t.getCode() + ” ” + getNumber();
}
}
return result;
}
…
}
Methode get_permission():
Diese Methode dient zur Implementierung der Prüfung für inhaltsbezogene Berechtigungen.
5.1.2 Schlüssel
Die Objektbeschreibung eines Business Objects enthält u. a. auch eine Beschreibung der Indizes des Business Objects. Ein Index besteht im Wesentlichen aus einem Namen, einem Typ und einer Folge von Attributen des Business Objects. Einige dieser Indizes sind abhängig vom Typ „eindeutig“ und dienen zur Identifikation einer Business-Object-Instanz. Diese eindeutigen Indizes werden im Folgenden auch Schlüssel (Keys) genannt. Jedes Business Object besitzt einen Primärschlüssel (Typ „Primary Index“), optional einen Business Key (Typ „Secondary (Business Key)“) und optional beliebig viele Sekundärschlüssel (Typ „Secondary (unique)“).
Der Primärschlüssel eines Business Object ist immer ein technischer Schlüssel, der möglichst kompakt ist und sich während der Existenz einer Instanz nicht ändert. Der Primärschlüssel sollte mindestens ein Attribut vom Typ GUID beinhalten.
Die Verwendung von GUIDs bietet folgende Vorteile:
- GUIDs können effizient lokal berechnet werden, d. h. es muss kein Nummernvergabeservice oder dergleichen benutzt werden.
- GUIDs bringen in B*-Bäumen (DB-Indizes) eine hohe Selektivität.
- GUIDs sind gut geeignet für Hash-Verfahren.
- GUIDs sind weltweit eindeutig, sodass z. B. Replikationsszenarien einfacher implementiert werden können.
- GUIDs sind relativ kompakt (16 Bytes).
Der Konstantenwert eines Valueset-Elements ist eine technische Identifikation und kann im Primärschlüssel eines Business Objects verwendet werden. Der Primärschlüssel einer Business-Object-Instanz kann nicht mehr verändert werden, sobald diese das erste Mal auf der Datenbank gespeichert wurde. Lange Primärschlüssel (die z. B. mehr als 2 GUIDs umfassen) bedeuten einen höheren Aufwand für den Persistenzdienst. Daher ist empfehlenswert, den Primärschlüssel so kurz wie möglich zu halten.
Eine GUID im Primärschlüssel sollte nur für eine Instanz verwendet werden. In Sonderfällen ist zulässig, dass mehrere Business-Object-Instanzen über den gleichen GUID-Wert identifiziert werden. Grundsätzlich sollte das allerdings nur dann der Fall sein, wenn die betrachteten Business Objects sich auf dieselbe betriebswirtschaftliche Größe (z. B. Item, SalesItem, InventoryItem, …) beziehen.
Einige Objekte besitzen eine fachliche Identifikation wie z. B. die Artikelnummer oder die Kombination von Auftragsart und Auftragsnummer. Diese fachliche Identifikation wird im Business Key abgebildet und sollte eine menschenlesbare Referenz auf eine Business-Object-Instanz darstellen. Der Business Key sollte Attribute mit möglichst einfachem Typ enthalten, wie beispielsweise einen String für Nummern. Ein Business Key kann auch technische Fremdschlüssel enthalten wie die GUID der Auftragsart. Die Definition des Business Keys wird auch im ODBC-Treiber genutzt, um dem Benutzer durch zusätzliche virtuelle Attribute bessere Zugriffsmöglichkeiten zu eröffnen.
Weitere technische oder fachliche Identifikationen können als Sekundärschlüssel erfasst werden. Sekundärschlüssel können Attribute mit beliebigen primitiven Datentypen enthalten.
Beziehungen zwischen Business Objects werden ausschließlich über den Primärschlüssel definiert. Das hat folgende Gründe:
- Der Primärschlüssel ist kurz.
- Der Primärschlüssel besitzt eine hohe Selektivität.
- Der Primärschlüssel eines Business Objects kann nachträglich nicht mehr verändert werden.
Null-Werte
Null-Werte für Attribute eines Schlüssels sind nicht erlaubt. Der Entwickler hat dafür zu sorgen, dass die Attribute mit entsprechenden Werten gefüllt sind. Bei einem Attribut vom Typ GUID könnte das beispielsweise die ZEROGUID sein.
5.1.3 Erzeugung von Persistenzdienstschlüsseln
Der Persistenzdienst identifiziert eine Business-Object-Instanz durch eine technische Repräsentation eines Schlüssels der Business-Object-Instanz. Dieser Persistenzdienstschlüssel ist ein Byte-Array, in dem die Schlüssel-Attribute, die zugehörige Datenbank und die Klasse des Business Objects abgelegt sind. Weiterhin sind Informationen wie Typ des Schlüssels und Attributlängen enthalten.
Eine Business-Object-Klasse besitzt Methoden, um zu einem Schlüssel den Persistenzdienstschlüssel zu erzeugen. Zu jedem definierten Schlüssel eines Business Objects wird eine Methode zum Erzeugen der technischen Repräsentation generiert. Der Methodenname wird dabei aus dem Präfix „build“, dem Namen des Business-Object-Schlüssels und dem Suffix „Key“ gebildet. Der Methode werden die Werte der Schlüsselattribute als Parameter übergeben, z. B. heißt die Methode für den Primärschlüssel buildPrimaryKey(). Persistenzdienstschlüssel sind für eine Business-Object-Instanz nicht eindeutig und können sich bei Verwendung im Persistenzdienst nachträglich ändern. Aus diesem Grund dürfen Sie Persistenzdienstschlüssel beispielsweise nicht als Schlüssel in „CisHashMaps“ verwenden.
5.1.4 Objektreferenzen
Hinweis:
Objektreferenzen dürfen nur von der Comarch Software und Beratung AG verwendet werden. Zukünftig werden Objektreferenzen nicht mehr unterstützt.
Wenn Objektreferenzen noch verwendet werden, dann sollten diese sobald als möglich entfernt werden. Alternativ kann ein Byte-Array mit ausreichender Länge (z. B. 256 Byte) verwendet werden, in dem der mit „buildPrimaryKey“ gebaute Primärschlüssel des referenzierten Objekts gespeichert wird.
Eine Objektreferenz ist ein Byte-Array mit beschränkter Länge, welche genau eine Business-Object-Instanz identifiziert. Sie kann dazu verwendet werden, um aus einer Business-Object-Instanz auf eine andere unbekannte Business-Object-Instanz zu referenzieren. Die Objektreferenz ist unabhängig von der Länge des Primärschlüssels des referenzierten Business Objects. Sie stellt eine Indirektion dar, welche dem Primärschlüssel einer Business-Object-Instanz einen Schlüssel mit einer festgelegten Maximallänge zuordnet. Ist der Primärschlüssel kleiner der Maximallänge, wird die Objektreferenz zur Laufzeit aus diesem berechnet. Bei einem längeren Primärschlüssel wird die Zuordnung zwischen den Schlüsseln im Business Object „com.cisag.sys.kernel.obj.ObjectReference“ gespeichert, da der Schlüssel in diesem Fall nicht berechnet werden kann. Durch die beschränkte Länge der Objektreferenz ist möglich, diese in einem Binary-Datentyp zu speichern, ohne einen BLOB zu verwenden. Eine Objektreferenz kann genauso wie ein Persistenzdienstschlüssel für den Zugriff auf eine Business-Object-Instanz (z. B. über getObject()) benutzt werden.
Die Objektreferenz einer nicht transienten Business-Object-Instanz kann über die Methode „get_objectReference()“ der Business-Object-Klasse abgefragt werden. Dazu muss vorher eine Transaktion geöffnet werden. In Abhängigkeit von der Primärschlüssellänge erfolgt die Speicherung der Schlüsselzuordnung, falls für die Instanz noch keine Objektreferenz erzeugt wurde. Das geschieht transparent für den Entwickler. Die Transaktion muss immer mit „commit“ bestätigt werden, um eine gültige Objektreferenz zu erzeugen. Anderenfalls ist die zurückgegebene Objektreferenz ungültig. An einer transienten Business-Object-Instanz kann keine Objektreferenz abgefragt werden.
Bei Abfrage einer Objektreferenz für eine zeitabhängige Business-Object-Instanz, zeigt diese immer auf die aktuelle Version.
Objektreferenzen sollten aus den folgenden Gründen nur in Ausnahmefällen verwendet werden:
- Über eine Objektreferenz kann in OQL kein Join zu dem referenzierten Objekt definiert werden.
- Der ODBC-Treiber und andere Werkzeuge, die auf einer ERP-Datenbank arbeiten, können Objektreferenzen nicht auflösen.
- Das Abfragen einer Objektreferenz benötigt eine Transaktion, die mit „commit“ abgeschlossen werden muss. Eine fehlerhafte Verwendung kann unter Umständen zu nicht deterministischen Fehlern führen.
5.1.5 Part-Attribute
In der Business-Object-Klasse werden mehrere Methoden für den Zugriff auf ein Part-Attribut generiert:
- Die Methode „get<AttributName>()“ liefert eine unveränderbare Instanz der Imutable-Part-Klasse, an der die Werte der Attribute des Parts mithilfe der entsprechenden „..()“-Methoden abgefragt werden können.
- Die Methode „getMutable<Attributname>()“ liefert eine änderbare Instanz der Mutable-Part-Klasse, an der die Attributwerte mithilfe der entsprechenden „..()“-Methoden abgefragt oder mit den „set…()“-Methoden gesetzt werden können. Dabei wird nicht das State-Objekt der Business-Object-Instanz geändert, sondern nur die Instanz des Parts. Die geänderte Part-Instanz muss wieder explizit an die Business-Object-Instanz übergeben werden.
- Die „set()“-Methode für ein Part-Attribut speichert eine Mutable-Part-Instanz im State-Objekt der Business-Object-Instanz. Damit werden vorgenommene Änderungen in der Part-Instanz in die Business-Object-Instanz übernommen.
In OQL können von Part-Attributen die primitiven Attribute des Parts aber nicht der vollständige Part abgefragt werden. Über den Attributnamen des Part-Attributes kann mit OQL als Boolean abgefragt werden, ob das Part-Attribut in der Business-Object-Instanz „null“ ist. Wenn das Part-Attribut nicht null ist, so ist der Boolean „TRUE“. Die primitiven Attribute des Parts haben nur dann gültige Werte, wenn das Part-Attribut in der Business-Object-Instanz nicht „null“ ist.
5.1.6 Zeitabhängigkeit
Die Zeitabhängigkeit für ein Business Object wird in der Anwendung „Entwicklungsobjekte“ unter dem Karteireiter „Einstellungen“ konfiguriert. Die folgenden Arten werden vom Persistenzdienst gleich behandelt:
- „Immer neuen Datensatz einfügen“,
- „Immer aktuellen Datensatz schreiben“,
- „Gesteuert durch Anwendung“,
- „Datum mit Zeitzone durch Anwendung“ und
- „Zeitpunkt mit Zeitzone durch Anwendung“
Wenn für ein Business Object eine dieser Arten der Zeitabhängigkeit eingestellt wurde, dann ist das Business Object für den Persistenzdienst zeitabhängig. Ob eine konkrete Business-Object-Instanz zeitabhängig ist, kann mit der Methode „is_timeDependent()“ der Business-Object-Klasse abgefragt werden.
Das Business Entity und alle Dependents müssen die gleiche Art der Zeitabhängigkeit haben. Verboten ist, dass ein Dependent eine andere Art der Zeitabhängigkeit als das Business Entity hat.
5.1.6.1 Gültigkeitszeitraum
Zeitabhängige Business-Objects besitzen ein Gültigkeitsintervall. Dieses wird in den speziellen Attributen „validFrom“ und „validUntil“ des Business Objects vom Typ „Timestamp“ gespeichert. Der gespeicherte Zeitstempel im Attribut „validFrom“ gibt den Beginn und der gespeicherte Zeitstempel im Attribut „validUntil“ das Ende des Gültigkeitzeitraumes an. Der Zeitpunkt von „validFrom“ gehört zum Gültigkeitszeitraum, der von „validUntil“ angegebene Zeitpunkt aber nicht mehr.
Der Gültigkeitszeitraum von allen Dependents-Instanzen und der Business-Entity-Instanz muss identisch sein. Verboten ist, dass eine Dependent-Instanz einen anderen Gültigkeitszeitraum als die Business-Entity-Instanz hat.
5.1.6.2 Erweiterung der eindeutigen Schlüssel
Alle definierten eindeutigen Schlüssel werden bei einem zeitabhängigen Business Object implizit um das Attribut „validFrom“ erweitert. Das bedeutet, dass die Eindeutigkeit der Schlüsselwerte nicht mehr durch den Persistenzdienst bzw. durch die Datenbank sichergestellt ist. Zu einem konkreten Schlüsselwert können nun mehrere Instanzen existieren, die ab unterschiedlichen Zeitpunkten gültig sind. Man spricht deshalb auch von Versionen einer Business-Object-Instanz. Deren Gültigkeitsintervalle müssen überlappungsfrei und lückenlos sein. Eine Version ist genau für einen Zeitpunkt gültig, wenn dieser innerhalb ihres Gültigkeitsintervalls liegt. Die aktuell gültige Version einer zeitabhängigen Business-Object-Instanz ist die Version, in deren Gültigkeitsintervall der aktuelle Zeitpunkt liegt.
Schlüsselwertänderungen sind bei zeitabhängigen Business-Object-Instanzen nicht erlaubt, da der Persistenzdienst nicht automatisch alle dazu gehörigen Versionen berücksichtigt.
5.1.6.3 Erzeugung von Persistenzdienstschlüsseln für bestimmte Versionen
Zur Erzeugung eines Persistenzdienstschlüssels, um gezielt eine bestimmte Version zu öffnen, wird die Methode „buildTimeDependentKey()“ der Business-Object-Klasse verwendet. Dieser wird der Primärschlüsselwert und der Zeitstempel aus dem Attribut „validFrom“ als Parameter übergeben. Der zeitabhängige Persistenzdienstschlüssel einer Business-Object-Instanz kann über die Methode „get_timeDependentKey()“ abgefragt werden.
Mit den herkömmlich erzeugten Persistenzdienstschlüsseln wird die aktuelle Version geöffnet.
5.1.6.4 Zugriff auf benachbarte Versionen
Zu einer zeitabhängigen Version kann die direkte Nachfolgeversion mit der Methode „retrieve_nextVersion()“ bzw. die direkte Vorgängerversion mit der Methode „retrieve_previousVersion()“ abgefragt werden.
5.1.7 NLS-Attribute
NLS steht für „National Language Support“. Ein NLS-Attribut ist ein mehrsprachiges Attribut, das auf dem primitiven Typ „String“ basiert, bei dem das Merkmal „Mehrsprachigkeit möglich“ gesetzt wurde. Wenn ein Attribut einen lokalisierbaren logischen Datentyp zugeordnet hat, kann der Wert in mehreren Übersetzungen vorliegen. Die Übersetzungen eines Attributes werden in einem eigenen NLS-Business-Object gespeichert. Einer Datenbank sind immer eine Hauptsprache und evtl. mehrere Nebensprachen zugeordnet. Der Wert in der Hauptsprache eines Attributes wird in der Tabelle des zugehörigen Business Objects gespeichert und kann damit schnell abgefragt werden. Die Werte der Nebensprachen (Übersetzungen) eines Attributes werden in einer separaten Tabelle, der des NLS-Objektes, gespeichert. Aus Sicht des Anwendungsentwicklers geschieht der Zugriff auf ein NLS-Attribut weitgehend transparent.
Hinweis:
Das Öffnen eines Business Objects mit NLS-Attributen in der Hauptsprache benötigt deutlich weniger Zeit, als das Öffnen des gleichen Objekts in einer Nebensprache.
Die für ein Business Object auf der OLTP-Datenbank eingestellte Datenart beeinflusst, welche Nebensprachen verwendet werden. Business Objects mit der Datenart „Konfiguration-Stammdaten (Anzeige)“ können zusätzlich zu den Nebensprachen der OLTP-Datenbank auch die Nebensprachen der Repository-Datenbank in NLS-Attributen führen.
5.1.8 NLS-Business-Objects
NLS-Business-Objects sind vom Typ „Dependent“. Sie werden durch das System automatisch geführt. Ein NLS-Business-Object korrespondiert mit einem mehrsprachigen Attribut. Der Name setzt sich aus dem Namen des Business Objects, welches das mehrsprachige Attribut enthält, und dem Namen der Datenbank-Tabellenspalte des mehrsprachigen Attributes zusammen. Das NLS-Business-Object wird bei der Generierung des zugehörigen Business Objects automatisch in einem NLS-Namensraum erzeugt, der sich vom ursprünglichen Namensraum dadurch unterscheidet, dass nach dem Entwicklungspräfix die Zeichenkette „nls“ eingefügt wird, z. B. com.cisag.nls. Das Löschen des mehrsprachigen Attributes bzw. des Business Objects löscht auch das zugehörige NLS-Business-Object.
Ein NLS-Business-Object besitzt die folgenden Attribute:
| Name | Beschreibung |
| Präfix „X_“ + Primärschlüsselattributname des zugehörigen Business Objects | Das NLS-Business-Object enthält alle Primärschlüsselattribute des zugehörigen Business Objects. Zur Sicherung eines eindeutigen Attributnamens innerhalb des NLS-Business-Object wird dem Attributnamen das Präfix “X_” vorangestellt.
Der Primärschlüssel wird vom Persistenzdienst nur für OQL-Abfragen und Views benötigt. Ist das zugehörige Business Object vom Typ Business Entity, wird auf diesen Attributen die _entity-Beziehung des NLS-Dependents definiert. |
| validFrom | Ist das zugehörige Business Object zeitabhängig, so enthält auch das NLS-Business-Object das Attribut „validFrom“. |
| objectReference | Dieses Attribut enthält die Objektreferenz des zugehörigen Business Objects. Bei Persistenzdienstzugriffen über Persistenzdienstschlüssel (z. B. getObject()) stellt der Kernel die Verbindung vom Business Object zum NLS-Business-Object über die Objektreferenz des Business Objects her. |
| language | Dieses Attribut enthält die Sprache, in der eine Übersetzung vorliegt. |
| value | Dieses Attribut enthält die Übersetzung. |
| Präfix „X_“ + Primärschlüsselattributname des zugehörigen Entity-Business-Objects | Ist das zugehörige Business Object vom Typ „Dependent“, dann werden zusätzlich die Primärschlüsselattribute des zugehörigen Business Entitys aufgenommen. In diesem Fall wird die _entity-Beziehung zum Business Entity auf diesen Attributen definiert. |
Jedes NLS-Objekt besitzt einen Primärschlüssel und einen sekundären eindeutigen Schlüssel. Der Primärschlüssel bildet sich aus den Attributen „objectReference“, „language“ und „validFrom“ (nur bei Zeitabhängigkeit).
Der Sekundärschlüssel wird aus den Primärschlüsselattributen „language” des Business Object und bei Zeitabhängigkeit von dem Attribut „validFrom“ gebildet.
5.1.9 Änderungsinformationen/Fachliches Löschen
Wenn für ein Business Object die Option „Benutzer und Zeitpunkt protokollieren“ aktiviert ist, wird das komplexe Attribut UpdateInformation zum Business Object hinzugefügt, welches die Zeitpunkte und den Benutzer vermerkt, der die Instanz erstellt, als letztes verändert oder fachlich gelöscht hat. Die fachliche Löschmarkierung wird vom Persistenzdienst nicht ausgewertet, es ist den Anwendungen vorbehalten.
Mit der Methode „is_updateInfoRequired()“ der Business-Object-Klasse kann abgefragt werden, ob zu einem Business Object die Update-Informationen geführt werden sollen. Nur für Business Objects mit aktivierter Protokollierung werden die folgenden Methoden generiert:
- Die Methode „getUpdateInfo()“ liefert eine nicht änderbare Instanz des Parts „UpdateInformation“, an dieser die Daten über die entsprechenden „..()“-Methoden abgefragt werden können.
- Die Methode „getUpdateInfoMutable()“ liefert eine änderbare Instanz des Parts „UpdateInformation“, an dieser die Daten über die entsprechenden „..()“-Methoden abgefragt oder mit den „set…()“-Methoden geändert werden können.
- Der Methode „setUpdateInfo()“ kann eine änderbare Part-Instanz zum Speichern in der Business-Object-Instanz übergeben werden.
Zur Änderung der fachlichen Löschmarkierung dient die Methode „set_deleted()“. Die Löschmarkierung kann über die Methode „is_deleted()“ abgefragt werden. Diese beiden Methoden sind auch bei Business-Objects-Klassen implementiert, deren Business Objects keine Update-Information haben. In diesem Fall dürfen sie nur bei transienten Instanzen benutzt werden.
5.2 Persistente und transiente Instanzen von Business Objects
Eine Business-Object-Instanz besitzt zwei Zustände bezüglich der Datenbank und der Zugehörigkeit zu einer Transaktion. Die Zustände können mit den Methoden „is_persistent()“, „is_newObject()“ und „is_transient()“ abgefragt werden.
Zur Feststellung, ob eine Business-Object-Instanz in der Datenbank gespeichert ist, dient die Methode „is_persistent()“. Liefert sie „true“, ist die Instanz in der Datenbank vorhanden, bei „false“ nicht.
Mit der Methode „is transient()“ kann festgestellt werden, ob eine Business-Object-Instanz einen Transaktionskontext hat, d. h. ob die Instanz im Transaction-Cache der aktuellen Transaktion gespeichert ist oder nicht. Bei „false“ hat die Business-Object-Instanz einen Transaktionskontext und ist nur in der aktuellen Transaktion gültig. Bei „true“ ist die Instanz nicht an eine Transaktion gebunden.
Für neue Objekte, die mit „putObject()“ zum Speichern registriert sind, aber noch nicht in die Datenbank geschrieben wurden (die Top-Level-Transaktion wurde noch nicht „committed“), liefert die „is_persistent()“-Methode „false“. Ob das Objekt bereits zum Speichern registriert wurde, lässt sich mit „is_newObject()“ ermitteln. Diese Methode liefert dann „false“, wenn das Objekt weder persistent ist noch mit „putObject()“ registriert wurde.
Beim Arbeiten mit Business Objects müssen diese Kennzeichen (Flags) beachtet werden, um Comarch-ERP-Enterprise-konforme Anwendungen zu entwickeln. Eine nicht transiente Business-Object-Instanz, die über den Persistenzdienst geöffnet wurde, ist immer an die aktuelle Transaktion gebunden und ist nach dem Ende der Transaktion ungültig. Wird eine Business-Object-Instanz in einer Subtransaktion geöffnet, dann darf diese Instanz nur solange verwendet werden, wie die Subtransaktion geöffnet ist. Außerhalb der Transaktion kann eine weitere Benutzung der Instanz zu Programmfehlern führen und ist deshalb nicht erlaubt.
Hinweis:
Die Methoden „putObject()“ und „deleteObject()“ am Object-Manager erwarten immer nicht transiente Business-Object-Instanzen als Parameter, die über die Methoden „getObject()“ , „getObjectIterator()“ und „getObjectArray()“ unter Angabe der entsprechenden Zugriffs-Flags geöffnet bzw. erzeugt wurden.
Die Zustände einer Business-Object-Instanz bestimmen sich somit wie folgt:
- Eine Instanz, die mit der Methode „getObject()“ im Zugriffsmodus READ, READ_UPDATE oder READ_WRITE (Instanz existiert auf der Datenbank) gelesen wurde, ist persistent und nicht transient. Eine Instanz, die mit der Methode „getObject()“ im Zugriffsmodus READ_WRITE (Instanz existiert nicht auf der Datenbank) gelesen wurde, ist nicht persistent und nicht transient. Wenn die Instanz noch nicht im Transaction-Cache registriert war, so ist das „is_newObject()“-Flag true.
- Mit der Methode „getTransientCopy()“ kann eine transiente Kopie erzeugt werden. Das Persistenz-Flag wird in die neu erstellte transiente Kopie übernommen.
- Eine Instanz, die über die Methode „newTransientInstance()“ erzeugt wurde, ist nicht persistent und transient.
- Zwischen transienten und nicht transienten Instanzen können mit der Methode „copyTo()“ die Attributwerte kopiert werden.
- Die Methode „getObject()“ steht stellvertretend für die Methoden „getObjectArray()“ und „getObjectIterator()“, die intern auf „getObject()“ zurückgreifen.
5.2.1 Methode getTransientCopy()
Wenn eine Business-Object-Instanz mithilfe des Object-Managers von der Datenbank geöffnet wurde, ist sie nicht transient und an ihre Ladetransaktion gebunden. Um die Instanz transaktionsübergreifend zu verwenden, muss mit der Methode „getTransientCopy()“ der Business-Object-Klasse eine neue transiente Kopie erzeugt werden. Neben den Attributwerten wird das persistent-Flag ebenfalls kopiert und das transient-Flag wird auf true gesetzt. Die erzeugte transiente Business-Object-Instanz gehört zu keiner Transaktion und kann transaktionsübergreifend verwendet werden. Diese Methode ist sehr nützlich, wenn man sich den Inhalt einer Business-Object-Instanz über das Transaktionsende hinaus merken will, z. B. für die GUI-Anzeige.
5.2.2 Methode newTransientInstance()
Die Methode „newTransientInstance()“ einer Business-Object-Klasse erzeugt eine leere transiente, nicht persistente Business-Object-Instanz „(is_persistent()“ liefert „false“, „is_transient()“ liefert „true“).
5.2.3 Methode copyTo()
Die Methode „copyTo()“ der Business-Object-Klasse kann benutzt werden, um die Attributwerte einer Instanz in eine andere Instanz des gleichen Business Objects zu kopieren. Die Quelle bzw. das Ziel können persistente oder transiente Instanzen sein. „copyTo()“ überträgt auf jeden Fall immer die Attributwerte und den Business Key der Quelle zum Ziel. In den folgenden Fällen werden Sonderbehandlungen vorgenommen:
- Ist das Ziel eine transiente Instanz, werden zusätzlich das Persistenz-Flag und der Primärschlüssel von der Quelle kopiert.
- Ist das Ziel eine nicht persistente Instanz, wird der Primärschlüssel der Quelle kopiert.
- Ist das Ziel transient und ist für die Business-Object-Klasse die Update-Information erforderlich, wird die gesamte Update-Information von der Quelle kopiert. Die fachliche Löschmarkierung der Quelle (delete-Flag) wird immer ins Ziel kopiert.
- Ist das Ziel transient und zeitabhängig, dann werden die Attribute „validFrom“ und „validUntil“ der Quelle kopiert.
Hinweis:
Auf ein nicht transientes, persistentes Ziel wird kein Attribut oder Flag kopiert, was den Transaktionskontext des Business-Objects ändern könnte. Auf ein transientes Ziel wird alles kopiert.
5.2.4 Methode set_persistent()
Das persistent-Flag kann bei transienten Objekten durch die Methode „set_persistent()“ geändert werden, bei nicht transienten Objekten führt diese Methode zu einem Laufzeitfehler.
5.2.5 Spezielle Methoden der Business-Object-Klasse
Eine generierte Business-Object-Klasse besitzt spezielle Methoden, um auf Daten zuzugreifen:
| Methodenname | Funktion |
| retrieve_instances() | Diese Methode liefert einen Objekt-Iterator, mit dem über alle Instanzen des Business Objects iteriert werden kann. |
| get_type() | Diese Methode liefert die Typ-Konstante des Business Objects zurück. |
| get_contentLanguage() | Diese Methode liefert die Inhaltssprache, mit der die Business-Object-Instanz geöffnet wurde. |
| retrieve_entity() | Bei einer Business-Object-Klasse eines Business Objects vom Typ „Dependent“ ist diese Methode implementiert. Sie liefert die Business-Object-Instanz des Business Entitys, zu der die Dependent-Instanz gehört. |
| retrieve_dependents() | Bei einer Business-Object-Klasse eines Business Objects vom Typ „Business Entity“ ist diese Methode implementiert. Sie liefert einen Objekt-Iterator, mit dem über alle Instanzen der zugehörigen Dependents iteriert werden kann. |
5.3 Part
Ein Part dient der Realisierung von komplexen Attributen von Business Objects. Sie definieren eine Datenstruktur, die eine Attributgruppe unter einer aussagekräftigen Bezeichnung zusammenfasst. Komplexe Attribute haben keinen eigenen Schlüssel, sondern sind Teil eines Business Objects, daher der Name „Part“.
Parts ermöglichen die Wiederverwendung von einmal modellierten Datenstrukturen bei verschiedenen Business Objects. Ein Part besitzt keine eigene Datenbanktabelle. Die Part-Attribute werden in der Tabelle des Business Objects gespeichert. In einer Part-Definition können auch Beziehungen zu anderen Business Objects angegeben werden, allerdings kann ein Part nie das Ziel einer Beziehung sein. Es werden mehrere Java-Klassen generiert, die zum Zugriff auf eine Part-Instanz in der Anwendung dienen:
- Über die Imutable-Klasse kann nur lesend auf die Attribute des Parts zugegriffen werden. Sie besitzt nur die entsprechenden „..()“-Methoden zum Lesen der Attributwerte. Zu einer Beziehung wird die entsprechende „retrieve…()“-Methode generiert.
- Über die Mutable-Klasse kann lesend und schreibend auf die Attribute des Parts zugegriffen werden und besitzt zusätzlich die dazu notwendigen „..()“-Methoden.
- Eine Mapper-Klasse wird generiert, wenn dem Part Beziehungen zugeordnet sind, die intern vom Persistenzdienst für den Zugriff auf das Business Object der Beziehung verwendet wird.
5.4 OQL-View
Oftmals wird ein Business Object mit ergänzenden Daten aus anderen referenzierten Business Objects in Anwendungen immer wieder verwendet. Statt Öffnen des Business Objects, Öffnen der referenzierten Business Objects über die Beziehungen und Auswahl der interessanten Attribute oder der Verwendung eines immer gleichen OQL-Statements – ist einfacher, eine Sicht (View) auf die gewünschten Informationen zu erfassen. Diese Sicht lässt sich in der Anwendung wie ein normales Business Object verwenden, mit der Einschränkung, dass die Daten nur gelesen werden können. Änderungen können an zentraler Stelle vorgenommen werden. Die Sicht auf die Daten wird in Form eines OQL-SELECT-Statements angegeben. Bezüglich der Verwendung von Joins und WHERE-Klauseln bestehen keine Einschränkungen und somit sind komplexe Anfrage-Statements möglich.Aus der OQL-View-Definition werden vom System (Tool „crtbo“) drei Java-Klassen generiert, die Haupt-, State- und Mapper-Klasse. Die Java-Klassen werden in dem zum Namensraum korrespondierenden Java-Package unter dem Namen des OQL-Views (ggf. mit Suffix „_State“ oder „_Mapper“) gespeichert. Die Hauptklasse verwendet der Entwickler in der Anwendung zum Zugriff auf Instanzen des OQL-Views, während die State- und Mapper-Klassen vom Persistenzdienst benötigt werden, um die Datenbankzugriffe zu realisieren. Die Hauptklasse enthält für den Zugriff auf die Attribute des Views die „get…()“- bzw. „is…()“-Methoden (bei Boolean) und die Methode „buildPrimaryKey()“ zum Öffnen einer Instanz über den Primärschlüssel. In der Anwendung verhält sich der View ähnlich einem Business Object, allerdings sind nur Lesezugriffe möglich.
Auf der Datenbank wird der zugehörige Datenbank-View erzeugt, wobei das OQL-Statement vom System in ein SQL-Statement konvertiert wird, welches der Datenbank-View verwendet, um die virtuelle Datenbanktabelle zu erzeugen.
DBMS können Datenbankanweisungen, die Views enthalten, nicht immer vollständig optimieren. Insbesondere in Suchen, Berichten und Cockpits beeinträchtigt die Verwendung von OQL-Views die Antwortzeiten der Datenbank. Die Verwendung der OQL-Views ist daher für diese Zwecke nicht empfohlen, verwenden Sie stattdessen OQL, OQL-Suchen oder aber bei Berichten virtuelle Tabellen und Funktionen.
6 Aufbau des Persistenzdienstes
Der Persistenzdienst besteht aus mehreren Komponenten. Einige dieser Komponenten, wie beispielsweise der „Shared Cache“ oder der „Transaction-Cache“, sind für den Entwickler nur über die Schnittstellen des Object-Managers bzw. des Transaction-Managers ansprechbar. Im Folgenden werden die Aufgaben aller wesentlichen Komponenten des Persistenzdienstes beschrieben.
6.1 Shared Cache
Der „Shared Cache“ dient der Zwischenspeicherung von geöffneten Business-Object-Instanzen im Hauptspeicher, um die Anzahl der Datenbankzugriffe zu minimieren. Er trägt damit in ganz erheblichem Maße zur Leistungsfähigkeit des gesamten Systems bei. Der Zugriff auf eine Business-Object-Instanz im Shared Cache ist deutlich schneller als der Zugriff auf diese in der Datenbank. Der Shared Cache arbeitet nach der LRU-Strategie (least recently used) und enthält die vom Application-Server zuletzt verwendeten Business-Object-Instanzen. Wenn eine Anwendung ein Business Object von der Datenbank lesen will, so wird zuerst nachgesehen, ob das Business Object im Shared Cache vorhanden ist, ansonsten wird es von der Datenbank gelesen.
Der Shared Cache ist in jedem Application-Server, der Datenbankzugriffe ausführt, genau einmal vorhanden (Singleton). In einem System mit mehr als einem Application-Server wäre der Kommunikationsaufwand zwischen den Application-Servern sehr hoch, wenn die Objekte in allen Shared Caches zu jeder Zeit den gleichen Zustand haben sollen wie in der Datenbank. Es ist ausreichend, wenn in einem bestimmten Intervall (30 Sekunden) die Objekte im Shared Cache aktualisiert werden.
Der Hauptspeicher eines Application-Servers ist begrenzt, deshalb können nicht alle Objekt gleichzeitig im Shared Cache gehalten werden. Die Größe des Shared Caches wird beim Einrichten des Application-Servers eingestellt. Der Shared Cache kann in unterschiedliche Partitionen beschränkter Größe unterteilt werden. Die Business Objects werden abhängig von der Datenart und Datenbank in einer der Partitionen geführt.
6.2 Transaction-Cache
Der Transaction-Cache wird verwendet, um einen transaktionslokalen Kontext herzustellen. Jede Top-Level-Transaktion hat ihren eigenen Transaction-Cache. Solange eine Transaktion nicht mit „commit“ bestätigt wurde, werden die Business-Object-Instanzen, die innerhalb dieser Transaktion zum Ändern registriert sind, nur in ihrem Transaction-Cache gehalten. Der Object-Manager sucht zu öffnende Objekte zuerst im jeweiligen Transaction-Cache. Änderungen in einer Transaktion sind nur für Zugriffe innerhalb dieser Transaktion sichtbar. Für alle anderen Transaktionen wird eine Änderung erst sichtbar, wenn die Daten aus dem Transaction-Cache in den Shared Cache und in die Datenbank übernommen wurden. Das geschieht, wenn die ändernde Transaktion mit „commit“ abgeschlossen wird.
6.3 Transaction-Manager
Der Transaction-Manager führt und steuert die Transaktionen. Er kann eine neue Top-Level- oder Subtransaktion starten und eine Transaktion bestätigen (commit) bzw. abbrechen (rollback).
Zur Isolation der transaktionslokalen Kontexte werden die State-Objekte der Business Objects und die Caches der Transaktionen verwendet.
6.3.1 Transaktionen
Eine Transaktion ist eine Klammer für eine schreibende fachliche Datenbankoperation. Sie besteht aus ein oder mehreren Aktionen auf der Datenbank, die alle oder keine ausgeführt werden (Atomarität). Sie werden explizit geöffnet, geschlossen bzw. abgebrochen. Die Änderungen sind erst nach erfolgreichem Abschluss der Transaktion nach außen hin sichtbar. Ein Abbruch macht alle vorigen Änderungen rückgängig. Eine ERP-Transaktion entspricht dem Transaktionsverständnis bei relationalen Datenbanksystemen und erfüllt damit die ACID-Eigenschaften.
Der Persistenzdienst unterstützt geschlossene, geschachtelte Transaktionen. Das bedeutet, dass eine Transaktion im Prinzip beliebig viele Subtransaktionen beliebiger Schachtelungstiefe haben kann. Geschachtelte oder Subtransaktionen sind Transaktionen, die innerhalb einer bestehenden Transaktion, der Parent-Transaktion, begonnen und beendet werden. Subtransaktionen sind hier nicht-vital, d. h. der Abbruch einer Subtransaktion erzwingt nicht den Abbruch der Parent-Transaktion. Änderungen innerhalb einer Subtransaktion werden nur bei einem erfolgreichen „commit“ auch in der jeweiligen Parent-Transaktion sichtbar und beim „commit“ der Top-Level-Transaktion auf die Datenbank geschrieben und damit persistent.
In der Regel werden Softwarekomponenten so ausgelegt, dass sie eine bestimmte, abgeschlossene Leistung erbringen. Das muss oft transaktionssicher geschehen. Entweder kann die Komponente die Leistung voll erbringen oder nicht. Die Komponente wird eine Transaktion verwenden, um ihre Operationen innerhalb dieser Transaktion auszuführen. Bei geschachtelten Komponentenaufrufen ergeben sich automatisch geschachtelte Transaktionen.
Eine Top-Level-Transaktion und alle ihre Subtransaktionen dürfen nur auf genau eine Datenbank lesend und schreibend zugreifen. Datenbankübergreifende Transaktionen sind nicht möglich.
Der Transaction-Manager hat zu einer Zeit immer genau eine aktuelle Transaktion. Zwar können mehrere Top-Level-Transaktionen in der Session geöffnet werden, aber nur die zuletzt geöffnete ist die aktuelle Top-Level-Transaktion. Wurde nicht explizit eine Transaktion begonnen, ist implizit eine Dummy-Transaktion auf der Default-OLTP-Datenbank geöffnet. Mit dieser ist nur ein lesender Datenbankzugriff möglich, sie kann keine Subtransaktionen haben und nicht in Datenbanken schreiben.
Wenn Business-Object-Instanzen innerhalb einer Transaktion geändert werden, so werden Sperren für diese angefordert. Diese Sperren sind an die jeweilige Top-Level-Transaktion gebunden und werden erst nach Abschluss der Top-Level-Transaktion freigeben. D. h. auch in Subtransaktionen angeforderte Sperren werden unabhängig davon, ob die Subtransaktion bestätigt oder abgebrochen wird, bis zum Abschluss der Top-Level-Transaktion gehalten.
6.3.2 Steuerung von Transaktionen
Die Instanz des Transaction-Managers kann in der Anwendung am Environment der aktuellen Session abgefragt werden. Der Transaction-Manager bietet folgende Funktionen für Transaktionen:
- Öffnen einer neuen Top-Level-Transaktion (beginNew)
- Öffnen einer neuen Read-Only-Transaktion (beginReadOnly)
- Öffnen einer Transaktion (begin)
- Bestätigen einer Transaktion (commit)
- Abbrechen einer Transaktion (rollback)
- Erzeugen eines neuen Top-Level-Transaktionsobjekts (createNew)
- Erzeugen eines neuen Read-Only-Transaktionsobjekts (createReadOnly)
- Erzeugen eines Transaktionsobjekts (create).
Das mit den create-Funktionen erzeugte Transaktionsobjekt repräsentiert die Transaktion. Das Transaktionsobjekt besitzt die folgenden Methoden:
- Bestätigen der Transaktion (commit)
- Bestätigen der Transaktion und Öffnen einer neuen Transaktion (commitBlock)
- Bestätigen der Transaktion, wenn die maximale Transaktionsgröße überschritten wurde, und Öffnen einer neuen Transaktion (commitIfSizeLimitExceeded)
- Prüfen, ob die Transaktion noch offen ist (isOpen)
- Schließen der Transaktion (close)
Transaktionen können entweder mit „begin…“ oder mit „create…“ geöffnet werden. Beim Öffnen einer Transaktion mit „create…“ entsteht ein Transaktionsobjekt, das die Schnittstelle „AutoCloseable“ implementiert. Wenn Sie neue Anwendungen und Funktionen entwickeln, sollten Sie „create…“ statt „begin…“ verwenden. Viele ältere Anwendungen verwenden „begin…“.
6.3.2.1 Datenbank-Alias
Am Transaction-Manager sind die Datenbank-Alias als Konstanten definiert. Diese können benutzt werden, um eine Transaktion für die entsprechende Datenbank zu öffnen.
| Aliasname | Bedeutung |
| OLTP | Dieser Alias steht für die aktuelle OLTP-Datenbank der Session. |
| OLAP | Dieser Alias steht für die aktuelle OLAP-Datenbank der Session. |
| CONFIGURATION | Dieser Alias steht für die aktuelle Konfigurations-Datenbank der Session. |
| REPOSITORY | Dieser Alias steht für die Repository-Datenbank. |
| Konkreter Datenbankname | Der Name einer mit dem SAS verbundenen Datenbank kann ebenfalls angegeben werden, was aber nur in Ausnahmefällen sinnvoll ist, da der Programm-Code dadurch nicht auf ein anderes ERP-System übertragbar ist. |
6.3.2.2 Erzeugen einer Top-Level-Transaktion
Über die Methode „beginNew()“ bzw. „createNew()“ wird eine neue Top-Level-Transaktion für eine konkrete Datenbank erzeugt. Ein Datenbank-Alias oder eine Datenbank-GUID kann übergeben werden. Wird keine Datenbank übergeben, dann wird die aktuelle OLTP-Datenbank der Session verwendet.
6.3.2.3 Erzeugen einer Read-Only-Transaktionen
Die Methode „beginReadOnly()“ bzw. „createReadOnly()“ wird eine neue Read-Only-Transaktion für eine konkrete Datenbank erzeugt. Ein Datenbank-Alias oder eine Datenbank-GUID kann übergeben werden. Wird keine Datenbank übergeben, dann wird die aktuelle OLTP-Datenbank der Session verwendet. Das Öffnen einer Read-Only-Transaktion belastet das System weniger als das Öffnen einer normalen Top-Level-Transaktion. Insbesondere wenn sehr viele Transaktionen in kurzer Zeit geöffnet werden, kann sich die Verwendung von Read-Only-Transaktionen lohnen.
Innerhalb einer Read-Only-Transaktion sind die folgenden Aktionen verboten:
- Verändern eines Business Objects
- Anforderung von Business-Object-Sperren
- Öffnen von Subtransaktionen
- Beenden der Transaktion mit „commit()“
6.3.2.4 Erzeugen einer Subtransaktion
Der Aufruf der Methode „begin()“ bzw. „create()“ ohne Parameter erzeugt eine neue Transaktion. Wird keine Datenbank übergeben, dann wird ebenso wie bei „beginNew()“ die aktuelle OLTP-Datenbank der Session verwendet.
Wird die Methode „begin()“ auf Ebene der Dummy-Transaktion oder innerhalb einer Top-Level-Transaktion aufgerufen und ist die verwendete Datenbank nicht gleich der Datenbank der Parent-Transaktion, dann entsteht ein Laufzeitfehler. Bei Übereinstimmung der Datenbanken wird, falls die übergeordnete Transaktion die Dummy-Transaktion ist, eine neue Top-Level-Transaktion geöffnet, ansonsten wird eine Subtransaktion geöffnet.
6.3.2.5 Bestätigen einer Transaktion
Mit der Methode „commit()“ am Transaktions-Manager oder am Transaktionsobjekt wird die aktuelle Transaktion bestätigt. Ist eine Top-Level-Transaktion betroffen, dann werden die registrierten Objekte in die Datenbank geschrieben oder gelöscht. Bei einer Subtransaktion werden die registrierten Objekte noch nicht in die Datenbank geschrieben, sondern an die Parent-Transaktion vererbt, d. h. in deren transaktionslokalen Kontext eingefügt, und sind somit für diese Transaktion sichtbar. Erst wenn die zugehörige Top-Level-Transaktion mit „commit()“ bestätigt wird, werden diese Objekte in der Datenbank persistent gemacht.
Erst beim „commit“ der Top-Level-Transaktion werden Nummern mit der automatischen Nummernvergabe gezogen bzw. wird die Update-Information der geänderten Business-Object-Instanzen aktualisiert.
Wenn eine Dependent-Instanz geändert wird, dann werden der Änderungszeitpunkt und der aktuelle Benutzer in die Update-Information der Business-Entity-Instanz eingetragen. Wenn die geänderte Instanz selbst eine Update-Information besitzt, dann wird diese ebenfalls aktualisiert.
6.3.2.6 Abbrechen einer Transaktion
Mit der Methode „rollback()“ wird die aktuelle Transaktion abgebrochen. Das bedeutet, dass alle Änderungen, die dem Persistenzdienst während dieser Transaktion oder einer ihrer Subtransaktionen mitgeteilt wurden, verworfen werden. Das trifft gleichermaßen auf eine abgebrochene Top-Level-Transaktion wie auf eine Subtransaktion zu.
Hat die abgebrochene Transaktion eine Parent-Transaktion, dann ist deren transaktionslokaler Kontext unverändert, also in demselben Zustand wie beim Start der Subtransaktion. Die Parent-Transaktion wird zur aktuellen Transaktion.
Bei einer abgebrochenen Top-Level-Transaktion wird die Dummy-Transaktion zur aktuellen Transaktion.
Die Methode „close()“ am Transaktionsobjekt bricht eine offene Transaktion analog zu „rollback()“ ab. Falls die Transaktion mit „commit()“ bereits bestätigt wurde, muss „close()“ dennoch aufgerufen werden. In diesem Fall hat „close()“ aber keinen Effekt auf das Ergebnis der Transaktion.
6.3.2.7 Beispiel zur Verknüpfung von Top-Level- und Subtransaktionen
Die folgende Abbildung zeigt eine Top-Level-Transaktion mit drei Subtransaktionen. Die Änderungen der „Subtransaktion 2“ werden in den Transaction-Cache der „Subtransaktion 1“ übernommen, da die „Subtransaktion 2“ mit „commit“ abgeschlossen wird. Die Änderungen der „Subtransaktion 1“ werden jedoch nicht in die Top-Level-Transaktion übernommen, da die „Subtransaktion 1“ mit „rollback“ rückgängig gemacht wird. Damit werden auch die Änderungen der „Subtransaktion 2“ verworfen. Die Änderungen der „Subtransaktion 3“ werden durch „commit“ in die Top-Level-Transaktion übernommen. Somit werden beim „commit“ der Top-Level-Transaktion die Änderungen direkt in dieser und die Änderungen der „Subtransaktion 3“ auf der Datenbank persistent.
![]()
6.3.3 Transaktionsabhängigkeit von Business-Object-Instanzen
Vom Object-Manager erzeugte Business-Object-Instanzen gehören zu genau der Transaktion oder Subtransaktion, in der sie geöffnet bzw. erzeugt wurden. Sie dürfen nur in dieser Transaktionn verwendet werden. Wenn die Transaktion, in der sie geöffnet wurden, geschlossen wird, ist die Instanz ungültig.
Transaktionsunabhängige Objekte können mit der Methode „getTransientCopy()“ erzeugt werden. Diese Methode erstellt eine Kopie der Business-Object-Instanz, die zu keiner Transaktion gehört und damit transaktionsübergreifend verwendet werden kann. Alle Business Objects besitzen diese Methode.
Zur Erzeugung einer leeren transaktionsunabhängigen Instanz eines Business Objects kann die Methode „newTransientInstance()“ benutzt werden.
6.3.4 Sichtbarkeit von Änderungen in geschachtelten Transaktionen
Die Sichtbarkeit von Änderungen an den Business-Object-Instanzen (damit ist die Isolationseigenschaft von Transaktionen gemeint) wird auf drei Ebenen gesteuert.
Aktuelle Transaktion mit Subtransaktionen
Auf der Ebene der aktuellen Transaktion und ihren Subtransaktionen sind Attributänderungen nur in der jeweiligen Business-Object-Instanz bekannt. Erst nach einem „putObject()“ werden sie für die aktuelle Transaktion und für alle folgenden Subtransaktionen sichtbar, d. h. ein erneutes „getObject()“ liefert die geänderte Business-Object-Instanz. Bereits geöffnete Instanzen des geänderten Business Objects haben noch den alten Wert, bis sie erneut mit „getObject()“ gelesen werden.
Parent-Transaktion der ändernden Transaktion
Attributänderungen sind in der Parent-Transaktion der ändernden Transaktion nur sichtbar, wenn die Business-Object-Instanz in der ändernden Transaktion mit „putObject()“ gespeichert wurde, diese Transaktion erfolgreich mit „commit()“ beendet wurde und die Business-Object-Instanz mit „getObject()“ neu gelesen wird. Das gilt entsprechend auch für tiefere Schachtelungsebenen.
Änderung des Datenbankinhaltes
Der Inhalt der Datenbank reflektiert Änderungen (INSERT/UPDATE/DELETE) erst dann, wenn die Top-Level-Transaktion erfolgreich mit „commit“ beendet wurde. Erst zu diesem Zeitpunkt werden alle Änderungen einer Top-Level-Transaktion und ihrer erfolgreich beendeten Subtransaktionen in die Datenbank geschrieben. Sie sind danach global sichtbar. Ein erneutes Lesen ist notwendig, da vor dem „commit“ der ändernden Transaktion gelesene Business-Object-Instanzen noch die alten Werte enthalten. OQL-Statements arbeiten immer auf den tatsächlich persistenten Daten, d. h. vorgenommene Änderungen an Business-Object-Instanzen in der gleichen Transaktion sind für OQL-Abfragen noch nicht sichtbar.
6.3.5 Fehlerbehandlung bei Transaktionen
Sicherzustellen ist, dass eine geöffnete Transaktion immer mit rollback abgebrochen oder mit commit beendet wird. Die Fehlerbehandlung hängt davon ab, ob die Transaktion mit „begin…“ oder „create…“ geöffnet wurde.
Wenn die Transaktion mit „create…“ geöffnet wurde, dann ist die Fehlerbehandlung einfach und der Entwickler kann kaum Fehler machen. Insbesondere wegen der einfacheren Fehlerbehandlung sollten Sie Transaktionen bevorzugt mit „create…“ öffnen.
Wenn die Transaktion mit „begin…“ geöffnet wurde, müssen die im Folgenden aufgeführten Programmiermuster eingehalten werden. Bei der Verwendung von „begin…“ ist unbedingt erforderlich, innerhalb des Transaktionsblockes auftretende Exceptions zu behandeln. Außerdem muss an bestimmten Programmstellen das mögliche Auftreten von Exceptions vermieden werden. Bei geschachtelten Transaktionen ist darauf zu achten, dass der Transaktions-Stack nicht durcheinander kommt, z. B. wenn aus Unachtsamkeit die übergeordnete Transaktion ebenfalls geschlossen wird.
Um die Sicherheit bei „begin…“ zu erhöhen, dass das „rollback“ bzw. „commit“ sich auf die richtige Transaktion bezieht, kann man die Transaktions-GUID benutzen. „beginNew()/begin()“ gibt als Rückgabewert die GUID der aktuellen Transaktion zurück, die man bei „rollback()“ und „commit()“ als Parameter übergeben kann. Stimmt diese bei „commit()“ nicht mit der aktuellen Transaktion überein, dann entsteht eine Exception und es wird nicht die falsche Transaktion persistent gemacht.
Bei „rollback()“ wird nur eine Warnung ausgegeben, dass die Transaktions-GUIDs nicht übereinstimmen. Jede Top-Level-Transaktion hat eine eigene Transaktions-GUID, während Sub-Level-Transaktionen die Transaktions-GUID der Top-Level-Transaktion liefern. Die Verwendung der Transaktions-GUID schützt vor dem unbeabsichtigten Schließen der falschen Top-Level-Transaktion, bei den Subtranskationen sind solche Fehler noch möglich. In einem späteren Release kann dieser Schutzmechanismus auch auf die Subtransaktionen ausgedehnt werden, sodass jede Subtransaktion eine eigene Transaktions-GUID besitzt. Deswegen sollte man auch für die Subtransaktionen die Transaktions-GUID verwenden.
6.3.5.1 Lesende Transaktion mit begin…
Eine lesende Transaktion mit „begin…“ hat immer der nachstehenden Vorlage zu entsprechen. Dabei darf an den mit /*xx*/ markierten Stellen keine Exception ausgelöst werden. Das bedeutet, dass an diesen Stellen am besten kein Code steht oder nur Anweisungen, die keine Exception auslösen können. Eine ausschließlich lesende Transaktion sollte immer mit „rollback()“ zurückgesetzt werden, da keine Änderungen auf der Datenbank vorgenommen werden. Der try-finally-Block sorgt dafür, dass auf jeden Fall „rollback()“ ausgeführt wird, unabhängig davon, ob innerhalb des Transaktionsblockes eine Exception auftritt oder nicht.
Vorlage für eine lesende Transaktion:
byte[] transGuid= tm.begin…(..);
/*xx*/
try {
…
} finally {
/*xx*/
tm.rollback(transGuid);
…
}
Eine Exception an den markierten Stellen würde zur Folge haben, dass die Transaktion nicht durch das „rollback()“ zurückgesetzt wird. Die Transaktion wäre offen und wird erst beim nächsten auftretenden, für eine andere Transaktion bestimmten „commit()“ oder „rollback()“ geschlossen werden. Der Transaktions-Stack wäre nicht mehr konsistent und das hätte den Datenverlust zur Folge.
Prüfen Sie bei lesenden Transaktionen, ob Sie „beginReadOnly()“ zum Öffnen einer Read-Only-Transaktion verwenden können.
6.3.5.2 Lesende Transaktion mit create…
Eine lesende Transaktion mit „create…“ hat immer der nachstehenden Vorlage zu entsprechen. Das Ergebnis von „create…“ muss wie folgt im „try“ einer Variablen zugewiesen werden, da ansonsten die Transaktion nicht geschlossen wird.
Vorlage für eine lesende Transaktion:
try (CisTransaction txn=tm.create…(…)) {
…
}
6.3.5.3 Schreibende Transaktion mit begin…
Eine schreibende Transaktion mit „begin…“ hat immer der nachstehenden Vorlage zu entsprechen. Dabei darf an den mit /*xx*/ markierten Stellen keine Exception ausgelöst werden. D. h., an diesen Stellen steht kein Code oder stehen nur Anweisungen, die keine Exception auslösen können. Eine schreibende Transaktion muss entweder mit „rollback()“ abgebrochen oder mit „commit()“ erfolgreich beendet werden. Im Falle eines Abbruches werden alle in der Transaktion bzw. in Subtransaktionen gemachten Änderungen verworfen. Lesende und ändernde Zugriffe über den Persistenzdienst sind erlaubt. Der try-catch-Block sorgt dafür, dass bei einer Exception im Transaktionsblock die Transaktion explizit mit „rollback()“ abgebrochen wird. Ansonsten wird die Transaktion mit „commit()“ erfolgreich beendet.
Vorlage für eine schreibende Transaktion:
byte[] transGuid= tm.begin…(..);
/*xx*1/
try {
…
tm.commit(transGuid);
/*xx*2/
} catch (RuntimeException ex) {
/*xx*3/
tm.rollback(transGuid);
…
}
Eine Exception an der Stelle /*xx*1/ würde dazu führen, dass die geöffnete Transaktion nicht über eine zum Block gehörende Anweisung geschlossen wird. Eine Exception an der Stelle /*xx*2/ würde dazu führen, dass das „rollback()“ im catch-Block ausgeführt wird, welches die übergeordnete Transaktion abbrechen würde. Die aktuelle Transaktion wurde schon mit „commit()“ geschlossen. Eine Exception an der Stelle /*xx*3/ führt dazu, dass das „rollback()“ nicht ausgeführt wird und die Transaktion offen bleibt.
6.3.5.4 Schreibende Transaktion mit create…
Eine schreibende Transaktion, die mit „create…“ geöffnet wurde, hat immer der nachstehenden Vorlage zu entsprechen. Dabei darf an den mit /*xx*/ markierten Stellen kein Zugriff auf den Objekt-Manager erfolgen. Nach dem „commit()“ sollte daher am besten kein Code stehen. Das Ergebnis von „create…“ muss wie folgt im „try“ einer Variablen zugewiesen werden, da ansonsten die Transaktion nicht geschlossen wird.
Vorlage für eine schreibende Transaktion:
try (CisTransaction txn=tm.create…(..)) {
…
txn.commit();
/*xx*/
}
Die mit „create…“ geöffnete Transaktion ist an der Stelle /*xx*/ bereits geschlossen. Der Objekt-Manager verwendet an der Stelle /*xx*/ nicht die im „try“ geöffnete Transaktion.
6.3.5.5 Blockweise schreibende Transaktion mit create…
Eine Transaktion sollte immer eine begrenzte Größe haben. Wenn eine unbegrenzte Menge von Daten geschrieben werden soll, dann sollten diese Daten in Blöcken mit begrenzter Größe geschrieben werden. Die Blockgröße kann entweder konstant vorgegeben werden (z. B. 100 Datensätze pro Transaktion) oder aber dynamisch durch den Transaktions-Manager berechnet werden. Dabei darf an den mit /*xx*/ markierten Stellen kein Zugriff auf den Objekt-Manager erfolgen. Nach dem „commit“ sollte daher am besten kein Code stehen.
Vorlage für eine Transaktion mit festen Blockgrößen mit „commitBlock()“:
try (CisTransaction txn=tm.create…(..)) {
int i=0;
while (…) {
…
om.putObject(o);
if (++i%100=0) {
txn.commitBlock();
}
}
txn.commit();
/*xx*/
}
Vorlage für eine Transaktion mit dynamischer Blockgröße mit „commitIfSizeLimitExceeded()“:
try (CisTransaction txn=tm.create…(..)) {
int i=0;
while (…) {
…
om.putObject(o);
txn.commitIfSizeLimitExceeded();
}
txn.commit();
/*xx*/
}
Die mit „create…“ geöffnete Transaktion ist an der Stelle /*xx*/ bereits geschlossen. Der Objekt-Manager verwendet an der Stelle /*xx*/ nicht die im „try“ geöffnete Transaktion.
6.3.6 Weitere Methoden
6.3.6.1 Methode getComparator()
Die Methode „getComparator()“ liefert einen Komparator für String-Vergleiche. Er verwendet die gleiche Sortierung wie die angegebene Datenbank. Damit kann bei Sortierungen von Zeichenketten im Hauptspeicher, die Datenbanksortierung nachgebildet werden. Der Methode kann ein Datenbank-Alias oder eine Datenbank-GUID übergeben werden, für die der passende Komparator geliefert werden soll. Ist keine Datenbank angegeben, dann wird der Komparator für die aktuelle OLTP-Datenbank der Session zurückgegeben.
Damit der Komparator die Datenbanksortierung nachbilden kann, muss die Sortiertabelle für die Zeichen ermittelt werden. Dazu dient das Tool „Collation prüfen“ (chkcol).
6.3.6.2 Methode buildDatabaseLock()
Durch die Methode „buildDatabaseLock()“ wird ein als Parameter übergebenen Lock-String durch Anhängen der GUID der angegebenen Datenbank datenbank-spezifisch. Dadurch wird der zu setzende logische Lock nur für eine konkrete Datenbank gültig gemacht. Das ist notwendig, wenn z. B. eine Business-Object-Instanz, die auf mehreren OLTP-Datenbanken existiert, geändert werden soll und für den logischen Lock ein Schlüssel des Business Objects als Lock-String verwendet wird. Dann würde diese auf allen Datenbanken gesperrt werden, obwohl die Sperre nur auf Datenbankebene notwendig ist. Der Methode kann der Datenbank-Alias oder die Datenbank-GUID übergeben werden. Ist keine Datenbank angegeben, dann wird die aktuelle OLTP-Datenbank der Session verwendet.
6.3.7 Unterstützung für Massendatenverarbeitung
Schreibende Transaktionen im Persistenzdienst haben eine beschränkte Größe. Die maximale Größe einer Transaktion hängt vom Speicher im Application-Server und von den Grenzen des Datenbank-Management-Systems ab. Daher ist nicht sinnvoll, die Transaktionsgrößen in der Anwendung zu kodieren, da die Transaktionsgrößen somit von technischen Parametern abhängen und nicht fachlich ausgerichtet sind.
Verwenden Sie „commitBlock()“ oder „commitIfSizeLimitExceeded()“, um beschränkte Transaktionsgrößen zu garantieren. Weitere Informationen finden Sie im Kapitel „Blockweise schreibende Transaktion mit create…“.
6.4 Der Object-Manager
Der Object-Manager des Persistenzdienstes bietet einer Anwendung zwei Möglichkeiten des Datenbankzugriffes. Zum einem stellt er Methoden zum Lesen, Erzeugen, Ändern und Löschen auf Ebene der Business Objects zur Verfügung, zum anderen kann die Anwendung über den Persistenzdienst ein beliebiges ERP-System-OQL-Statement ausführen, um Daten zu öffnen oder zu ändern. Der Object-Manager bildet das in einer Anwendung benutzte objektorientierte Datenmodell in das relationale Modell der Datenbank ab. Aus den OQL-Statements werden die benötigten SQL-Anfragen generiert. Das alles geschieht für die Anwendung transparent. Dabei erfolgen alle Datenbankzugriffe in den Anwendungen im Rahmen von Transaktionen, die vom Transaction-Manager geführt werden.
Die für die aktuelle Session gültige Instanz des Object-Managers kann am Session-Environment mithilfe der Methode „getObjectManager()“ abgefragt werden. Der Object-Manager ist die Schnittstelle für Anwendungen, mithilfe derer:
- Business Objects geöffnet bzw. erzeugt werden können
(Methode „getObject()“ , „getObjectArray()“), - Business-Object-Iteratoren zum Lesen erzeugt werden können
(Methode „getObjectIterator()“), - beliebige lesende ERP-System-OQL-Statements (SELECT) ausgeführt werden können
(Methode „getResultSet()“), - Business Objects an der aktuellen Transaktion zum Speichern registriert werden können
(Methode „putObject()“), - Business Objects an der aktuellen Transaktion zum Löschen registriert werden können
(Methode „deleteObject()“), - beliebige schreibende ERP-System-OQL-Statements (UPDATE/INSERT/ DELETE) ausgeführt werden können
(Methode „getUpdateStatement()“).
Alle verwendeten Business Objects werden mithilfe des Object-Managers geöffnet, erzeugt, gespeichert oder gelöscht. Verschiedene Zugriffsmodi können gesetzt und die Inhaltssprache für mehrsprachige Attribute angegeben werden.
6.4.1 Inhaltssprache
Über die Inhaltssprache wird gesteuert, in welcher Sprache die mehrsprachigen Attribute einer Business-Object-Instanz vorliegen sollen, d. h. der Wert eines mehrsprachigen Attributes gilt nur für die angegebene Inhaltssprache. Ist keine Inhaltssprache angegeben, wird die aktuell eingestellte Inhaltssprache des Benutzers verwendet. Die angegebene Inhaltssprache muss auf der Datenbank gemäß deren Konfigurationseinstellungen existieren.
Die Inhaltssprache, in der eine Business-Object-Instanz geöffnet wurde, kann mit der Methode „get_contentLanguage()“ der Business-Object-Klasse abgefragt werden.
6.4.2 Methode getObject()
Mit „getObject()“ kann eine Business-Object-Instanz geöffnet werden. Dabei wird der transaktionslokale Kontext beachtet. Gelesen wird immer die gesamte Instanz mit allen Attributen. Als Parameter wird der aus einem Schlüssel des Business Objects generierte Persistenzdienstschlüssel und optional der Zugriffmodus erwartet. Die Erzeugung des zur Identifikation der zu öffnenden Instanz benötigten Persistenzdienstschlüssels erfolgt mithilfe der entsprechenden statischen Methode der Business-Object-Klasse. Beispielsweise dient zur Generierung des Persistenzdienstschlüssels aus dem Primärschlüssel des Business-Objects die Methode „buildPrimaryKey()“.
Die Methode hat folgende Signaturen:
<T extends CisObject> T getObject(byte[] key);
<T extends CisObject> T getObject(byte[] key, int flags);
<T extends CisObject> T getObject(byte[] key, int flags, String language);
Arbeitsweise
Der Object-Manager versucht zuerst, die Business-Object-Instanz aus dem Transaction-Cache der aktuellen Transaktion zu lesen. Wurde sie dort nicht gefunden, dann wird im „Shared Cache“ gesucht. Wurde sie auch dort nicht gefunden, dann erfolgt der Zugriff auf die Datenbank. Dabei wird die folgende SQL-Abfrage abgesetzt, die eine oder keine Zeile als Ergebnis liefert:
SELECT * FROM table WHERE keyAttributes=’?’
Der Object-Manager erzeugt eine Instanz der Business-Object-Klasse, mappt das Anfrageergebnis auf die Attribute und liefert die Instanz als „CisObject“ an die Anwendung zurück. Dort hat ein „Type-Cast“ von der allgemeinen Klasse „CisObject“ auf die konkrete Klasse des gelesenen Business Objects zu erfolgen. Wurde kein Ergebnis von der Datenbank geliefert, wird „null“ zurückgegeben.
Abhängig von den übergebenen Flags (z. B. READ_WRITE, INSERT, …) können mit „getObject()“ auch neue Business-Object-Instanzen erzeugt werden. Die Attributwerte werden aus dem übergebenen Schlüssel in die Instanz übernommen. Wenn eine Instanz mit dem Business-Key oder einem Sekundarschlüssel erzeugt wird, dann werden die GUID-Attribute aus dem Primärschlüssel mit einer neuen GUID initialisiert.
Beispiele
Der nachstehende Quelltextauszug öffnet eine Instanz des Business Objects „Item“ über den Primärschlüssel:
byte[] guid = …;
byte[] primKey = Item.buildPrimaryKey( guid );
Item item = om.getObject(primKey, CisObjectManager.READ);
Der nächste Quelltextauszug öffnet eine Instanz des Business Objects „Item“
über den fachlichen Schlüssel „number“:
String number = …;
byte[] busKey = Item.buildByNumberKey( number );
Item item = om.getObject(busKey, CisObjectManager.READ);
Zeitabhängigkeit
Zeitabhängige Objekte werden immer mit der aktuell aktiven Version geöffnet. Soll eine andere Version als die aktive geöffnet werden, dann muss der zeitabhängige Schlüssel übergeben werden, der mit der Methode „buildTimeDependentKey()“ erzeugt wird. Als Parameter werden die Primärschlüsselattribute und das „validFrom“-Attribut übergeben:
byte[] guid = …;
Date validFrom = …;
byte[] primKey = Item.buildTimeDependentKey(guid, validFrom);
Item item = om.getObject(primKey, CisObjectManager.READ);
Um die zu einem beliebigen Zeitpunkt gültige Version einer Business-Object-Instanz zu öffnen, muss eine entsprechende OQL-Anfrage mit der Methode „getObjectIterator()“ gestellt werden. Mit der Methode „getObject()“ ist das nicht möglich.
Wenn eine zeitabhängige Business-Object-Instanz mithilfe „getObject()“ erzeugt wird, dann wird das Attribut „validFrom“ auf die Konstante MIN_DATE und das Attribut „validUntil“ auf MAX_DATE gesetzt.
NLS-Unterstützung
Jedes mehrsprachige Attribut der Business-Object-Instanz wird, soweit vorhanden, mit dem Wert der angegebenen Inhaltssprache gefüllt. Entspricht die Inhaltssprache der Hauptsprache der Datenbank, wird der Wert direkt aus der zum Business Object korrespondierenden Tabelle gelesen. Ist die Inhaltssprache eine Nebensprache der Datenbank, dann wird der Wert aus der zum NLS-Objekt korrespondierenden Tabelle gelesen. Liegt zu einer Sprache keine Übersetzung vor, dann wird der Wert für die Hauptsprache zurückgegeben.
Wenn bei „getObject“ als Sprache „null“ übergeben wird, dann wird die Instanz in der Datenbanksprache geöffnet.
Mehrere Datenbankzugriffe sind notwendig, um ein Objekt mit einer Nebensprache zu öffnen, da die Übersetzungen der lokalisierbaren Attribute aus den separaten NLS-Objekten stammen. Wenn der Wert der NLS-Attribute nicht benötigt wird, dann kann das Objekt mit „null“ als Sprache geöffnet werden.
6.4.3 Methode getObjectArray()
Die Methode „getObjectArray()“ öffnet mehrere Instanzen eines Business Objects. Die weiteren Methodenparameter entsprechen denen von „getObject()“. Die Methode „getObjectArray“ hat immer eine kürzere Antwortzeit als der wiederholte Aufruf von „getObject“. Verwenden Sie also wenn möglich „getObjectArray“ statt „getObject“.
Die Signaturen der Methode sind:
CisObject[] getObjectArray(byte[][] primaryKeys, int flags)
CisObject[] getObjectArray(byte[][] primaryKeys, int flags, String language)
CisObject[] getObjectArray(java.util.List primaryKeys, int flags)
CisObject[] getObjectArray(java.util.List primaryKeys, int flags, String language)
Arbeitsweise
Der Object-Manager versucht, die Business-Object-Instanzen aus dem Transaction-Cache zu lesen. Nach den Instanzen, die nicht gefunden wurden, wird im Shared Cache gesucht. Für den Rest, der auch dort nicht gefunden wurde, erfolgt der Zugriff auf die Datenbank. Dabei wird die folgende SQL-Abfrage abgesetzt:
SELECT * FROM table
WHERE primaryKeyAttribute1=? OR … OR primaryKeyAttributeN=?
Der Object-Manager erzeugt die Instanzen der Business-Object-Klasse, mappt das Anfrageergebnis auf die Attribute und liefert die Instanzen als „CisObject-Array“ an die Anwendung zurück. Dort hat ein „Type-Cast“ von der allgemeinen Klasse „CisObject“ auf die konkrete Klasse der gelesenen Business Objects zu erfolgen. Wurde kein Ergebnis gefunden, dann wird ein leeres „CisObject“-Array zurückgegeben.
Beispiel
Der nachstehende Quelltextauszug öffnet Instanzen des Business Objects
„Item“ über die Primärschlüssel:
byte[] primKey1 = Item.buildPrimaryKey( guid1 );
…
byte[] primKeyN = Item.buildPrimaryKey( guidN );
byte[][] primaryKeys = new byte[][]{primKey1, …., primKeyN};
CisObject[] objects = om.getObjectArray(primaryKeys, CisTransactionManager.READ);
for (int i=0; i< objects.length;i++) {
// Position in objects entspricht Position in primaryKeys
Item item = (Item) objects[i];
…
}
Zeitabhängigkeit
Das Verhalten entspricht dem der Methode „getObject()“. Siehe Abschnitt „Zeitabhängigkeit“ im Kapitel „Methode getObject()“.
NLS-Unterstützung
Das Verhalten entspricht dem der Methode „getObject()“. Siehe Abschnitt „Zeitabhängigkeit“ im Kapitel „Methode getObject()“.
6.4.4 Methode getObjectList()
Die Methode „getObjectList()“ liest analog zu „getObjectArray()“ mehrere Instanzen eines Business Objects zu gegebenen Schlüsseln. Die Funktion von „getObjectList()“ und „getObjectArray()“ ist identisch, „getObjectList()“ gibt jedoch eine Liste mit den Business Objects zurück, während „getObjectArray()“ ein Array zurückgibt. Die Größe der Liste entspricht der Anzahl der übergebenen Schlüssel.
Die Signatur der Methode ist:
<T extends CisObject>
List<T> getObjectList(CisList keys, int flags)
Der Datentyp „List“ als Rückgabe erlaubt einen einfachen „Type-Cast“ auf eine Liste mit den tatsächlich geöffneten Business Objects.
Beispiel
Der nachstehende Quelltextauszug öffnet Instanzen des Business Objects
„Item“ über die Primärschlüssel:
CisList primaryKeys = new CisArrayList();
primaryKeys.add(Item.buildPrimaryKey( guid1 ));
…
primaryKeys.add(Item.buildPrimaryKey( guidN ));
List<Item> items = om.getObjectArray(
primaryKeys, CisTransactionManager.READ);
for (Item item : items) {
// Position in items entspricht Position in primaryKeys
…
}
6.4.5 Methode putObject()
Diese Methode registriert eine Business-Object-Instanz zum Speichern im Transaction-Cache der aktuellen Transaktion und lässt dessen geänderte Attribute transaktionsweit (= Subtransaktionen bzw. beim „commit“ der Vater- und somit allen Brudertransaktionen) sichtbar werden. Damit wird das Objekt im aktuellen transaktionslokalem Kontext sichtbar.
Die Signatur der Methode ist:
void putObject(CisObject obj)
Arbeitsweise
Um eine Instanz eines Business Objects zu erzeugen oder zu ändern, muss zuerst eine Top-Level-Transaktion geöffnet werden. Dann wird die Instanz mit „getObject()“/„getObjectArray()“ unter Angabe des gewünschten Zugriffsmodus geöffnet.
Der Zugriffsmodus READ_UPDATE liefert Instanzen, die beliebig geändert oder gelöscht werden können. Der Zugriffsmodus READ_WRITE erzeugt eine neue Business-Object-Instanz, wenn das Objekt bisher noch nicht existiert hat. READ_UPDATE liefert in diesem Fall „null“.
Die gelesene Business-Object-Instanz ist für andere Transaktionen durch den Persistenzdienst gesperrt. Will eine andere Transaktion dieselbe Business-Object-Instanz lesen, entsteht nach einer gewissen Wartezeit eine Timeout-Exception.
Die Änderungen an den Attributen erfolgen über die „set…()“-Methoden der Business-Object-Klasse. Der Aufruf von „putObject()“ mit der Business-Object-Instanz als Parameter übernimmt die Änderungen in den aktuellen Transaction-Cache.
Die Business-Object-Instanz, welche „putObject“ übergeben wurde, ist nach dem Aufruf von „putObject()“ ungültig und darf nicht mehr verwendet werden. Ein erneutes „getObject()“ innerhalb der Transaktion liefert die geänderte Business-Object-Instanz.
Beim „commit()“ der Transaktion werden nur die registrierten Änderungen berücksichtigt. Die Ausführung der Datenbankoperation, um die registrierten Änderungen persistent auf der Datenbank zu machen, erfolgt erst beim „commit()“ der Top-Level-Transaktion.
Wenn das Business Object Update-Informationen (Attribut UpdateInformation) enthält, dann werden bei diesem Aufruf der Zeitpunkt und der Änderer der letzten Änderung aktualisiert.
Beispiel
Der nachstehende Quelltextauszug öffnet eine Instanz des Business Objects „UnitOfMeasure“ von der Datenbank oder erzeugt eine neue Instanz:
try (CisTransaction txn = tm.createNew()) {
byte[] key = UnitOfMeasure.buildByCodeKey(code);
// Laden der Instanz zum Ändern/Anlegen
UnitOfMeasure unitOfMeasure = om.getObject(key,
CisObjectManager.READ_WRITE);
if (unitOfMeasure.is_newObject() ) {
// create
} else {
// update
}
// Setzen der Attribute
unitOfMeasure.setDescription(description);
…
// Registrieren der Änderungen im Transaction-Cache
om.putObject(unitOfMeasure);
// Beenden der Transaktion, Schreiben der Änderungen
txn.commit() ;
}
State-Objekte
Jede geänderte Business-Object-Instanz besitzt ein oder mehrere State-Objekte, das die eigentlichen Attributwerte aufnimmt. Bei Attributänderungen wird – soweit noch nicht vorhanden – in dem transakionslokalem Kontext ein neues State-Objekt erzeugt, das die in diesem Kontext gültigen Attribute enthält. Die State-Objekte sind transaktionsspezifisch und werden erst beim
„commit“ in die Parent-Transaktion übernommen.
Zeitabhängigkeit
Zeitabhängige Instanzen werden abhängig von den Werten der Attribute
„validFrom“ und „validUntil“ behandelt:
- Wenn „validFrom“ „null“ ist, dann wird „validFrom“ auf den aktuellen Zeitpunkt gesetzt.
- Wenn das Attribut „validUntil“ auf „null“ gesetzt wird, wird beim „putObject“ dieses Attribut auf das „validFrom“ der Folgeversion gesetzt. Wenn keine Folgeversion existiert, wird „validUntil“ auf MAX_DATE gesetzt.
Das Attribut „validUntil“ der Vorgängerversion wird auf das „validFrom“ des geänderten Objekts gesetzt.
Weitere Informationen finden Sie im Kapitel 5.1.6 Zeitabhängigkeit.
NLS-Unterstützung
Beim Erzeugen einer Business-Object-Instanz werden, unabhängig von der angegebenen Inhaltssprache, alle Nebenspracheneinträge in der zum mehrsprachigen Attribut gehörenden NLS-Tabelle erzeugt. Der Attributwert wird sowohl in die Hauptsprache als auch in die Nebensprachen übernommen.
Bei einer Änderung der Business-Object-Instanz wird der gesetzte Wert für ein mehrsprachiges Attribut in der angegebenen Inhaltssprache auf der Datenbank gespeichert. Ist die Inhaltssprache die Hauptsprache der Datenbank, wird der Wert direkt in der zum Business Object korrespondierenden Tabelle gespeichert. Ist es eine Nebensprache, wird der Wert in der zum NLS-Tabelle gespeichert.
6.4.6 Methode deleteObject()
Die Methode „deleteObject()“ registriert eine Business-Object-Instanz zum Löschen im Transaction-Cache der aktuellen Transaktion. Damit wird sie aus dem aktuellen transaktionslokalem Kontext entfernt. Die Signatur der Methode ist:
void deleteObject(CisObject obj)
Arbeitsweise
Um ein Instanz zu löschen, muss zuerst eine Top-Level-Transaktion geöffnet werden. Dann wird das zu ändernde Business Object mit „getObject()“ unter Angabe des Zugriffsmodus READ_UPDATE geöffnet. Der Aufruf von „deleteObject()“ mit der Business-Object-Instanz als Parameter markiert, setzt die Instanz im aktuellen Transaktion-Cache zum Löschen. Beim „commit“ der Top-Level-Transaktion wird die zum Löschen registrierte Business-Object-Instanz auf der Datenbank gelöscht.
Nachdem eine Business-Object-Instanz mit „deleteObject()“ gelöscht wurde, ist die geöffnete Instanz ungültig und darf nicht mehr verwendet werden. Ein erneutes Lesen derselben Business-Object-Instanz mit dem Zugriffsmodus READ-UPDATE liefert nun „null“. Wenn in der gleichen Transaktion (bzw. deren Subtransaktionen), in der eine Instanz gelöscht wurde, die gelöschte Instanz mit READ_WRITE erneut gelesen wird, dann wird vom Persistenzdienst kein neues Objekt erzeugt, sondern der Inhalt der vorher gelöschten Instanz zurückgegeben.
Beispiel
Der nachstehende Quelltextauszug öffnet eine Instanz des Business Objects „UnitOfMeasure“ von der Datenbank. Eine gefundene Instanz wird zum Löschen markiert. Beim „commit“ wird die Instanz gelöscht.
try (CisTransaction txn = tm.beginNew()) {
byte[] key = UnitOfMeasure.buildByCodeKey(code);
// Laden der Instanz zum Ändern/Anlegen
UnitOfMeasure unitOfMeasure = (UnitOfMeasure) om.getObject(key,
CisObjectManager.READ_UPDATE);
if (unitOfMeasure==null) {
// nicht gefunden
…
} else {
// Markieren zum Löschen
om.deleteObject(unitOfMeasure);
}
// Beenden der Transaktion, Schreiben der Änderungen
txn.commit();
Zeitabhängigkeit
Bei Löschung einer zeitabhängigen Version einer Business-Object-Instanz steuert der Wert des Attributes „validUntil“, ob die entstandene Lücke in der Versionskette geschlossen wird.
Ist der Wert „null“, wird der Gültigkeitszeitraum der Vorgängerversion durch den Gültigkeitszeitraum der gelöschten Version erweitert. Die Vorgängerversion ist damit so lange gültig, wie die gelöschte Version (Übernahme des Wertes aus „validUntil“ der gelöschten Version in die Vorgängerversion).
Ist der Wert nicht „null“, dann wird die angegebene Version gelöscht und eine Lücke bleibt gegebenenfalls in der Versionskette.
Weitere Informationen finden Sie im Kapitel 5.1.6 Zeitabhängigkeit.
NLS-Unterstützung
Bei Löschung einer Business-Object-Instanz mit mehrsprachigen Attributen werden auch die zugehörigen Einträge der Nebensprachen aus den NLS-Tabellen entfernt.
6.4.7 Methode getObjectIterator()
Mit der Methode „getObjectIterator()“ kann eine Menge von Business-Object-Instanzen geöffnet werden. Dazu liefert die Methode einen Iterator über die Ergebnismenge der angegebenen OQL-Anfrage zurück. Als Parameter wird das OQL-SELECT-Statement und optional der Zugriffmodus erwartet. Zusätzlich ist wie bei „getObject()“ die Inhaltssprache für die zu öffnenden Instanzen angebbar.
Die Methode hat folgende Signaturen:
<T extends CisObject> CisObjectIterator<T> getObjectIterator(
String oqlString)
<T extends CisObject> CisObjectIterator<T> getObjectIterator(
String oqlString, int flags)
<T extends CisObject> CisObjectIterator<T> getObjectIterator(
String oqlString, int flags, String language)
Im OQL-Statement ist die Verwendung von Sub-Selects in der WHERE-Klausel erlaubt. Joins werden nicht unterstützt.
Arbeitsweise
Die Methode „getObjectIterator()“ liefert den Iterator zurück, der in der Anwendung zum Öffnen der Business-Object-Instanzen benutzt wird. Als nächstes werden die Werte der Selektionsparameter gesetzt, welche im OQL-Statement durch den Platzhalter „?“ angegeben wurden. Der erste Aufruf von „hasNext()“ bzw. „next()“ am Iterator löst den Datenbankzugriff aus. Die Methode „hasNext()“ prüft, ob noch Instanzen geliefert werden können. Die Methode „next()“ liefert die nächste Instanz an die Anwendung. Wird das Business Object im Shared Cache zwischengespeichert, werden als erstes die Primärschlüsselwerte geöffnet:
SELECT primkeyAttr FROM table [WHERE …]
Die Erzeugung der Business-Object-Instanzen geschieht mithilfe der intern aufgerufenen „getObjectArray()“-Methode, die über die Primärschlüssel die Instanzen blockweise öffnet. Die Standard-Blockgröße ist 16. Ist eine Business-Object-Instanz im aktuellen Transaction-Cache als gelöscht gekennzeichnet, dann wird sie weggefiltert und nicht zurückgegeben. Der Object-Iterator gibt nie „null“ zurück. In der Anwendung hat ein „Type-Cast“ von der allgemeinen Klasse „CisObject“ auf die konkrete Klasse der gelesenen Business Objects zu erfolgen.
Wird das Business Object nicht im Shared Cache zwischengespeichert, dann werden direkt alle Attribute von der Datenbank gelesen und die Instanzen des Business Objects erzeugt. Wenn das Flag BYPASS_CACHE bei „getObjectIterator()“ angegeben wird, dann werden die Instanzen ebenfalls vollständig von der Datenbank geöffnet, als ob das Business Object nicht zwischengespeichert wird.
Wenn ein Object-Iterator mit den Flags READ_UPDATE oder READ_WRITE verwendet wird, dann werden immer nur die Primärschlüssel von der Datenbank gelesen und die Objekte mit „getObjectArray()“ geöffnet.
Beispiel
Der nachstehende Quelltextauszug öffnet die Instanzen des Business Objects „Item“, denen eine bestimmte Maßeinheit (Business Object „UnitOfMeasure“) zugeordnet ist. Deren Primärschlüssel vom Typ „GUID“ wird als Parameter am Iterator über die „setGuid()“-Methode gesetzt, welche als Parameter die Position im OQL-Statement und der Wert übergeben werden.
Beispiel mit OQL-Parameter:
byte[] uomGuid = … ;
try (CisObjectIterator<Item> iter = om.getObjectIterator(
“SELECT FROM com.cisag.app.general.obj.Item i WHERE i:uom=?”)
) {
iter.setGuid(1, uomGuid);
while (iter.hasNext() ) {
Item item = (Item) iter.next() ;
…
}
}
Anmerkung
Die Berechnung des Ergebnisses des OQL-Ausdruckes erfolgt direkt auf den Daten in der Datenbank, der Transaction-Cache wird nicht berücksichtigt. Im selben Transaktionskontext geänderte Objekte bleiben dadurch unberücksichtigt, da diese Änderungen noch nicht in der Datenbank gespeichert sind. Diese werden erst mit Abschluss der Top-Level-Transaktion persistent. Das bedeutet, dass der Objekt-Iterator eventuell falsche Daten liefern kann, wenn von dessen OQL-Statement auch geänderte Objekte betroffen sind. Neu erzeugte Objekte kann er aufgrund des Funktionsprinzips nicht berücksichtigen, gelöschte Objekte kann er anhand des Primärschlüssels herausfiltern.
Dieses Verhalten muss bei der Verwendung von „getObjectIterator()“ in ändernden Transaktionen unbedingt berücksichtigt werden.
Zeitabhängigkeit
Wird bei zeitabhängigen Business Objects weder „validFrom“ noch „validUntil“ in dem OQL-Statement benutzt, dann werden nur die aktuell gültigen Instanzen zurückgegeben. Wenn „validFrom“ oder „validUntil“ in irgendeinem Teil des OQL-Statements benutzt wird, dann werden alle verfügbaren Versionen, auf die die Bedingung des OQL-Statements zutrifft, zurückgegeben.
NLS-Unterstützung
Das Verhalten entspricht dem von der Methode „getObject()“.Siehe Abschnitt „Zeitabhängigkeit“ im Kapitel „Methode getObject()“.
6.4.8 Methode getResultSet()
Mit der Methode „getResultSet()“ können Attribute von Business Objects über ein OQL-SELECT-Statement gelesen werden. Die Ergebnisattribute sind über das SELECT-Statement in OQL beliebig zusammenstellbar. Dabei werden keine kompletten Business-Object-Instanzen von der Datenbank gelesen. Ein Result-Set ist an die aktuelle Transaktion gebunden. Im OQL-String sind Joins und Sub-Selects erlaubt.
Solange ein Result-Set nicht geschlossen wurde, wird exklusiv eine Datenbankverbindung belegt. Erst das Schließen des Result-Sets gibt die Datenbankverbindung wieder frei. Ein „rollback()“- bzw. „commit()“-Kommando schließt implizit alle Result-Sets der zugehörigen Transaktion. Wird ein Result-Set innerhalb der Dummy-Transaktion benutzt, muss das Schließen vom Entwickler sichergestellt werden. Die Verwendung eines Result-Sets sollte immer innerhalb eines „try/catch“-Blockes erfolgen. Im „finally“-Block wird das Result-Set explizit mit der Methode „close()“ geschlossen.
Wichtig ist, die Zeitdauer, in der ein Result-Set geöffnet ist, zu minimieren, da die Anzahl der verfügbaren Datenbankverbindungen begrenzt sind. Aufwendige oder langwierige Operationen sollten erst nach dem Schließen des Result-Sets ausgeführt werden. Wichtig ist auch, dass geschachtelte Result-Sets jeweils eine eigene Datenbankverbindung verwenden. Damit begrenzt die Anzahl der verfügbaren Datenbankverbindungen die Schachtelungstiefe. Aus diesem Grund sollte die Schachtelungstiefe klein gehalten werden.
Die Signaturen der Methode sind:
CisResultSet getResultSet(String oqlString)
CisResultSet getResultSet(String oqlString, int flags)
CisResultSet getResultSet(String oqlString, int flags, String language)
Arbeitsweise
Die Methode „getResultSet()“ liefert ein Result-Set, an dem satzweise die Ergebnismenge abgefragt werden kann. Das als Parameter übergebene OQL-Statement kann Platzhalter („?“) für Werte enthalten, die vor Ausführung der Abfrage mit den entsprechenden Selektionswerten zu belegen sind. Dazu dient die dem Datentyp des Selektionsparameters entsprechende „set…()“-Methode, der als Parameter der Selektionswert und die Selektionsparameter-Nummer übergeben werden. Die Nummerierung der Selektionsparameter ist implizit durch ihre Position (von links) im OQL-Statement festgelegt. Die Auswertung der Anfrage durch die Datenbank erfolgt bei der Abfrage des ersten Ergebnissatzes über die Methode „next()“.
Anschließend können die Attributwerte für diesen Satz über die dem Datentyp entsprechende „get…()“-Methode abgefragt werden. Als Parameter wird der „get…()“-Methode eine Attributnummer übergeben. Diese wird durch die Reihenfolge der Ergebnisattribute in der SELECT-Klausel (von links) bestimmt. Die Existenz des nächsten Ergebnissatzes kann mit der Methode „hasNext()“ geprüft werden. Existieren weitere Sätze, dann liefert der erneute Aufruf der Methode „next()“ den nächsten Satz. Die Anwendung muss die Attribute des gelesenen Satzes vom Result-Set mit der jeweilig richtigen Methode (abhängig vom Datentyp) abholen. Nach dem Lesen der Daten muss sichergestellt sein, dass das Result-Set geschlossen wird.
Beispiel
Der nachstehende Quelltextauszug öffnet nur die Attribute „guid“ (Primärschlüssel) und „number“ (fachlicher Schlüssel) der Instanzen des Business Objects „Item“, denen eine bestimmte Maßeinheit (Business Object „UnitOfMeasure“) zugeordnet ist. Deren Primärschlüssel vom Typ „GUID“ wird als Parameter am Result-Set über die „setGuid()“-Methode (passend zum Typ) gesetzt, welcher als Parameter die Position im OQL-Statement und der Wert übergeben werden. Der „try-catch-finally“-Block stellt sicher, dass das Result-Set geschlossen wird, auch wenn eine Exception auftritt.
byte[] uomGuid = … ;
try (CisResultSet rs = om.getResultSet(“SELECT i:guid, i:number
FROM com.cisag.app.general.obj.Item i
WHERE i:uom=?”)) {
rs.setGuid(1, uomGuid);
while (rs.next() ) {
// read next
byte[] guid = rs.getGuid(1);
String number = rs.getString(2);
…
}
Anmerkung
Das Result-Set wird immer auf der Datenbank ausgewertet, der Transaktions-Cache wird nicht berücksichtigt. Änderungen, die im Transaktions-Cache sind, haben ebenso wie bei „getObjectIterator()“ keine Auswirkung auf die Auswahl der zurückgegebenen Werte. Das muss bei der Verwendung von „getResultSet()“ in ändernden Transaktionen unbedingt berücksichtigt werden.
Zeitabhängigkeit
Wird von einem zeitabhängigen Business Object weder das Attribut „validFrom“ noch „validUntil“ in dem OQL-Statement benutzt, dann werden nur die aktuell gültigen Versionen bei der Auswertung des OQL-Statements betrachtet. Wird das Attribut „validFrom“ oder „validUntil“ des Business Objects in irgendeinem Teil des OQL-Statements benutzt, dann werden alle verfügbaren Versionen in die Abfrage einbezogen.
NLS-Unterstützung
Das Result-Set bietet NLS-Unterstützung für mehrsprachige Attribute. Ist die angegebene Inhaltssprache die Hauptsprache der Datenbank, dann werden die Attributwerte aus den Tabellen der zugehörigen Business Objects gelesen. Ist eine Nebensprache betroffen, dann wird das OQL-Statement um die entsprechenden Inner-Joins zu den NLS-Objekten der mehrsprachigen Attribute erweitert. Der Wert eines mehrsprachigen Attributes wird aus der NLS-Tabelle für die angegebene Inhaltssprache gelesen.
6.4.9 Methode getUpdateStatement()
Mithilfe von OQL können UPDATE-, INSERT- oder DELETE-Statements ausgeführt werden. Damit können mehrere Business-Object-Instanzen mit einem Befehl geändert, einfügt oder gelöscht werden.
Ein Update-Statement wird erst beim „commit“ der Top-Level-Transaktion ausgeführt. Vorher hat das Update-Statement auf die in der Transaktion zu öffnenden Daten keinen Effekt. Wenn man ein Business Object über ein Update-Statement ändert, erzeugt oder löscht und es in der gleichen Transaktion auch mit den Methoden putObject oder deleteObject modifiziert, dann führt das zu einem Fehler. Ein Update-Statement sperrt die gesamte Tabelle auf der das Statement arbeitet, keine andere Transaktion kann eine Business-Object-Instanz dieses Typs öffnen. Wenn ein Business Object mit einem Update-Statement verändert wird, müssen also alle anderen Sessions, die Instanzen des gleichen Business Objects ändern wollen, auf den Abschluss der Transaktion mit dem Update-Statement warten. Die Verwendung von Update-Statements kann somit verhindern, dass eine Anwendung skaliert.
Ein Update-Statement darf keine Primärschlüssel-Attribute ändern.
Die Leistung z B. beim Löschen von vielen Datensätzen, ist mit einem OQL-Delete deutlich höher als über den Persistenzdienst. Jedoch hat die Benutzung von Update-Statements ernste Einflüsse auf die Gesamtleistung des Systems. Nach der Benutzung eines Update-Statements werden alle Instanzen dieses Business Objects auf dieser Datenbank aus allen Shared Caches im gesamten System entfernt. Hängen andere Anwendungen davon ab, dass die Instanzen zu diesem Business Object im Cache gehalten werden, so vermindert sich deutlich die Leistung.
Weder der Workflow noch das Änderungsjournal werden benachrichtigt, wenn Business-Object-Instanzen durch Update-Statements geändert, gelöscht oder erzeugt werden. Die Update-Information wird bei durch Update-Statements erzeugten und geänderten Business-Object-Instanzen nicht aktualisiert.
Update-Statements eignen sich primär für die folgenden Anwendungsfälle:
- Löschen temporärer Daten
- Reorganisationen
Beispiel
try (CisTransaction txn=tm.create()) {
CisUpdateStatement s = om.getUpdateStatement(“DELETE FROM com.cisag.sys.tools.testsuite.obj.SimpleMasterData a WHERE a:code like ?”);
s.setString(1,’001%’);
om.putUpdateStatement(s);
txn.commit() ;
}
NLS-Unterstützung
Update-Statements unterstützen keine mehrsprachigen Attribute. Werden diese in einem Update-Statement verwendet, dann wird immer die Hauptsprache der Datenbank als Inhaltssprache verwendet. Die NLS-Tabellen werden nicht berücksichtigt, deshalb dürfen in INSERT-Statements keine Daten in die Tabellen von Business Objects mit mehrsprachigen Attributen eingefügt werden. Ansonsten würden die Einträge für die Nebensprachen in den NLS-Tabellen der Attribute fehlen.
Zeitabhängigkeit
Update-Statements unterstützen keine Zeitabhängigkeit. Werden in Update-Statements zeitabhängige Business Objects verwendet, dann werden unabhängig von der Verwendung von „validFrom“ und „validUntil“ stets alle Versionen behandelt und nicht nur die aktuell gültige Version. Falls nur die aktuell gültige Version ausgewählt werden soll, muss die Selektion entsprechend eingeschränkt werden.
6.4.10 Vor- und Nachteile der Zugriffsmethoden
In diesem Abschnitt werden einige Richtlinien für die Benutzung der vorgestellten Methoden gegeben, um eine gute Leistung zu erreichen.
Die Methode „getObjectArray()“ (ArrayFetch) ist niemals langsamer als n mal die Methode „getObject()“ auszuführen, aber oftmals schneller. Sie benötigt maximal eine Datenbank-Anfrage im Gegensatz zu maximal n Datenbank-Anfragen.
Ein weiterer Vorteil ist, dass das Attribut-Mapping zwischen den OQL-, SQL- und Java-Attributen nur einmal ermittelt werden muss. Ist für das zu öffnende Business Object eine Cache-Strategie eingestellt, dann lesen die Methoden „getObject()“, „getObjectArray()“ und „getObjectIterator()“ immer zuerst im Shared Cache. Sie fügen die von der Datenbank geöffneten Instanzen auch in den Cache ein. Für häufig benutzte Business Objects (z. B. Stammdaten) sind diese Methoden zweckmäßig, da sie den Cache beim Zugriff beachten.
Hingegen schlecht geeignet sind sie für Massendatenoperationen auf Bewegungsdaten (z. B. Verfügbarkeitsabfrage über Artikel), da diese möglicherweise andere häufig benutzten Daten aus dem Shared Cache verdrängen, obwohl die neu eingelagerten Daten kaum wieder gebraucht werden. Ein weiterer Nachteil ist, dass diese Methoden viele nur temporär benötigte Java-Objekte erzeugen, was Zeit und Hauptspeicherplatz kostet.
Mit der Methode „getResultSet()“ ist möglich, gezielt nur die Attribute zu öffnen, die man benötigt und nicht die ganze Business-Object-Instanz mit vielleicht dutzenden Attributen. Das reduziert die zu übertragenden Daten und damit werden auch weniger Objekte in Java erzeugt. Bei der Verwendung von „getResultSet()“ hat der Entwickler eine höhere Verantwortung, da ein offenes Result-Set exklusiv eine Datenbankverbindung belegt. Weiterhin muss man sich selbst um das Mapping von den Result-Set-Ergebnissen auf die Java-Attribute kümmern.
6.4.11 Zugriffsmodi
Die Art des Zugriffes auf Business Objects wird über den Zugriffmodus gesteuert. Ist kein Zugriffmodus angegeben, wird der Standard-Zugriffsmodus READ verwendet.
| Zugriffsmodus | Bedeutung |
| READ | Die Business-Object-Instanz wird gelesen, kann aber nicht geändert werden. Wurde die Instanz nicht gefunden, wird „null“ zurückgeliefert. |
| READ_UPDATE | Die Business-Object-Instanz wird zum Ändern gelesen und darf beliebig geändert bzw. gelöscht werden. Wurde die Instanz nicht gefunden, wird „null“ zurückgeliefert. |
| READ_WRITE | Wie Zugriffssmodus READ_UPDATE. Aber: Existiert die Instanz, auf welche zugegriffen werden soll nicht, wird eine neue Instanz zurückgegeben.
Enthält die neue Instanz das Attribut „UpdateInformation“, dann wird der Zeitpunkt der Erzeugung und der Benutzer in der „UpdateInformation“ eingetragen. Wenn die Instanz über einen Sekundärschlüssel neu erzeugt wird, werden alle Primärschlüsselattribute vom Typ „GUID“ mit einer neuen GUID initialisiert. |
| READ_REPEATABLE | Der Zugriffsmodus setzt explizit eine Lesesperre auf eine Business-Object-Instanz und stellt sicher, dass diese nicht von anderen Transaktionen geändert werden kann. Dabei wird sichergestellt, dass die Instanz im Cache mit den Daten auf der Datenbank übereinstimmt.
Damit liefert der Zugriffsmodus garantiert konsistente Daten, auch wenn mehrere Application-Server auf der OLTP-Datenbank arbeiten. Beim normalen READ ist es anders, da der Cache-Abgleich zwischen den Servern alle 30 Sekunden erfolgt und eine Business-Object-Instanz mit veralteten Attributwerten im Cache stehen kann. |
| READ_PARALLEL | Dieser Zugriffsmodus ist nützlich, wenn man aus einer anderen Transaktion heraus, die Dummy-Transaktion zum Lesen benutzen möchte.
Damit ist möglich, die Gültigkeit von Objekt-Iteratoren und Result-Sets an die Dummy-Transaktion zu binden und nicht an die aktuelle Transaktion. Auf der Datenbank muss die Dummy-Transaktion offen sein. Deshalb funktioniert diese Option nur auf der dem Benutzer zugeordneten OLTP-Datenbank. |
| INSERT | Wenn eine Business-Object-Instanz neu erzeugt werden soll und durch die Programmlogik bekannt ist, dass die Instanz noch nicht existiert, dann ist unnötig, dass der Persistenzdienst die Existenz auf der Datenbank prüft.
Dieser Zugriffsmodus schaltet die Existenzprüfung ab und erzeugt unabhängig vom Datenbankinhalt eine neue, nicht persistente Business-Object-Instanz. Falls die Instanz entgegen der Annahme dennoch existiert, dann gibt es einen Fehler beim „commit“ der Top-Level-Transaktion. |
| INSERT_DIRTY | Dieser Zugriffsmodus verhält sich wie INSERT, aber das „Locking“ ist abgeschaltet. Dadurch werden keine Cache-Listener benachrichtigt bzw. Workflow-Ereignisse ausgelöst.
Dieser Modus sollte nicht für zeitabhängige Business Objects und für Business Objects mit der Cache-Strategie „Alle Instanzen beim ersten Zugriff öffnen“ benutzt werden. INSERT_DIRTY ist daher nur für temporäre Daten sinnvoll. |
| NEW_VERSION | Mit diesem Zugriffsmodus wird immer eine neue leere Version einer Business-Object-Instanz erzeugt, ohne den Cache oder die Datenbank zu berücksichtigen. Diese Option ist nur im Insert-Only-Modus bei zeitabhängigen Objekten sinnvoll verwendbar. |
Die aufgeführten Zugriffsmodi können durch weitere Flags modifiziert werden. Dazu sind die entsprechenden Konstanten mit der binären UND-Operation zu verknüpfen.
| Flag | Bedeutung |
| DISABLE_LOCKING | In diesem Zugriffsmodus ist das „Locking“ abgeschaltet. Das Flag sollte im Allgemeinen nicht verwendet werden, da ansonsten die Daten durch die fehlenden Sperren inkonsistent werden können. |
| NO_PUT_SHARED_CACHE | Die Business-Object-Instanz wird nicht im Shared Cache abgelegt. |
| CACHE_ONLY | Die Business-Object-Instanz wird nur im Shared Cache gesucht. Ist sie dort nicht vorhanden, dann wird „null“ zurückgegeben, auch wenn sie in der Datenbank vorhanden ist. Dieser Zugriffsmodus sollte nicht verwendet werden, da das Ergebnis im Allgemeinen nicht deterministisch ist. |
| BYPASS_CACHE | Die Business-Object-Instanz wird direkt aus der Datenbank gelesen. Sowohl der Shared Cache als auch der transaktionslokale Cache wird hierbei ignoriert. Ist eine Cache-Strategie für das Business Object eingestellt, dann wird die Instanz in den Cache aufgenommen. Dieser Zugriffsmodus steigert die Leistung für Objekt-Iteratoren, wenn sich die Mehrheit der zu öffnenden Instanzen nicht im Shared Cache befindet. |
| IGNORE_SHARED_CACHE | Der Zugriffsmodus bewirkt dasselbe wie BYPASS_CACHE, nur die Business-Object-Instanz wird nach dem Lesen nicht im Shared Cache abgelegt. Damit wird verhindert, dass ein gelesenes Objekt wichtigere Objekte im Cache verdrängt. |
6.5 Arbeitsweise des Zugriffs auf Business Objects
Nachfolgend wird die Arbeitsweise des Persistenzdienstes beim Öffnen und Speichern von Business-Object-Instanzen in Transaktionen erläutert.
6.5.1 Lesender Zugriff
Beim lesenden Zugriff auf eine Business-Object-Instanz wird diese zunächst im Transaction-Cache gesucht. Die Änderungen in der jeweils zuletzt geöffneten Subtransaktion werden zuerst berücksichtigt. Wenn ein Objekt im Transaction-Cache nicht gefunden wurde, dann wird dieses im Shared Cache gesucht. Ist das Objekt auch nicht im Shared Cache, dann wird es in der Datenbank gesucht.
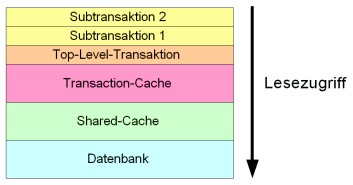
Hierarchie der Caches beim Lesezugriff
6.5.2 Schreibender Zugriff
Beim schreibenden Zugriff werden die Daten beim „commit“ aus dem Transaction-Cache gleichzeitig in den Shared Cache und in die Datenbank geschrieben.
![]()
Ablauf bei „commit“ der Top-Level-Transaktion
6.5.3 State-Objekte
State-Objekte nehmen die Attribute einer Business-Object-Instanz auf. Die Hauptklasse ist eine Hülle (Wrapper), die die Zugriffe auf ihre State-Objekte kapselt. Die State-Objekte bilden gemäß der Schachtelungstiefe der Subtransaktionen eine Kette. Das letzte State-Objekt enthält den Zustand der Business-Object-Instanz. Alle „set()“- und „get()“-Methoden der Business-Object-Klasse rufen entsprechende Methoden des State-Objektes auf.
Bei einer unveränderten Business-Object-Instanz wird beim ersten Ändern eines Attributs ein neues State-Objekt erzeugt. Das neue State-Objekt ist eine Kopie des vorhergehenden State-Objekts mit dem geänderten Attribut.
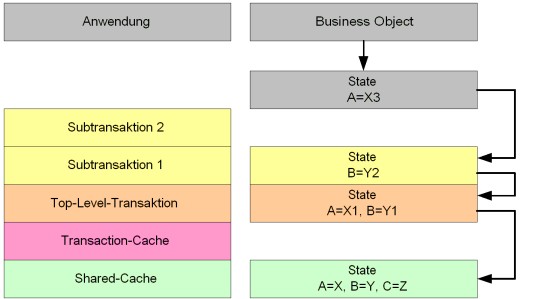
Beispiel für die Verkettung von State-Objekten
In dem obigen Beispiel hat eine Anwendung eine Business-Object-Instanz in der „Subtransaktion 2“ geöffnet, das Attribut A verändert und dadurch ein neues State-Objekt erzeugt, welches den neuen Zustand der Business-Object-Instanz mit dem Wert „X3“ von „A“ enthält. Die Business-Object-Instanz wurde noch nicht zum Speichern registriert und das State-Objekt noch nicht in den Transaction-Cache geschrieben. Das State-Objekt referenziert das State-Objekt in der übergeordneten „Subtransaktion 1“. In dieser wurde das Attribut „B“ der Business-Object-Instanz verändert und der geänderte Zustand wurde in einem State-Objekt gespeichert. Die Business-Object-Instanz wurde in der „Subtransaktion 1“ zum Speichern registriert. Dadurch wird das zugehörige State-Objekt im Transaction-Cache abgelegt. Das State-Objekt referenziert das State-Objekt in der Top-Level-Transaktion. In dieser wurden die Attribute „A“ und „B“ der Business-Object-Instanz geändert und der geänderte Zustand wurde in einem State-Objekt gespeichert. Die Business-Object-Instanz wurde in der Top-Level-Transaktion zum Speichern registriert. Dadurch wird das zugehörige State-Objekt im Transaction-Cache abgelegt. Das State-Objekt referenziert das State-Objekt im Shared Cache, in dem geöffnete Business-Object-Instanzen global zwischengespeichert werden. Wenn das Objekt in der „Subtransaktion 2“ erneut geöffnet werden würde, dann würde es die Werte „A=X1“, „B=Y2“ und „C=Z“ enthalten, da der Wert von „B“ im State-Objekt in „Subtransaktion 1“ geändert wurde.
6.5.4 State-Objekte in Transaktionen
Jedes Business Object gehört zu der Transaktion, in der es gelesen bzw. erzeugt wurde. Es kann nur in diesem Transaktionskontext sinnvoll verwendet werden. Die State-Objekte sind ebenfalls transaktionsspezifisch. In jeder Transaktion, in der ein Business Object geändert wird, wird ein entsprechendes State-Objekt erzeugt. Dieses enthält alle in dieser Transaktion geänderten Attribute.
Öffnen einer Business-Object-Instanz (getObject())
Eine Business-Object-Instanz wird mit „getObject()“ von der Datenbank geöffnet und es wird im Shared Cache abgelegt. Es befindet sich noch in demselben Zustand wie in der Datenbank. Deshalb reicht aus, ein einziges State-Objekt zu erzeugen, auf das aus allen Sessions lesend zugegriffen wird.
Die Abbildung zeigt eine Top-Level-Transaktion, die mit „getObject()“ ein Business Object geöffnet hat. Da keine Änderungen vorgenommen wurden, referenziert es das State-Objekt im Shared Cache, welches die Attributwerte enthält.
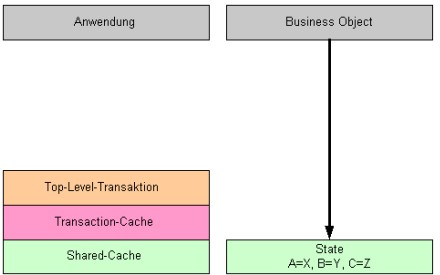
Zustand nach dem Laden eines Business-Object-Instanz
Setzen von Attributwerten (set …() und get …())
Die Referenzierung auf das State-Objekt im Shared Cache ist nicht mehr möglich, wenn innerhalb einer Transaktion ein Attribut einer Business-Object-Instanz geändert wird (set…()). Dann wird für die Business-Object-Instanz, dessen Attribut geändert wurde, ein neues State-Objekt erzeugt, in dem die geänderten Attributwerte gespeichert werden.
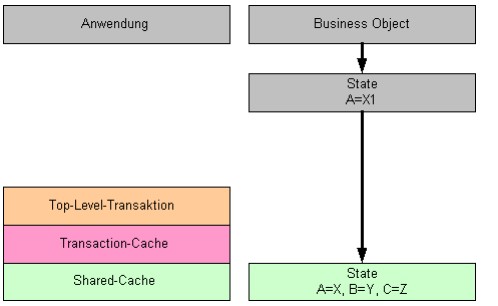
Zustand nach dem Ändern eines Attributes
In der Top-Level-Transaktion wurde die Business-Object-Instanz zum Ändern geöffnet und das Attribut „A“ über die entsprechende „set…()“-Methode auf den Wert „X3“ geändert. Ein neues State-Objekt wird erzeugt, das den Zustand der Business-Object-Instanz mit dem geänderten Attributwert enthält. Innerhalb des State-Objektes wird auf das frühere State-Objekt verwiesen.
Registrieren zum Speichern (putObject() )
Um eine Änderung einer Business-Object-Instanz innerhalb der Transaktion bekannt zu machen, muss es zum Speichern mithilfe „putObject()“ registriert werden. Damit wird das State-Objekt in den Transaction-Cache der Top-Level-Transaktion hinzugefügt.
Die Top-Level-Transaktion hat eine Business-Object-Instanz zum Ändern geöffnet und das Attribut „A“ auf den Wert „X1“ und das Attribut „B“ auf den Wert „Y1“ geändert. Das erzeugte State-Objekt wird durch „putObject()“ zum Speichern registriert. Damit wird es in den Transaction-Cache eingefügt. Damit sind die Änderungen transaktionsweit sichtbar.
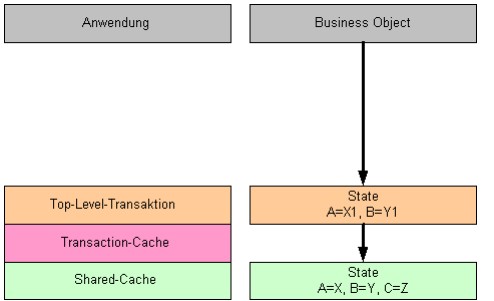
Zustand nach „putObject()“
Die darauf folgende Subtransaktion öffnet ebenfalls dasselbe Business Object. Da ein State-Objekt für das Business Object im Transaction-Cache existiert, verweist das gejöffnete Business Object auf das State-Objekt im Transaction-Cache und somit auch auf die neuen Inhalte der Attribute. Durch Änderung des Attributes „C“ auf „Z1“ wird ein neues State-Objekt erzeugt, das mit „putObject()“ in den Bereich des Transaction-Cache eingefügt wird, der die Änderungen der Subtransaktion aufnimmt. Beim „commit“ der Subtransaktion werden die registrierten Änderungen in den Transaction-Cache der übergeordneten Transaktion, hier der Top-Level-Transaktion, übertragen. Bei „rollback“ werden diese verworfen.
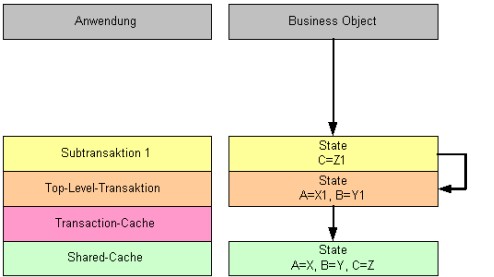
Zustand nach weiterem „putObject()“ derselben Business-Object-Instanz
Bei „commit“ der Top-Level-Transaktion werden die registrierten Änderungen im Transaction-Cache persistent gemacht und der Shared Cache aktualisiert.
6.5.5 Zeitabhängigkeit
Alle Leseoperationen des Object-Managers arbeiten auf der jeweils aktuell gültigen Version einer Business-Object-Instanz. Der Persistenzdienst geht davon aus, dass die Gültigkeitsintervalle aller gespeicherten Versionen zu einer Business-Object-Instanz mit dem gleichen Primärschlüssel lückenlos und überlappungsfrei sind.
Zur Bearbeitung von zeitabhängigen Business Objects kennt der Persistenzdienst den Insert-Only- und den Update-Modus. Werden immer diese beiden Modi verwendet, garantiert der Persistenzdienst, dass die erzeugten Versionen einer Business-Object-Instanz lückenlos und überlappungsfrei sind. Instanzen zeitabhängiger Business Objects können genauso wie alle übrigen Business Objects über die Methoden „putObject()“ und „deleteObject()“ gespeichert bzw. gelöscht werden. Über die Belegung der Attribute „validFrom“ bzw. „validUntil“ wird gesteuert, in welchem dieser Modi die Zeitabhängigkeit gehandhabt wird.
6.5.5.1 Insert-Only-Modus
Dieser Modus wird zum Erzeugen einer neuen Version einer Business-Object-Instanz benutzt. Dazu muss mit dem Zugriffsmodus NEW_VERSION eine neue Version über den Persistenzdienst erzeugt werden. Die Attribute „validFrom“ und „validUntil“ müssen auf „null“ gesetzt sein, bevor die Version mit „putObject()“ gespeichert wird, da diese Attribute vom Persistenzdienst selbst berechnet werden. Diese erzeugte Version ist ab dem aktuellen Zeitpunkt (validFrom) bis zum Maximaldatum gültig. Das „validUntil“-Datum der bisher letzten Version wird auf das „validFrom“-Datum der neuen Version gesetzt.

Beispiel für das Anhängen einer neuen Version
6.5.5.2 Update-Modus
Der Update-Modus dient zum Einfügen einer neuen Version zwischen existierende Versionen einer Business-Object-Instanz. Der Beginn des Gültigkeitszeitraum (validFrom) der einzufügenden Version wird vorgegeben, der Kernel beschränkt in diesem Fall automatisch den maximalen Gültigkeitszeitpunkt (validUntil) der zu diesem Zeitpunkt gültigen Version.
Bei der Verwendung des Update-Modus sollte die Instanz mit dem Zugriffsmodus READ_WRITE und dem zeitabhängigen Schlüssel zum Erzeugen geöffnet werden, damit eine ggf. existierende Version der Business-Object-Instanz berücksichtigt wird. Im Update-Modus muss das Attribut „validUntil“ auf „null“ gesetzt sein, da es vom Persistenzdienst gesetzt wird.

Beispiel für das Einfügen einer neuen Version
6.5.5.3 Bearbeitung durch die Anwendung
Wenn bei einem Business Object „validFrom“ und „validUntil“ gesetzt sind, d. h. nicht „null“ sind, dann führt der Persistenzdienst keine weiteren Operationen aus, um die Konsistenz der Gültigkeitsintervalle zu warten. In diesem Fall werden genau die vorgegebenen Attributwerte gespeichert. Der Persistenzdienst führt keine weiteren Aktionen aus, um für Überlappungsfreiheit und Lückenlosigkeit der Gültigkeitszeitpunkte zu sorgen.
6.5.6 Nummernkreise
Der Persistenzdienst unterstützt eine automatische Nummernvergabe für Nummernkreise. Das ist sehr nützlich, wenn eine lückenlose Nummernvergabe erreicht werden soll. Nummern werden nur beim Erzeugen von Objekten erzeugt. Bei Updates wird keine neue Nummer vergeben.
Ziehen von lückenlosen Nummern
Bei der lückenlosen Nummernvergabe wird Funktionalität vom Persistenzdienst verwendet, um keine Lücken entstehen zu lassen. Die Nummern werden erst beim erfolgreichen Abschluss der zugehörigen Top-Level-Transaktion mit „commit()“ gezogen. Das bedeutet, die zugeteilte Nummer ist vorher nicht bekannt und kann z. B. bei der Datenerfassung zum Business Object noch nicht angezeigt werden. Damit der Persistenzdienst erkennen kann, dass eine Sonderbehandlung bei der Erzeugung einer Business-Object-Instanz notwendig ist, muss die Definition des Business Objects die folgenden Bedingungen erfüllen:
- Der logische Datentyp für das Nummernkreisattribut muss von dem logischen Datentyp „com.cisag.pgm.base.numberrange.GaplessNumberRange“ abgeleitet sein.
- Der logische Datentyp für das Nummernattribut muss von dem logischen Datentyp „com.cisag.pgm.base.numberrange.GaplessNumber10“ oder „com.cisag.pgm.base.numberrange.GaplessNumber50“ abgeleitet sein.
- Die beiden Attribute bilden zusammen einen Index des Business Objects.
Bei der Erzeugung einer Business-Object-Instanz muss vom Entwickler in das Nummernkreisattribut ein Byte-Array-Wert gesetzt werden, der durch den Aufruf der Methode „getAutoNumberRangeValue()“ am Nummernkreismanager bestimmt wird. Dieser werden als Parameter die GUID des zu verwendenden Nummernkreises und die Kontextinformationen übergeben. Zur Erzwingung des automatischen Ziehens der Nummer wird das Nummernattribut entweder auf „null“ gesetzt oder es bekommt einen Nummern-Identifier zugewiesen. Ist das Nummernattribut leer, wird immer eine neue Nummer gezogen. Manchmal ist notwendig, dass mehrere Business-Object-Instanzen die gleiche Nummer für denselben Nummernkreis bekommen. Im Nummernattribut kann deshalb ein beliebiger String gesetzt werden, der als Identifier dient. Der Persistenzdienst setzt für einen Nummernkreis bei den Business-Object-Instanzen dieselbe gezogene Nummer ein, wo der gleiche Identifier eingetragen ist. Ein Identifier ist immer pro Top-Level-Transaktion gültig. Nach dem Einfügen der Instanz mit „putObject()“ in den Transaction-Cache wird die Transaktion mit „commit()“ beendet. Der Persistenzdienst sucht beim Erzeugen einer Business-Object-Instanz nach einem definierten Index, der aus zwei Attributen mit den oben genannten Datentypen besteht. Hat er einen Index gefunden, zieht er automatisch eine Nummer zum übergebenen Nummernkreis im Nummernkreisattribut und speichert diese im Nummernattribut der Instanz und in der zentralen Tabelle „NummernRangeUse“. Wurde zu einem Nummern-Identifier schon eine Nummer gezogen, dann wird diese verwendet. Das geschieht innerhalb einer Transaktion. So ist gewährleistet, dass eine lückenlose Nummernvergabe erfolgt. Werden mehrere Business-Object-Instanzen innerhalb einer Transaktion gespeichert, dann kann man über das spezielle Flag ORDERED_COMMIT angeben, dass die Reihenfolge der Nummernvergabe der Reihenfolge von „putObject()“ zu entsprechen hat.
Wird statt einer Nummernkreis-GUID die ZERO_GUID gesetzt, dann wird der im Nummernattribut gesetzte Wert als Nummer gespeichert.
Wenn die Nummern im Nummernkreis erschöpft sind, dann wird eine „CisApplicationServerException“ vom Typ „NUMBER_RANGE_OVERFLOW“ ausgegeben. Diese Exception erzeugt, wenn diese ins Meldungsprotokoll geschrieben wird, eine entsprechende Meldung.
In dem folgenden Beispiel werden in einer Transaktion zwei Business-Object-Instanzen erzeugt und durch den Persistenzdienst jeweils automatisch eine Nummer vergeben. Die Reihenfolge der Nummernvergabe wird durch die Reihenfolge von „putObject()“ bestimmt.
tm.beginNew(CisTransactionManager.ORDERED_COMMIT);
try {
…
CisNumberRangeManager nrm= CisEnvironment.getInstance().getNumberRangeManager();
obj=(InventoryTransaction) om.getObject(key, CisObjectManager.READ_WRITE);
byte[] autoNumberRangeValue= nrm.getAutoNumberRangeValue(numberRangeGuid, context);
obj.setNumberRange(autoNumberRangeValue); // Setzen des Nummernkreises und Kontextinformationen
obj.setNumber(null); // erzwingt neue Nummer
obj2=(InventoryTransaction) om.getObject(key, CisObjectManager.READ_WRITE);
autoNumberRangeValue= nrm.getAutoNumberRangeValue(numberRangeGuid, context);
obj2.setNumberRange(autoNumberRangeValue); // Setzen des Nummernkreises und Kontextinformationen
obj2.setNumber(“Number-ID“); // erzwingt neue Nummer oder Verwendung der schon früher unter der angegebenen Number-ID gezogenen Nummer
…
om.putObject(obj2);
om.putObject(obj);
…
tm.commit() ;
} catch (RuntimeException ex) {
tm.rollback() ;
throw ex;
}
6.6 OQL-Suchen (getOqlSearchStatement())
OQL-Suchen werden als Entwicklungsobjekt in der Anwendung „Entwicklungsobjekte“ erfasst. Eine OQL-Suche besteht aus einer Sammlung von Fragmenten, Bedingungen und Parametern. Ein „CisOqlSearchStatement“ basiert auf einer OQL-Suche. Erzeugt wird ein „CisOqlSearchStatement“ am Objekt-Manager mithilfe der Methode:
CisOqlSearchStatement getOqlSearchStatement(String searchName);
CisOqlSearchStatement getOqlSearchStatement(String searchName,
String language);
Am „CisOqlSearchStatement“ existieren Methoden zum Setzen von Parameterwerten. Unterschieden wird zwischen Parametern, die bereits in der Suchdefinition enthalten sind und freien Parametern.
6.6.1 Ausführen einer Suche
Ein „CisOqlSearchStatement“ besitzt zwei Methoden zum Ausführen der Suche. Das Ergebnis der Suche kann in beiden Fällen am „CisResultSet“ ermittelt werden. Die Methoden unterscheiden sich darin, dass einer eine zusätzliche Zeichenkette übergeben werden kann, die die Struktur der WHERE-Klausel der Suche beeinflusst (siehe Kapitel „Freie Parameter“).
public CisResultSet execute() ;
public CisResultSet execute(String pattern);
6.6.2 Such-Timeout
Beim Ausführen einer OQL-Suche ist der Such-Timeout im Standard nicht aktiviert. Der Such-Timeout kann aber nachträglich mit der Methode
public void setUseSearchTimeout(boolean useSearchTimeout);
aktiviert werden. Wenn der Such-Timeout aktiv ist, dann wird die Ausführung der von der OQL-Suche abgesetzten Datenbankabfrage nach dem im Systemcockpit bei der Datenbank eingestellten Such-Timeout abgebrochen, wenn die Datenbankabfrage innerhalb des Such-Timeouts kein Ergebnis geliefert hat. Beim Abbruch der Datenbankabfrage wird eine „CisApplicationServerException“ vom Typ „SEARCH_TIMEOUT“ ausgegeben. Diese kann von der Anwendung aufgenommen und speziell behandelt werden.
6.6.3 Setzen von Parametern
In einer Suchdefinition sind alle Parameter einer Suche definiert. Jeder Parameter besitzt einen, in der Suche, eindeutigen Namen. Die einzelnen Parameter werden als einschränkendes Kriterium in der Suche verwendet und mit einem „AND“ verbunden.
Jeder Parameter einer Suche kann mit mehr als einem Wert belegt werden. Die einzelnen Werte eines Parameters werden mit einem „OR“ verbunden. Ein Parameter, der keinen Wert zugewiesen bekommt, wird in die Suche nicht als einschränkendes Kriterium aufgenommen.
Beispiel:
Eine Suche besitzt die Parameter „a, b, c, d“. Der Parameter „a“ soll mit den Werten „1, 2, 4“, der Parameter „b“ mit den Werten „10, 20“ belegt werden. Die Parameter „c“ und „d“ bekommen keine Werte zugewiesen. Die Parameterbelegung führt zu folgendem Term: (a = 1 OR a = 2 OR a = 4) AND (b = 10 OR b = 20)
Am „CisOqlSearchStatement“ stehen Methoden für eine Vielzahl von Datentypen bereit, um die einzelnen Werte für einen Parameter einer Suche zu setzen.
Beispiel:
Mit den exemplarisch gewählten Methodensignaturen lassen sich einzelne Long- und Int-Werte für einen Parameter setzen:
public void setLongSelection(String name, long value);
public void setIntSelection(String name, int value);
Sollen mehrere Werte oder Bereiche für einem Parameter gesetzt werden, dann muss, mithilfe der Klasse „com.cisag.pgm.objsearch.SelectionSupport“, ein Abfrage-String erstellt und der Methode „setSelection(…)“ übergeben werden.
6.6.4 Freie Parameter
Neben den in der Suchdefinition festgelegten Parametern können weitere freie Parameter am „CisOqlSearchStatement“ definiert und belegt werden.
Im Gegensatz zu den festgelegten Parametern werden bei freien Parametern keine Abfrage-Strings verwendet. Die Methoden zum Setzen der freien Parameter enden dementsprechend nicht mit „Selection“.
Beispiel:
public void setLong(String name, long value);
public void setInt(String name, int value);
Definiert werden die freien Parameter in einer Zeichenkette, die beim Ausführen der Suche an die WHERE-Klausel des „CisOqlSearchStatement“ angehängt wird. Die Zeichenkette enthält Platzhalter für die verwendeten Parameter. Die Namen der Platzhalter entsprechen den Namen der Parameter.
6.6.5 Verwenden eines zusätzlichen Suchmusters
Das „CisOqlSearchStatement“ bietet zwei Methoden zum Ausführen einer Suche an. Eine der Methoden kann eine Zeichenkette übergeben werden, die die WHERE-Klausel der OQL-Suche beeinflusst.
Die Zeichenkette enthält einen OQL-Ausdruck, wie er auch für die WHERE-Klausel benutzt werden darf. Die Parameter einer Suche, normale und freie, können in den Ausdruck eingebettet werden. Dazu ist an den gewünschten Stellen der Parametername in geschweifte Klammern als Platzhalter zu setzen.
Freie Parameter werden immer als Wert und normale Parameter als boolescher Ausdruck eingesetzt.
Beispiel:
Ein freier Parameter „number“ soll für das Attribut ac:name mit dem Wert „0815“ belegt werden.
stm.setString(„number“, „0815“);
stm.execute(„ac:name={number});
Beispiel: Die normalen Parameter “code” und “name” sollen nicht mit einem “AND” sondern einem “OR” verknüpft werden.
stm.execute(„({code} OR {name})”);
Werden normale Parameter im OQL-Ausdruck verwendet, dann werden diese nicht mehr bei der normalen Verknüpfung der Parameter berücksichtigt.
Beispiel:
Die Parameter A, B, C und D sind an einer Suche definiert und werden mit Werten belegt. Im Normalfall werden die Parameter mit „AND“ verknüpft: „A AND B AND C AND D“. Werden die Parameter C und D im OQL-Ausdruck verwendet, z. B. „({C} OR {D})“, so werden nur A und B verknüpft und der OQL-Ausdruck angehängt: „A AND B AND (C OR D)“.
6.6.6 Wiederaufsetzen
Eine Suche gibt in der Regel nie alle Datensätze aus. Stattdessen wird immer nur eine begrenzte Anzahl von Datensätzen eingelesen. In den bereitgestellten Suchenvisualisierungen, z. B. Dialog-Suche, Anwendungswertehilfe etc., ist die Anzahl auf 60 Datensätze begrenzt. Für Abfrageanwendungen ist die Anzahl der Datensätze vom vorhandenen Platzangebot auf der Oberfläche abhängig. Werden weitere Datensätze benötigt, dann muss die Suche an der alten Stelle wieder aufsetzen und die nächsten Datensätze einlesen.
Um wieder aufsetzen zu können, muss jeder der gefundenen Datensätze für die benutzte Sortierung eindeutig sein, d. h. die in der Sortierung verwendeten Parameter, die zugleich auch Rückgabewert sein müssen, bilden einen eindeutigen Schlüssel für die Bestimmung eines Datensatzes. Ist diese Voraussetzung gegeben, dann kann mithilfe der Sortierparameter und der Rückgabewerte des letzten gefundenen Datensatzes eine Bedingung aufgestellt werden, um den nächsten Datensatz für das Wiederaufsetzen zu ermitteln.
Weitere Details über die Erstellung der Bedingung finden Sie in der Dokumentation „Referenzhandbuch: Suchen“.
Am „CisOqlSearchStatement“ befinden sich zwei Methoden für das Wiederaufsetzen einer Suche. Zum Setzen der Position für das Wiederaufsetzen existiert die Methode „setContinuePosition(…)“. Der Methode kann ein „CisResultSet“ übergeben werden. Die Werte der für die Sortierung relevanten Parameter werden ausgelesen und nach dem beschriebenen Verfahren zu einer Bedingung zusammengestellt. Anschließend sollte das „CisResultSet“ geschlossen werden.
Falls später die Methode „continueExecute(…)“ aufgerufen wird, dann wird die Suche mit der erstellten Bedingung für das Wiederaussetzen fortgeführt. Wird die Methode aufgerufen, ohne dass vorher die Position für das Wiederaufsetzen bestimmt wurde, dann wird eine Exception ausgegeben.
public void setContinuePosition(CisResultSet rs)
throws SQLException;
public CisResultSet continueExecute() ;
6.6.7 Anhängen eines eindeutigen Schlüssels
Reichen die gewählten Parameter der Sortierung nicht aus, um eine eindeutige Position für das Wiederaufsetzen zu bestimmen, dann können künstlich weitere Parameter hinzugenommen werden. Das sind die Parameter, welche in der Suchdefinition als Key-Attribut markiert sind. Die Parameter, die dieses Kennzeichen tragen, würden ausreichen, um einen Datensatz eindeutig zu bestimmen.
Um diese Parameter bei der Bedingung zum Wiederaufsetzen zu berücksichtigen, muss der Methode „setAppendUnqiuekey(…)“ der Wert „true“ übergeben werden.
public void setAppendUnqiueKey(boolean appendUniqueKey);
6.6.8 Fragmente
Die Suchdefinition zu einer OQL-Suche besteht mindestens aus einem Hauptfragment und einer Menge von Parametern, die an diesem Hauptfragment definiert sind.
An einer Suchdefinition lassen sich weitere Fragmente und zugehörige Parameter definieren. Diese Fragmente sollten immer mit einem „Outer-Join“ an das Hauptfragment gebunden werden.
Der Unterschied zum Hauptfragment ist, dass diese Fragmente nur dann zu der Suche hinzugenommen werden, wenn mindestens einer der definierten Parameter für die Suche genutzt wird, z. B. für die Abfrage oder Sortierung. Werden die Parameter nicht genutzt, dann entfällt das ganze Fragment. Der resultierende OQL-Ausdruck wird kürzer und damit weniger komplex. Dadurch steigt die Leistung der Abfrage.
Beispiel:
Eine Suchdefinition besitzt ein Haupt- und ein Nebenfragment. Das Hauptfragment ist wie folgt definiert:
{base = com.cisag.app.test.AEntity A}
Die Attribute A:a, A:b, A:c werden unter den Parameternamen a, b, c für die Abfrage verwendet.
Das Nebenfragment ist wie folgt definiert:
{base} LEFT OUTER JOIN com.cisag.app.test.BEntity B
Die Attribute B:e, B:f werden unter den Parameternamen e, f für die Abfrage verwendet.
Werden für die Parameter e oder f Werte für die Abfrage hinterlegt, dann ergibt sich folgendes OQL:
SELECT … FROM com.cisag.app.test.AEntity A
LEFT OUTER JOIN com.cisag.app.test.BEntity B
ON A:bguid = B:guid
WHERE B:e = …
ORDER BY …
Werden hingegen keine Parameter aus dem Nebenfragment genutzt so verkürzt sich das OQL auf folgenden Ausdruck:
SELECT … FROM com.cisag.app.test.AEntity A
WHERE A:a = …
ORDER BY …
6.7 Einschränkungen
Im Folgenden sind Einschränkungen der Benutzung des Persistenzdienstes aufgeführt.
ERP-System-Datentyp „SBlob“
Der ERP-System-Datentyp „SBlob“ steht nur für den internen Gebrauch innerhalb der Comarch Software und Beratung AG zur Verfügung. Zukünftig wird der Datentyp „SBlob“ nicht mehr unterstützt. Eine Alternative ist die Verwendung von Dateien über den Knowledge Store.
Der ERP-System-Datentyp SBlob (Streamable Blob) ist ein spezieller Datentyp, um größere Menge von binären Daten zu speichern. Der Vorteil ist, dass der Persistenzdienst zu keinem Zeitpunkt die Daten vollständig im Hauptspeicher hält. Dieser Datentyp wird dann benutzt, wenn die binären Daten so groß sind, dass der Hauptspeicherverbrauch zum vollständigen Laden eines Datensatzes auf dem Application-Server nicht mehr vertretbar ist.
An der Klasse „com.cisag.pgm.datatype.CisStreamableBlob“ kann sowohl ein „InputStream“ zum Lesen der Blob-Daten als auch ein „OutputStream“ zum Schreiben abgefragt werden.
Folgende Einschränkungen existieren für die Verwendung von Streamable Blobs:
- Streamable Blobs können nur einmal pro Transaktion geschrieben werden.
- Streamable Blobs können nur auf der 1. Transaktionsebene geschrieben werden, d. h. nicht in Subtransaktionen.
- Streamable Blobs können erst nach dem Bestätigen der Transaktion durch „commit“ wieder gelesen werden.
6.8 Der Sperrdienst
Der Sperrdienst verwaltet logische Sperren und Sperren auf Business Objects. Die Sperren aller Application-Server in einem System werden zentral auf dem Message-Server verwaltet.
In einem Mehrbenutzersystem ist notwendig, die Nutzung gemeinsamer Ressourcen zu regeln. Eine Sperre (Lock) dient zur Synchronisation von Zugriffen auf eine beschränkte Ressource. Meist sind diese Ressourcen eine oder mehrere Business-Object-Instanzen. Jede Sperre wird für eine Ressource in einem bestimmten Sperrkontext angefordert.
Alle Sperren werden von einem zentralen Sperrdienst vergeben. Wenn eine Sperre angefordert wird, wird eine Anfrage an den Sperrdienst gestellt. Der Sperrdienst gewährt entweder diese Sperre oder lehnt die Sperranforderung ab. Die Sperre bleibt solange bestehen bis diese explizit oder der Sperrkontext der Sperre freigeben wird.
6.8.1 Sperrkontexte
Sperren werden immer in einem Sperrkontext angefordert. Mögliche Sperrkontexte sind Transaktionen, Anwendungsinstanzen und Sessions. Die Existenz der Sperre ist an den entsprechenden Sperrkontext gebunden. Wenn eine Sperre innerhalb einer Transaktion angefordert wurde, wird diese freigegeben, wenn die Transaktion abgeschlossen wird (mit „commit“ oder „rollback“). Die Sperrkontexte haben die folgenden Abhängigkeiten:
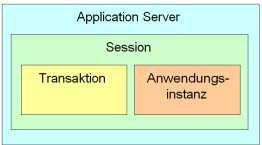
Hierarchie der Sperrkontexte
In der Abbildung sind die innen liegenden Kontexte existenziell an die äußeren Sperrkontexte gebunden. Wenn beispielsweise eine Session beendet wird, dann werden auch alle Sperren auf Transaktionsebene und auf Anwendungsinstanzebene freigegeben, die in dieser Session angefordert wurden. Wenn der Application-Server beendet wird, dann werden alle Sperren freigegeben, die der Application-Server angefordert hatte.
6.8.2 Typen von Sperren
Die folgenden Typen von Sperren werden im Persistenzdienst für den Anwendungsprogrammierer sichtbar.
Logische Sperren
Logische Sperren werden durch eine Zeichenkette identifiziert. Sie sperren keine direkt für den Persistenzdienst erkennbare Ressourcen, sondern haben nur eine Bedeutung für die Anwendung, die diese verwenden. Logische Sperren sind entweder
- exklusiv, d. h. nur ein Kontext kann eine exklusive logische Sperre zu einem Zeitpunkt halten,
oder
- nicht exklusiv, d. h. beliebig viele Kontexte können gleichzeitig nicht exklusive logische Sperren zu einem Zeitpunkt halten.
Logische Sperren werden immer explizit von einer Anwendung angefordert. Der Sperrkontext einer logischen Sperre ist meist eine Anwendungsinstanz.
Instanzsperren
Für einzelne Business-Object-Instanzen werden implizit vom Persistenzdienst abhängig vom Zugriffsmodus Instanzsperren angefordert. Alle Instanzsperren werden im Sperrkontext einer Top-Level-Transaktion angefordert.
Beim Zugriffsmodus READ_REPEATABLE wird eine Read-Instanzsperre angefordert. Beliebig viele Top-Level-Transaktionen können gleichzeitig eine Read-Instanzsperre halten.
Beim Zugriffsmodus READ_UPDATE, READ_WRITE oder INSERT wird eine Write-Instanzsperre angefordert. Nur eine Top-Level-Transaktion kann zu einem Zeitpunkt eine Write-Instanzsperre halten.
Auf einer Business-Object-Instanz kann nur entweder eine Write-Instanzsperre angefordert werden oder beliebig viele Read-Instanzsperren. Instanzsperren werden erst dann freigegeben, wenn die Top-Level-Transaktion abgeschlossen wurde. Das heißt, wenn beispielsweise eine Transaktion mit „commit()“ abgeschlossen wird, dann werden die geänderten Objekte auf die Datenbank geschrieben und erst danach werden die Instanzsperren freigegeben.
Tabellensperren
Bei Verwendung der Methode „getUpdateStatement()“ wird eine Write-Tabellensperre implizit angefordert. Diese umfasst die gesamte Tabelle, d. h. alle Business-Object-Instanzen eines Typs auf einer Datenbank. Nur jeweils eine Top-Level-Transaktion kann eine Write-Tabellensperre halten. Tabellensperren werden erst dann freigegeben, wenn die Top-Level-Transaktion abgeschlossen wurde. Das heißt, wenn eine Transaktion mit „commit()“ abgeschlossen wird, dann werden die Update-Statements auf der Datenbank ausgeführt und erst danach werden die Tabellensperren freigegeben.
6.8.3 Business-Entity-Sperren
Wenn die „Dependents“ eines Business Entitys für Business-Entitiy-Sperren geeignet sind, dann wird, falls eine Instanzsperre für ein Dependent benötigt wird, stattdessen die Sperre für das zugehörige Business Entity angefordert. Insbesondere wenn mehrere Instanzsperren für Dependents der gleichen Business-Entity-Instanz angefordert werden, muss nur noch eine Sperranforderung für das Business Entity bearbeitet werden. Die Instanzsperren der Dependents werden beim Abschluss der Transaktion in einer Sperranforderung bearbeitet.
Damit ein Dependent Business-Entity-Sperren unterstützt, muss der Primärschlüssel des Dependents mit dem Fremdschlüssel des Primärschlüssels des Business Entitys beginnen.
Beispiel:
Das Business Entity „E“ hat den Primärschlüssel „guid“. Das Dependent „D“ speichert den Primärschlüssel von „E“ in dem Attribut „header“.
Wenn Primärschlüssel von „D“ aus den Attributen „header“ und „detailGuid“ besteht, so ist „D“ für das Business-Entity-Sperren geeignet.
Wenn Primärschlüssel von „D“ nur aus dem Attribut „detailGuid“ besteht, dann ist „D“ nicht für das Business-Entity-Sperren geeignet.
Insbesondere bei Business Entitys mit einer hohen Anzahl von Dependents sollten die Business-Entity-Sperren beim Entwurf des Datenmodells berücksichtigt werden.
6.8.4 Abgleich der Shared Caches
Die Business-Object-Sperren werden genutzt, um die Shared Caches der Application-Server im System abzugleichen. Immer wenn für eine Business-Object-Instanz eine Write-Instanzsperre angefordert wurde, dann wird davon ausgegangen, dass die Instanz auch verändert wird. In regelmäßigen Abständen (in der Regel alle 5 Sekunden) werden alle Business-Object-Instanzen aus den Shared Caches aller Application-Server entfernt, deren Write-Instanzsperre freigegeben wurde. Im Shared Cache des Application-Servers, der die Änderung vorgenommen hat, bleiben die Instanzen im Shared Cache, da diesem Application-Server die aktuell gültige Version der Instanz vorliegt.
Bei der Freigabe von Write-Tabellensperren werden im gesamten System in den gleichen regelmäßigen Abständen alle Business-Object-Instanzen aus dem Shared Cache aller Application-Server entfernt.
6.8.5 Logische Sperren
„Logische Sperren“ sperren eine beliebige Ressource. Meist sind diese Ressourcen eine Menge von Business-Object-Instanzen, die über einen bestimmten Zeitraum nicht verändert werden dürfen. Das ist der Fall, wenn eine komplexe und umfangreiche Operation auf mehrere Top-Level-Transaktionen aufgeteilt wird. Die jeweiligen Top-Level-Transaktionen könnten teilweise inkonsistente Zustände auf der Datenbank hinterlassen. Instanzsperren haben die Top-Level-Transaktion als Sperrkontext. Bei mehreren aufeinander folgenden Top-Level-Transaktionen ist möglich, dass zwischen den Transaktionen andere Sessions Zugriff auf die vorher gesperrten und ggf. inkonsistenten Objekte erhalten. Mit einer logischen Sperre kann diese komplexe Operation abgesichert werden. Damit es jedoch funktioniert, muss mit jedem Zugriff auf die gesperrten Business-Object-Instanzen, die logische Sperre explizit angefordert werden. Der Persistenzdienst kennt die Beziehung zwischen der Sperre und den Business-Object-Instanzen nicht und kann die Sperre nicht implizit prüfen.
Logische Sperren werden meist im Sperrkontext einer Anwendungsinstanz benötigt. Diese logischen Sperren können mit der Methode
public acquireLock(String value);
public acquireLock(String value, byte use);
des Application-Managers angefordert werden. Der optionale Parameter „use“ gibt an, ob eine exklusive oder eine nicht exklusive Sperre angefordert werden soll. Solange eine Anwendungsinstanz eine exklusive Sperre auf der Zeichenkette „value“ hält, wird keine andere exklusive oder nicht exklusive Sperre auf der gleichen Zeichenkette gewährt. Wenn eine Anwendungsinstanz eine nicht exklusive Sperre auf der Zeichenkette „value“ hält, dann werden direkt danach angeforderte weitere nicht exklusive Sperren auf der gleichen Zeichenkette gewährt. Wenn der optionale Parameter „use“ nicht angegeben wird, dann wird eine exklusive Sperre angefordert. Der Rückgabewert von „acquireLock()“ bestimmt, ob die Sperre gewährt oder abgelehnt wurde. Wenn die Sperre abgelehnt wurde, dann kann mit
public String getLockInformation(String value);
die Information abgefragt werden, welcher Benutzer die Sperre hält. Die Methode „getLockInformation()“ darf nicht aufgerufen werden, wenn die Sperre erfolgreich gewährt wurde, da diese Methode die Sperre ggf. freigibt.
Die Anwendungsinstanz ist dafür verantwortlich, jede Logische Sperre, die diese angefordert hat, auch wieder mit
public void releaseLock( String value );
freizugeben. Wenn eine Anwendungsinstanz angeforderte Sperren nicht wieder freigibt, können andere Anwendungsinstanzen die Sperre nicht erfolgreich anfordern und damit nicht auf die gesperrte Ressource zugreifen.
6.9 Datenbank-Fail-Over
Die meisten Datenbank-Management-Systeme (DBMS) haben Fail-Over-Mechanismen. Das bedeutet, dass mehrere Datenbankinstanzen parallel auf der gleichen bzw. auf einer gespiegelten Datenbasis laufen. Wenn eine Datenbankinstanz aufgrund eines Fehlers nicht mehr zur Verfügung steht, dann kann eine andere Datenbankinstanz die Aufgaben der ausgefallenen Instanz übernehmen. Häufig existieren auch innerhalb eines DBMS mehrere Möglichkeiten, das Fail-Over für ein Datenbanksystem zu konfigurieren. Die unterstützten Konfigurationen finden Sie in der Installationsdokumentation.
Der Persistenzdienst führt alle Verbindungen zu einer Datenbankinstanz pro ERP-System-Datenbank in einem gemeinsamen Pool. Wenn der Application-Server eine Verbindung benötigt, bereits alle Verbindungen in dem Pool verwendet werden und die maximale Anzahl von Verbindungen in dem Pool noch nicht erreicht ist, dann wird eine neue Verbindung geöffnet und im Pool registriert. Wenn die Datenbank einen Fehler meldet, dann wird die betroffene Verbindung geschlossen.
Wenn der Persistenzdienst durch die Fehlermeldung erkennt, dass eine Datenbankinstanz ausgefallen ist, dann werden alle offenen inaktiven Datenbankverbindungen geschlossen und nach einer Wartezeit erneut geöffnet. Die gerade ausgeführte Operation in einer aktiven Datenbankverbindung bricht beim Ausfall der Datenbankinstanz mit einer Fehlermeldung ab. Der Persistenzdienst erkennt diese Fehlermeldung und versucht, die Operation mit einer neuen Datenbankverbindung erneut auszuführen. Die folgenden Operationen können nicht erneut ausgeführt werden:
- Abschluss einer Datenbanktransaktion mit „commit“.
- Abfragen des nächsten Datensatzes in einem bereits geöffneten „ResultSet“ oder „ObjectIterator“.
- Datenschemamodifikationen beispielsweise mit „crtbo“ oder „upgaps“.
Wenn bei einer dieser Operationen die Datenbankverbindung abbricht, dann wird eine „CisApplicationServerException“ mit dem Typ „DATABASE_CONNECTION_LOST“ ausgegeben. Diese Exception kann von Anwendungen besonders behandelt werden. Beispielsweise sollten schreibende Transaktionen beim Auftreten dieser Exception wiederholt werden. Diese Exception wird auch bei anderen Operationen ausgegeben, wenn die Verbindung zur Datenbank nicht wiederhergestellt werden konnte.
6.10 Änderungsjournal
Das Änderungsjournal ist eine Protokollfunktion für die Historie von betriebswirtschaftlichen Größen und zeichnet Ereignisse im Lebenszyklus von Business Entitys auf. Pro Business Entity und Datenbank-Instanz kann festgelegt werden, ob Änderungen protokolliert werden sollen. Der Persistenzdienst sorgt also nicht nur für die Änderungsinformationen an Business Entitys, sondern gleichfalls für die Einträge im Änderungsjournal. Nur erfolgreich abgeschlossene Toplevel-Transaktionen werden protokolliert.
Das Dokument „Änderungsjournal“ enthält weitere Informationen.
6.11 Übertragungsliste
Die Übertragungsliste zeichnet im Unterschied zum Änderungsjournal nur auf, dass eine Business-Entity-Instanz seit der letzten Verarbeitung dieser Instanz verändert wurde. Die Übertragungsliste kann insbesondere beim Datenaustausch mit Fremdsystemen verwendet werden.
Das Dokument „Änderungsjournal“ enthält weitere Informationen.
6.12 Update-Listener
Insbesondere beim Austausch von Daten mit Fremdsystemen ist hilfreich zu wissen, ob ein Business Object in einem bestimmten Zeitraum verändert wurde. Nur wenn eine Änderung stattgefunden hat, muss der Datenaustausch mit dem Fremdsystem gestartet werden. Durch einen Update-Listener kann nun genau dies geprüft werden.
Ein Update-Listener wird am „CisSystemManager“ durch die Methode „createUpdateListener“ erzeugt. Dabei werden die zu überwachende Datenbank und die zu überwachenden Business Objects festgelegt.
Am Update-Listener kann über die Methode „getUpdateTimeStamps“ abgefragt werden, welche Business Objects der Update-Listener überwacht und ob diese Business Objects seit dem letzten Aufruf der Methoden „waitUpdate“ oder „checkUpdate“ verändert wurden. Die Methode „isChanged“ liefert „true“, falls eine Instanz des Business Objects verändert wurde. Die Methode „etTimeStamp“ liefert den Zeitpunkt zu dem die Änderung vom Update-Listener verarbeitet wurde. Dieser Zeitpunkt weicht im Allgemeinen von den Zeitpunkten in der „UpdateInfo“ ab.
Update-Listener können gemeinsam mit der Übertragungsliste genutzt werden. Der Update-Listener meldet, dass eine Business-Object-Instanz verändert wurde und die Übertragungsliste ergibt, welche Instanz verändert wurde. Siehe auch Kapitel „Übertragungsliste“.
Beachten Sie, dass ein Update-Listener erst nach seiner Erzeugung Änderungen überwacht. Alle Änderungen an den zu überwachenden Business Objects, die vor dem Erzeugen des Update-Listeners stattgefunden haben, führen nicht dazu, dass „isChanged“ den Wert „true“ liefert.
Nach dem Erzeugen des Update-Listeners muss daher angenommen werden, dass alle Business Objects geändert wurden, bevor der Update-Listener erzeugt wurde.
byte[] databaseGuid =
tm.getDatabaseGuid(CisTransactionManager.OLTP);
Class[] classes = new Class[] {
Partner.class, Item.class
};
CisUpdateListener updateListener = sm.createUpdateListener(
databaseGuid, classes );
try {
// Verarbeitung aller vor dem Start des Listeners
// geänderten Objekte
for (UpdateTimeStamp updateTimeStamp :
updateListener.getUpdateTimeStamps()) {
process(updateTimeStamp.getClassGuid());
}
while (! env.isToBeRemoved()) {
// Warte mindestens 30s zwischen zwei Verarbeitungs-
// schritten
wait(30000);
// Warte unendlich lange auf eine Änderung
if (updateListener.waitUpdate(0)) {
// Verarbeiten aller geänderten Objekte
for (UpdateTimeStamp updateTimeStamp :
updateListener.getUpdateTimeStamps()) {
if (updateTimeStamp.isChanged()) {
process(updateTimeStamp.getClassGuid());
}
}
}
}
} finally {
updateListener.deregister();
}