
1 Themenübersicht
Zu einem Comarch-ERP-Enterprise-System gehören mehrere Datenbanken. Der strukturelle Aufbau jeder verwendeten Datenbank in Comarch ERP Enterprise ist gleich. Die Arbeit mit den ERP-Systemen ist leichter, wenn ein grundlegendes Verständnis für den Aufbau einer Datenbank und die Mechanismen für Schemaänderungen vorhanden ist. Ziel dieses Dokuments ist, dieses Wissen zu vermitteln.
2 Zielgruppe
- Administratoren
- Entwickler mit erweiterten Kenntnissen
3 Begriffsbestimmung
Business Object
Das Comarch-ERP-Enterprise-Datenmodell basiert auf Business Objects. Sie enthalten ausschließlich Daten und werden deshalb auch als Datencontainer bezeichnet. Die Bearbeitung dieser Daten wird mithilfe der Anwendungslogik realisiert, die Zustandstransformationen auf den Daten durchführt. Mit den Business Objects wurden unter weitestgehender Berücksichtigung der dritten Normalform die relevanten Ausschnitte der Realität modelliert, das heißt die Einheiten wurden möglichst redundanzfrei erstellt, woraus eine Vielzahl an Business Objects resultiert. Die Beschreibug des Aufbaus eines Business Objects ist ein Entwicklungsobjekt. Eine Business-Object-Instanz ist eine Ausprägung der als Entwicklungsobjekt abgelegten Beschreibung. Der Persistenzdienst kann Business-Object-Instanzen lesen, speichern und löschen. Oftmals liegt eine Business-Object-Beschreibung in normalisierter Form vor. Dabei kann die eigentliche betriebswirtschaftliche Größe durch mehr als ein Business Object beschrieben werden. Jedoch besteht immer nur ein Haupt-Business-Object. Daher werden Business Objects zu einem Business Entity gruppiert, bei denen ein besonderes gekennzeichnetes Business Object als Repräsentant der Gruppe auftritt. Dieser Repräsentant wird mit seiner Gruppe zum Business Entity.
Datenbank
Eine Datenbank ist eine Ausprägung eines Datenbankschemas. Eine Datenbank umfasst die Daten, die gemäß einem zugehörigen Datenbankschema strukturiert sind.
Datenbankschema
Das Datenbankschema enthält die Strukturinformationen der Objekte, die auf einer Datenbank gespeichert werden können.
Objektbeschreibung
Die Objektbeschreibung enthält die Metadaten, um ein Business Object, einen Part oder View zu generieren.
Part
Parts sind Datencontainer für strukturierte Daten. Ein Part kann als komplexes Attribut in einem Business Object oder in einem Part verwendet werden. Parts können nicht direkt auf einer Datenbank gespeichert werden, sondern nur eingebettet in ein Business Object.
Tabelle
Ein Business Object wird auf einer Datenbank in einer oder mehreren Tabellen gespeichert.
Tabellenbeschreibung
Die Tabellenbeschreibung dient als Vorlage, für die Tabellendefinition und die Tabelle. Jedes Business Object besitzt eine Tabellenbeschreibung. Aus der Tabellenbeschreibung kann das Schema der Tabelle abgeleitet werden, in der die Business-Object-Instanzen gespeichert werden. Die Tabellenbeschreibung wird aus der Objektbeschreibung generiert.
Tabellendefinition
Eine Tabellendefinition beschreibt das Schema einer Tabelle. Die Tabellendefinition enthält eine datenbankunabhängige Beschreibung der Spalten und Indizes einer Tabelle.
4 Beschreibung
4.1 Grundlagen
Eine Datenbank im Verständnis von Comarch ERP Enterprise besteht aus einer Menge von Tabellen und Views. Eine Tabelle besitzt ein Schema, das beschreibt wie diese aufgebaut ist und einen Inhalt, der gemäß dem Schema strukturiert ist. Ein View besitzt nur ein Schema. Der Inhalt eines Views errechnet sich aus anderen Tabellen. Das Schema einer Datenbank besteht aus den Schemata der in dieser enthaltenen Tabellen und Views.
Jede Tabelle und jeder View liegt in genau einer Datenbank. Jede Operation kann nur auf Tabellen und Views auf genau einer Datenbank zugreifen. Jede Operation beeinflusst nur diese Datenbank und keine weitere.
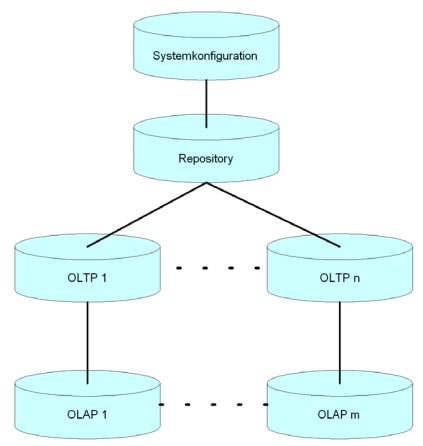
Jede Comarch-ERP-Enterprise-Datenbank ist gemäß ihres Inhalts und ihrer Verwendung typisiert:
- Systemkonfiguration
- Repository
- OLTP
- OLAP
Das Schema ist in einem konsistenten Comarch-ERP-Enterpries-System (nachfolgend kurz „ERP-System“ genannt) bei allen Datenbanken mit dem gleichen Inhaltstyp identisch.
Beispiel:
Alle OLTP-Datenbanken haben das gleiche Schema. Der Inhalt der OLTP-Datenbanken kann jedoch unterschiedlich sein.
Jede Tabelle und jeder View in einer Datenbank wurde durch das ERP-System mithilfe von Entwicklungsobjekten erzeugt. Die in den Entwicklungsobjekten erfassten Daten beschreiben das Schema des Datenbank-Objekts vollständig.
4.2 Datenbankschema-Änderungen
In diesem Abschnitt wird erläutert, wie Änderungen am Datenbankschema eines Business Objects im ERP-System ablaufen.
4.2.1 Erzeugung des Datenbankschemas
Das Entwicklungsobjekt Business Object besteht aus Attributen, Indizes, Beziehungen und weiteren Daten. Die Datentypen der Attribute eines Business Objects können einfache Datentypen wie beispielsweise Strings oder Zahlen oder auch aus komplexen Datentypen wie Arrays (fester Länge) und Parts bestehen. Alle diese Daten werden in der Objektbeschreibung des Business Objects zusammengefasst.
Die Objektbeschreibung ist im Repository als Entwicklungsobjekt versionisiert, d. h. wenn eine Objektbeschreibung in eine Entwicklungsaufgabe aufgenommen wird, so bekommt diese eine neue Versionsnummer.
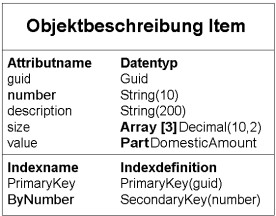
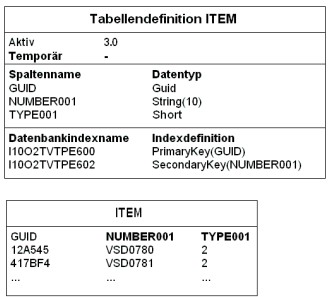
Beispiel für die Objektbeschreibung des Business Objects „Item“
Aus der Objektbeschreibung im Entwicklungsprozess durch den Befehl crtbo die Tabellenbeschreibung generiert. Die Tabellenbeschreibung dient als Vorlage für das Datenbankschema der Tabelle. Die Tabellenbeschreibung besteht aus Attributen und Indizes. Alle Attribute der Tabellenbeschreibung haben einfache Datentypen. Alle komplexen Attribute der Objektbeschreibung wie Parts und Arrays werden in der Tabellenbeschreibung in einfache Attribute umgewandelt. Bei Parts wird zusätzlich zu den Partattributen ein Boolean-Attribut erzeugt, dass angibt, ob der Part gesetzt oder null war.
In der Tabellenbeschreibung kann jedes Attribut durch den Attributpfad oder durch den Spaltennamen identifiziert werden. In dem Attributpfad werden komplexe Attribute durch Punkte „.“ getrennt und der Index von Array-Felder durch eckige Klammern eingeschlossen „[]“. Der Spaltenname berechnet sich aus dem Attributpfad, besitzt jedoch keine Sonderzeichen und kann somit auch als Spaltenname im Datenbankschema der Tabelle verwendet werden. Ebenso der Tabellenname und die Indexnamen werden in eine für das Datenbankschema verwendbare Schreibweise umgewandelt. Die Tabellenbeschreibung wird sowohl für die Generierung der Datenbanktabellen genutzt als auch beim Zugriff auf die Datenbanktabelle. Beispielsweise werden bei der Umwandlung OQL in SQL die Attributpfade bzw. die Spaltennamen benutzt.
Beim Erzeugen der Tabellenbeschreibung wird die Versionsnummer der Objektbeschreibung in die Tabellenbeschreibung übernommen.
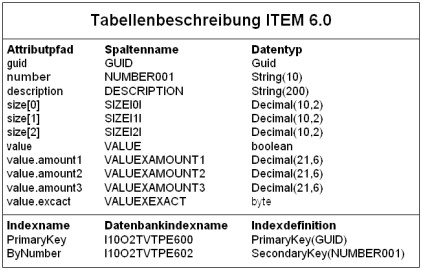
Beispiel für die Tabellenbeschreibung des Business Objects „Item“
Auf jeder Datenbank auf der ein Business Object generiert wird, wird gleichzeitig mit der Anlage der Datenbanktabelle auch die Tabellendefinition in die Datenbank geschrieben. Die Tabellendefinition ist eine vollständige, vom verwendeten Datenbank-Managementsystem (DBMS) unabhängige Beschreibung des Schemas der Datenbanktabelle. Die Tabellendefinition übernimmt die Schemadaten aus der Tabellenbeschreibung. Die Tabellendefinition und die aktive Tabelle in einer Datenbank bilden eine Einheit. Das Schema der aktiven Tabellen entspricht exakt den Daten in der Tabellendefinition.
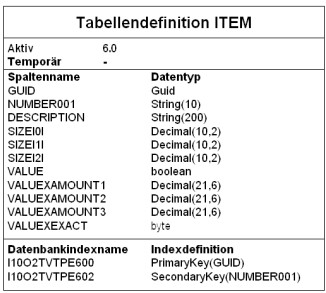
Beispiel für die Tabellendefinition des Business Objects „Item“
Zusammengefasst entsteht der folgende Ablauf von der Erfassung der Objektbeschreibung bis zu der Generierung der Datenbanktabelle.

Verlauf der Generierung einer Datenbanktabelle
Zu jeder Objektbeschreibung gibt es genau eine Tabellenbeschreibung. Die Tabellenbeschreibung muss nicht mit den Tabellendefinitionen auf den Datenbanken übereinstimmen. Abweichungen kann es jedoch nur geben, wenn auf dem System entwickelt wird oder wenn Softwareaktualisierungen nicht vollständig aktiviert sind. Abweichungen sind demnach nur auf Systemen erlaubt, auf denen entwickelt wird. Auf allen anderen System ist das ein Fehler.
Die Tabellenbeschreibung und die Tabellendefinitionen enthalten zusätzlich die Versionsnummer der Objektbeschreiung aus der diese entstanden sind.
4.2.2 Datenbankschema-Änderungen aktivieren
Wenn das Schema einer Datenbanktabelle geändert wird, dann müssen die Daten aus der bisher aktiven Tabelle in die Tabelle mit dem neuen Schema übernommen werden. Jede Änderung am Datenbankschema eines Business Objects läuft daher wie folgt ab:
- Generierung der temporären Tabelle mit dem neuen Schema.
- Übernahme der Daten aus der aktiven Tabelle in die temporäre Tabelle.
- Ersetzung der aktiven Tabelle durch die temporäre Tabelle und Schreiben der Tabellendefinition.
Bei der Generierung der temporären Tabelle wird die Tabellendefinition bezüglich des Datenbankschemas noch nicht verändert. In der Tabellendefinition wird jedoch vermerkt, dass eine temporäre Tabelle einer bestimmten Version generiert ist. Die temporäre Tabelle hat das Präfix „QC“ vor dem Namen der aktiven Tabelle.
Beispiel:
Wenn die aktive Tabelle ITEM heißt, dann heißt die dazugehörige temporäre Tabelle QCITEM.
Zusätzlich zu der temporären Tabelle gibt es auch eine Fehlertabelle, die das Schema der aktiven Tabelle hat. In die Fehlertabelle werden alle Datensätze geschrieben, die nicht in die temporäre Tabelle übernommen werden konnten.
Während der Übernahme der Daten aus der aktiven in die temporäre Tabelle, können die Daten durch ein Updateprogramm ergänzt bzw. verändert werden. Dieses Updateprogramm wird automatisch bei jeder Datenübernahme ausgeführt. Die Übernahme der Daten aus der aktiven Tabelle in die temporäre wird im Folgenden „konvertieren“ genannt.
Wenn der Inhalt der aktiven Tabellen in die neue temporäre Tabelle vollständig konvertiert worden ist, dann kann die aktive Tabelle ohne Datenverlust durch die temporäre Tabelle ersetzt werden. Das Aktivieren der temporären Tabelle verläuft wie folgt:
- Löschung der aktiven Tabelle.
- Umbenennung der temporären Tabelle in die aktive.
- Ersetzung der Tabellendefinition.
4.2.3 Beispiel für die Datenschema-Änderung
Das folgende Beispiel beschreibt, wie eine Datenschema-Änderung im ERP-System durchgeführt wird. In diesem Beispiel wird an dem Business Object „Item“ das neue Attribut „type“ hinzugefügt. Zunächst wurde aus der geänderten Objektbeschreibung eine neue Tabellenbeschreibung generiert.

Tabellenbeschreibung der neuen Version
Die Tabellendefinition und die aktive Tabelle der Datenbank, auf der die Datenschemaänderung durchgeführt werden soll, hat noch das alte Schema.
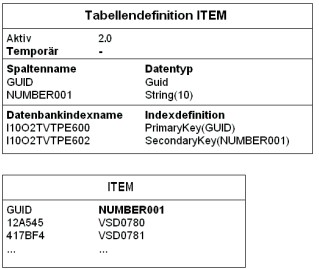
Tabellendefinition und aktive Tabelle vor der Generierung
Mithilfe der neuen Tabellenbeschreibung wird auf der Datenbank (z. B. durch crtbo, upgaps, rgzbo) eine temporäre Tabelle generiert. Diese temporäre Tabelle hat das Schema der neuen Tabellenbeschreibung. In die Tabellendefinition wird das neue Schema noch nicht übernommen, sondern zunächst nur die Versionsnummer der neuen Tabelle gespeichert.
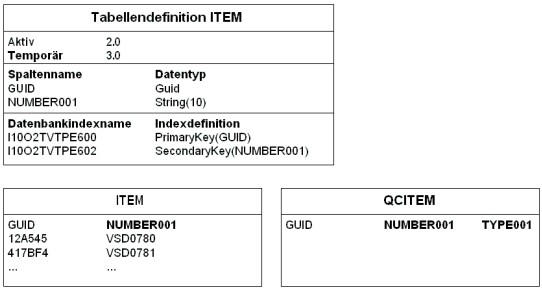
Tabellendefinition, aktive und temporäre Tabellen nach der Generierung der temporären Tabelle
Nach dem Erzeugen der temporären Tabelle werden die Daten (z. B. mit actbo, cnvbo, upgaps, rgzbo) aus der aktiven in die temporäre Tabellen übernommen.
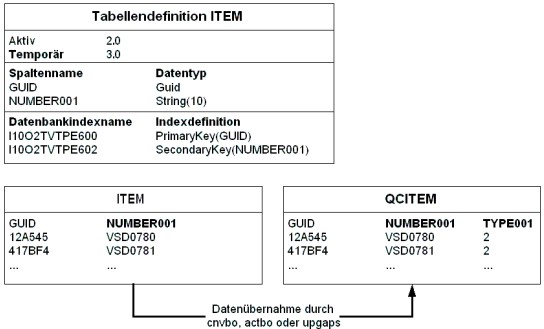
Übernahme der Daten aus der aktiven in die temporäre Tabelle
Die temporäre Tabelle enthält nach der Übernahme alle Daten der aktiven Tabelle und kann diese nun (z. B. durch actbo, rgzbo oder upgaps) ersetzen. Aus diesem Grund wird die aktive Tabelle gelöscht und die temporäre in die aktive umbenannt. Gleichzeitig wird die Tabellendefinition auf die aktuelle Version umgestellt.
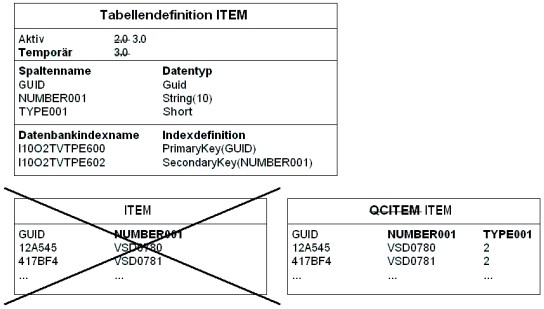
Ersetzen der aktiven durch die temporäre Tabelle
Nach der Datenschema-Änderung hat die Tabellendefinition und die Tabelle das Schema der neuen Tabellenbeschreibung.
Neue aktive Tabelle und Tabellendefinition
4.3 Zeitabhängigkeit
Business Objects können optional zeitabhängig sein. Bei zeitabhängigen Business Objects werden bei der Schemagenerierung des Business Objects automatisch die Attribute validFrom und validUntil angelegt.
- Das Attribut validFrom enthält den ersten Zeitpunkt zu dem die Business-Object-Instanz gültig ist.
- Das Attribut validUntil enthält den ersten Zeitpunkt zu dem die Business-Object-Instanz ungültig geworden ist.
- Das Attribut validFrom wird beim Generieren des Business Objects der Datenbank als Schlüsselattribut an alle eindeutigen Schlüssel angehängt.
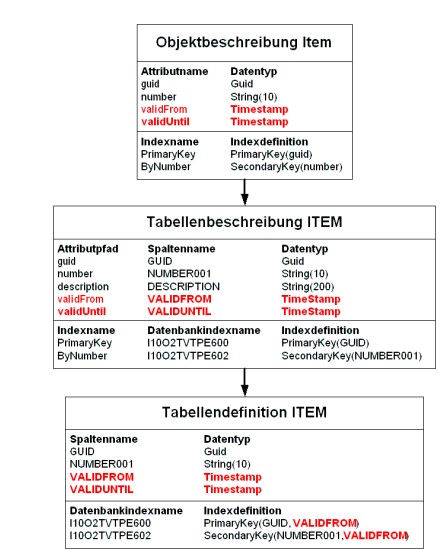
Beispiel für ein zeitabhängiges Business Object
Dadurch, dass das Attribut validFrom in die eindeutigen Schlüssel aufgenommen worden ist, kann im Allgemeinen nicht mehr geprüft von der Datenbank werden, ob ein eindeutiger Schlüssel wirklich eindeutig ist. Nicht zulässig ist, dass sich beispielsweise der Business Key in zwei Versionen eines identischen Business Objects unterschiedlich ist.
4.4 Objekt-Referenzen
Im Primärschlüssel eines Business Objects können Attribute beliebigen Typs und beliebiger Anzahl verwendet werden. Die Werte der Primärschlüssel-Attribute eines konkreten Business Objects werden im SAS als Bytefolge kodiert. Die Länge dieser Bytefolge hängt von der Anzahl und Größe der Primärschlüssel-Attribute ab und ist somit sehr unterschiedlich. Diese Bytefolge wird auch als der Primärschlüssel des Business Objects bezeichnet.
Business Objects können beliebige Schlüssel haben. Deshalb ist es nicht direkt möglich, aus einem Business Object auf ein beliebiges zum Entwurfszeitpunkt nicht bekanntes Business Object zu referenzieren. Die Möglichkeit zur Referenzierung könnte der Primärschlüssel des zu referenzierenden Business Objects sein. Dieser kann jedoch beliebig lang sein.
Die Objektreferenzen lösen dieses Problem. Wenn ein Primärschlüssel länger als eine definierte Länge ist, dann bildet eine Objektreferenz eine Indirektion. Als Referenz wird die Objektreferenz verwendet. Wenn die Objektreferenz aufgelöst werden soll, dann wird zu der Objektreferenz der originale Primärschlüssel ermittelt.
Wenn ein Objekt mit einem längen Primärschlüssel über eine Objektreferenz referenziert wird, dann wird der Primärschlüssel mit einer eindeutigen Identifikation in dem Business Object
com.cisag.sys.kernel.obj.ObjectReference
gespeichert. Objektreferenzen werden beispielsweise bei den NLS-Tabellen der lokalisierbaren Attribute verwendet.
Primärschlüssel und Objektreferenzen können weder mit Datenbankmitteln berechnet, noch aufgelöst werden. Aus diesem Grund ist es nicht möglich, einen Join mit SQL über eine Objektreferenz zu bilden.
Beim Design des Datenmodells sollte daher generell darauf geachtet werden, dass Business Objects möglichst kurze Primärschlüssel besitzen (z. B. eine Guid), um das Entstehen von Objektreferenzen zu vermeiden.
Hinweis:
Die Verwendung von Objekt-Referenzen im Anwendungs-Code ist verboten.
4.5 SBLOBs
Das ERP-System kennt zwei Typen von BLOBs (Binary Large OBjects):
- BLOB (Binary Large OBjects)
Der Inhalt eines BLOBs wird vom Persistenzdienst beim Laden des Business Objects vollständig in den Hauptspeicher geladen. Die BLOBs werden direkt in der Tabelle gespeichert, in der auch das Business Object gespeichert wird.
- SBLOB (Streamable Binary Large OBjects)
Hinweis:
Die Verwendung von SBLOBs im Anwendungs-Code ist verboten.
Der Inhalt eines SBLOBs wird vom Persistenzdienst nicht beim Laden des Business Objects, sondern in kleinen Blöcken erst beim Zugriff auf den Inhalt geladen. Die Inhalte der SBLOBs werden im separaten Business Object
com.cisag.sys.kernel.obj.SBLOBFragment
gespeichert. Die SBLOBs weisen Einschränkungen u. a. bzgl. des Transaktionsmanagements auf. Aus diesem Grund sollten SBLOBs nur innerhalb der ERP-System-System-Engine verwendet werden.
4.6 BLOB-Storage
Der Knowledge Store benötigt BLOBs unbeschränkter Länge. Diese BLOBs werden in der Tabelle BLOB_STORAGE gespeichert. Diese Tabelle gehört zu keinem Business Object. Sie können mit keiner öffentlichen Programmierschnittstelle direkt auf diese Tabelle zugreifen.
Wenn Sie den Knowledge Store intensiv nutzen, kann die Tabelle BLOB_STORAGE groß werden. Beachten Sie dies beim Einrichten ihres Datenbanksystems.
4.7 Lokalisierbare Attribute
Im ERP-Systemkann ein String-Attribut als lokalisierbar gekennzeichnet werden. In diesem Fall kann dieses Attribut nicht nur einen Wert speichern, sondern für jede konfigurierte Sprache der Datenbank eine Übersetzung. Jede ERP-System-Datenbank hat genau eine Primärsprache und beliebig viele Nebensprachen. Der Wert des Attributs in der Primärsprache kann besonders effizient gelesen und geschrieben werden. Die Werte in den Nebensprachen werden in gesonderten Business Object (NLS-Tabelle) gespeichert.
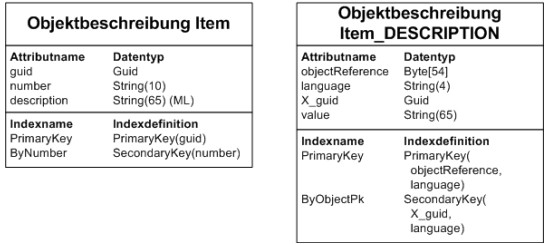
Beispiel für ein Objekt mit einem lokalisierbaren Attribut
Die NLS-Tabelle enthält für jeden Datensatz in der Haupttabelle und für jede Nebensprachen einen Datensatz mit der Übersetzung des lokalisierbaren Attributs. Die NLS-Tabelle wird von dem Tool crtbo automatisch generiert, wenn ein Business Object mit einem lokalisierbaren Attribut generiert wird. Die Attribute der generierten NLS-Tabelle leiten sich aus dem Hauptobjekt ab:
| Attribut | Erläuterung |
| objectReference | Die Objektreferenz ist eine eindeutige Identifikation des Hauptobjekts. |
| validFrom | Wenn das Hauptobjekt zeitabhängig ist, dann enthält auch die NLS-Tabelle ein Gültigkeitsdatum, um auch die Werte des lokalisierbaren Attributs zeitabhängig speichern zu können.
Wenn das Objekt nicht zweitabhängig ist, dann besitzt die NLS-Tabelle das Attribut validFrom nicht. |
| language | Die NLS-Tabelle enthält für jede Nebensprache der Datenbank eine Übersetzung des lokalisierbaren Attributs.
Das Attribut language legt fest, welche Übersetzung das Attribut value enthält. |
| X_pk1, …, X_pkn
Primärschlüssel des Hauptobjekts |
Der Primärschlüssel des Hauptobjekts wird zu jedem Wert eines lokalisierbaren Attributs in der NLS-Tabelle gespeichert, damit Joins zwischen der Haupttabelle und den NLS-Tabellen formuliert werden können. |
| value | Die Übersetzung des lokalisierten Attributs für die im Attribute language angegebene Nebensprache. |
Wenn eine neue Instanz eines Business Objects gespeichert wird, dann wird für jede Nebensprache der Datenbank je ein Datensatz in allen zu diesem Objekt gehörigen NLS-Tabellen angelegt. Wenn eine Business-Object-Instanz gelöscht wird, dann werden die zu diesem Objekt gehörigen Datensätze aus den NLS-Tabellen gelöscht. Je mehr Nebensprachen auf einer Datenbank angelegt sind, desto aufwendiger ist das Anlegen und Löschen von Business Objects mit lokalisierbaren Attributen.
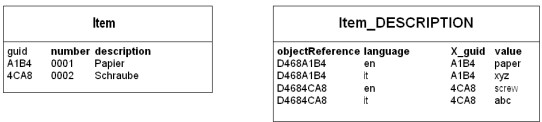
Beispiel für den Inhalt von einer Tabelle mit einem lokalisierbaren Attribut
Wenn das Business Object in der Primärsprache gelesen werden soll, so ist kein Zugriff auf die NLS-Tabelle notwendig. Jedoch wenn das Business Object in einer Nebensprache gelesen werden soll, dann wird für jedes lokalisierbare Attribut der Wert aus der zugehörigen NLS-Tabelle gelesen. Der lesende Zugriff auf Werte in der Nebensprache ist somit aufwendiger als in die Primärsprache.
4.8 Abbildung der ERP-System-Datentypen
Die Abbildung der Datentypen in Comarch ERP Enterprise hängt von dem verwendeten DBMS ab. Bei der Generierung der Datenbanktabelle aus der Tabellenbeschreibung werden die Datentypen der Spalten wie folgt auf der Datenbank abgebildet:
| Datentyp | Oracle 9i/10g | SQL-Server | DB2/400 | PostgreSQL |
| binary(l) | RAW(l) | VARBINARY(l) | VARCHAR(l) FOR BITDATA | BYTEA |
| blob | BLOB | VARBINARY(MAX) | BLOB(16M) | BYTEA |
| boolean | CHAR(1) | CHAR(1) | CHAR(1) | BOOLEAN |
| byte | NUMBER(3) | SMALLINT | SMALLINT | SMALLINT |
| char | NCHAR(1) | NCHAR(1) | GRAPHIC(1) CCSID 13488 | VARCHAR(1) |
| Clob | CLOB | NVARCHAR(MAX) | DBCLOB(16M) CCSID 13488 | TEXT |
| decimal(l,s) | NUMBER(l,s) | DECIMAL(l,s) | DECIMAL(l,s) | DECIMAL(l,s) |
| double | DOUBLE PRECISION | DOUBLE PRECISION | DOUBLE PRECISION | DOUBLE PRECISION |
| float | FLOAT | REAL | REAL | DOUBLE PRECISION |
| guid | RAW(16) | BINARY(16) | CHAR(16) FOR BIT DATA | UUID |
| int | NUMBER(10,0) | INT | INTEGER | INT |
| long | NUMBER(19,0) | BIGINT | BIGINT | BIGINT |
| short | NUMBER(5,0) | SMALLINT | SMALLINT | SMALLINT |
| String(l) | NVARCHAR2(l) | NVARCHAR(l) | VARGRAPHIC(l) CCSID 13488 | VARCHAR(l) |
| timestamp | NUMBER(17,0) | DECIMAL(17) | TIMESTAMP | TIMESTAMP |
| varstring(l) | NVARCHAR2(l) | NVARCHAR(l) | VARGRAPHIC(l) CCSID 13488 | VARCHAR(l) |
| valueset | NUMBER(5,0) | SMALLINT | SMALLINT | SMALLINT |
Der Datentyp „Timestamp“ kann bei Oracle 9i/10g und beim SQL-Server nicht direkt gespeichert werden, da die von diesem DBMS unterstützten Zeitdatentypen nicht die erforderliche Genauigkeit von 1ms haben. Ein Timestamp wird in diesen DBMS wie folgt als Zahl gespeichert:
yyyyMMddhhmmssSSSS
- y – Jahr
- M – Monat
- d – Tag im Monat
- h – Stunde am Tag
- m – Minute
- s – Sekunde
- S – Millisekunde
Der Datentyp „boolean“ wird auf allen DBMS als CHAR(1) gespeichert. Der Wert „0“ bedeutet false und „1“ true.
4.9 Zugriff mit SQL
Wenn Sie auf eine vom ERP-System verwaltete Datenbank mit SQL zugreifen, dann müssen Sie folgendes beachten:
- Die Namen der Tabellen und Attribute weichen auf der Datenbank von den im ERP-System verwendeten Namen ab.
- Die Abbildung der ERP-System-Datentypen auf die SQL-Datentypen ist datenbankspezifisch.
- Business Objects können zeitabhängig sein, somit kann ein Datensatz in mehrere Versionen vorliegen. Insbesondere bei Joins mit Stammdaten muss dieses beachtet werden.
- Die lokalisierbaren Attribute müssen manuell über den Primärschlüssel aufgelöst werden.
- Objektreferenzen können mit SQL nicht aufgelöst werden.
- SBLOBs können mit SQL nicht abgefragt werden.
Im Allgemeinen ist der Zugriff über den ERP-System-ODBC-Treiber oder durch eine ERP-System-Anwendung deutlich komfortabler als der direkte Zugriff mit SQL.
4.9.1 Änderungen auf einer Datenbank
Mit SQL sollten nur lesende Zugriffe auf einer Datenbank gemacht werden. Wenn die Daten einer Datenbank geändert werden und ein SAS läuft, dann stimmen möglicherweise die Daten im Cache des SAS nicht mehr mit den Daten auf der Datenbank überein. Das kann zu Inkonsistenzen und damit zu Datenverlusten führen. Außerdem sind die Datenmodelle von den meisten Business Entitys so komplex, dass die Folgen und Abhängigkeiten einer Änderung nicht immer auf den ersten Blick erkennbar sind. Von Änderungen mit SQL auf einer ERP-System-Datenbank wird dringend abgeraten. Falls manuelle Änderungen unumgänglich sind, können Sie die Anwendung „OQL-Anweisungen“ verwenden.
4.9.2 Rücksicherungen
Eine Datenbank sollte immer als ganzes gesichert und zurückgesichert werden. Die Rücksicherung von einzelnen Tabellen wird aufgrund des komplexen Datenmodells nicht empfohlen, da die Abhängigkeiten der zurück gesicherten Tabelle im Allgemeinen nicht bekannt sind.
Wenn nach der Sicherung, die zurückgesichert werden soll, Softwareaktualisierungen mit Datenmodell-Änderungen in das System eingespielt worden sind, dann können Datenbanken nicht einzeln zurückgesichert werden. Außerdem muss beachtet werden, dass der Inhalt der OLAP-Datenbank aus der OLTP-Datenbank berechnet wird. Eine Rücksicherung der OLTP-Datenbank ohne eine Rücksicherung der OLAP-Datenbank kann zu inkonsistenten Zuständen führen.
Hinweis:
Ein ERP-System ist immer als Ganzes, d. h. mit allen Datenbanken und dem Dateisystem zu sichern und zurückzusichern.
4.10 Datenbankinformationen
Die Konfiguration einer Datenbank wird in der Konfigurations-Datenbank gespeichert. Bestimmte Konfigurationsdaten haben jedoch Auswirkungen auf den Inhalt der Datenbank und können daher nicht oder nur mit einer Reorganisation auf der Datenbank geändert werden. Das Duplikat dieser Konfigurationsdaten sind die Datenbankinformationen. Die Datenbankinformationen umfassen die folgenden Daten:
| Daten | Erklärung |
| System | Das System zu dem die Datenbank gehört, wird in den Datenbankinformationen gespeichert. Bis auf die Konfigurations-Datenbank gehört jede Datenbank zu genau einem System. |
| Inhalt | Der Inhalt einer Datenbank kann und darf sich nie ändern.
Der Inhalt einer Datenbank beeinflusst u. a. das Datenbankschema. |
| ERP-System-Treiber | Abhängig vom ERP-System-Treiber werden die Daten unter Umständen anders in die Datenbank geschrieben. Ein Wechsel des ERP-System-Treibers bei einer existierenden Datenbank ist nicht erlaubt. |
| Primärsprache | Der Text eines lokalisierbaren Attributs in der Primärsprache steht in dem Business Object.
Das Ändern der Konfiguration ohne eine Reorganisation der Übersetzungen würde eine falsche Übersetzung der Primärsprache anzeigen. |
| Nebensprachen | Der Übersetzungen eines lokalisierbaren Attributs in den Nebensprachen steht in der zugehörigen NLS-Tabelle.
Das Ändern der Konfiguration ohne eine Reorganisation der Übersetzungen führt dazu, dass zu viele bzw. zu wenige Übersetzungen in der NLS-Tabelle existieren. Auf der OLTP-Datenbank sind neben den Nebensprachen der OLTP-Datenbank selbst auch die Nebensprachen der Repository-Datenbank abgelegt. Die Nebensprachen der Repository-Datenbank werden für die Business Objects mit der Datenart Konfiguration-Stammdaten (Anzeige) verwendet, deren mehrsprachige Attribute in der Anzeigesprache dargestellt werden sollen. |
4.11 DBMS-spezifische Einschränkungen
Das ERP-System soll auf allen DMBS die gleiche Funktionalität bieten. Da die DBMS sich in ihrem Funktionsumfang unterscheiden, muss das ERP-System diese Unterschiede verbergen oder als Einschränkung für generell unabhängig vom DBMS prüfen. Nur so kann gewährleistet werden, dass das ERP-System sich auf allen DBMS identisch verhält.
4.11.1 Einschränkungen durch Oracle
1000 Spalten pro Join-Clausel
Die Summe aller Spalten aller in einer Join-Klausel eines SELECT-Statement verwendeten Tabellen muss kleiner als 1000 sein.
Beispiel:
A ist Tabelle mit 400 Spalten, B eine Tabelle mit 500 Spalten und C eine Tabelle mit 300 Spalten. So überschreitet das Statement
SELECT … FROM A JOIN (B JOIN C ON …) ON …
die 1000 Spaltengrenze, während das Statement
SELECT … FROM A, B, C
diese Grenze nicht überschreitet.
Für Oracle werden die SQL-Statements vom ERP-System so generiert, dass das 1000 Spalten in einer Join-Klausel deutlich seltener erreicht werden und somit deutlich seltener zu Fehlern führen.
Maximum von 4000 Bytes pro Attribut
Ein Attribut darf bei maximal 4000 Bytes groß sein. Das bedeutet, dass Strings maximal 2000 Zeichen lang sein dürfen.
Der leere String ist identisch mit NULL
Der leere String ist bei Oracle identisch mit NULL. Das ist anders als auf jedem anderen DBMS und führt zu einem anderen Abfrageverhalten bei leeren Strings.
Beispiel:
T ist eine Tabelle mit dem Schema und Inhalt:
create table T(a varchar(10) primary key, b varchar(10));
insert into T values (’1’,’a’);
insert into T values (’2’,’’);
Die Anfrage
select * from T where b=’’;
liefert in Oracle eine leere Ergebnismenge. Auf allen anderen Datenbanken liefert diese Anfrage die Zeile 2 zurück.
Um diesen Fehler zu beheben wird bei allen Datenbanken statt des Leerstrings ein Leerzeichen geschrieben. Das ERP-System bildet den Leerstring transparent auf das Leerzeichen ab, so dass der Entwickler nichts von dieser Ersetzung merkt und diese auch nicht beeinflussen kann.
Das ERP-System entfernt bei Business Objects alle angehängten Leerzeichen (rtrim). Somit ist es nicht möglich, den String mit einem Leerzeichen aus einer Anwendung zu schreiben. Diese Ersetzung wird auf allen Datenbanken durchgeführt, um auf allen Datenbanken ein identisches Verhalten zu erreichen.
Spürbar wird diese Ersetzung jedoch, wenn beispielsweise LIKE verwendet wird. Ausdrücke wie LIKE ’_’ finden auch die Leerzeichen und damit auch die Zeilen, die das ERP-System als Leerstring geschrieben hat.
Wenn der Leerstring in OQL als Konstante verwendet wird, dann wird dieser durch das Leerzeichen ersetzt. D. h. a=’’ wird ersetzt durch a=’ ’ und a LIKE ’’ wird ersetzt durch a LIKE ’ ’.
Der ERP-System-ODBC-Treiber benutzt ebenfalls den Persistenzdienst des ERP-Systems. Da die Ersetzung in dem Persistenzdienst stattfindet, ist die Ersetzung für den ODBC-Treiber genauso transparent wie für die Anwendungen.
Bei direkten Zugriffen auf eine ERP-System-Datenbank per SQL durch andere Programme wird diese Ersetzung sichtbar. Die Behandlung von Leerstrings muss bei solchen Zugriffen genauso berücksichtigt werden, wie die Abbildung von Timestamps, Texten, Guids, Blobs, usw. Alle diese Datentypen haben eine teilweise komplexe und nur durch das ERP-System einfach auflösbare Darstellung in der Datenbank.
Kein automatisches RTRIM auf Stringattributen
Im Gegensatz zu den anderen DBMS unterscheidet ORACLE bei Vergleichen Zeichenketten, die sich nur in nachstehenden Leerzeichen unterscheiden. Das ist unproblematisch, da nachstehende Leerzeichen in Stringattributen prinzipiell abgeschnitten werden.
4.11.2 Einschränkungen durch den SQL-Server
Maximum von 8192 Bytes pro Zeile
Die Summe der Größe aller Spalten einer Zeile ohne die VARCHAR-Spalten darf maximal 8192 Bytes groß sein. Wenn eine Zeile mit den VARCHAR-Spalten größer als 8192 Bytes ist, dann wird mehr als ein Block zum Speichern dieser Zeile verwendet und die Zugriffzeiten auf die Tabellen werden schlechter. Bei der Generierung der Tabellenbeschreibung wird die Summengröße der Spalten geprüft und ggf. eine Warnung oder eine Fehlermeldung erzeugt.
4.11.3 Einschränkungen durch die DB2/400
Transaktionen sind nicht vollständig isoliert
Bei der DB2 für die iSeries werden Löschungen und bestimmte Änderungen auch dann für alle anderen Transaktionen sichtbar, wenn die ändernde Transaktion noch nicht mit commit abgeschlossen ist.
Im Gegensatz zu anderen Datenbanken schreibt die iSeries alle Änderungen sofort in die Tabelle und speichert den alten Stand in das Journal. Bei Rollback stellt die iSeries die Daten mithilfe des Journals wieder her. Wenn Datensätze geändert oder eingefügt werden, dann wird für diese Datensätze eine Sperre angefordert. Alle Selektionen finden auf der bereits geänderten Tabelle statt und nutzen das Journal nicht.
Beispiel:
Ein Datensatz hat ursprünglich den Wert A und dieser Wert wird innerhalb einer Transaktion auf B geändert. Dann kann keine andere Transaktion mehr den Datensatz mit dem Wert A finden. Wenn der Datensatz mit dem Wert B gesucht wird, dann läuft die suchende Transaktion auf eine Sperre und muss warten bis die ändernde Transaktion abgeschlossen ist.
Folglich gibt die iSeries nie falsche Daten an das ERP-System zurück. Wenn aber ändernde Transaktionen offen sind, dann werden nicht alle Daten gefunden. Im ERP-System werden aus diesem Grund alle Löschungen so spät wie irgend möglich ausgeführt. Besonders kritische Stellen werden in den Anwendungen explizit durch logische Sperren gesichert, so dass das Verhalten der iSeries wieder entschärft wird.
Diese Maßnahmen lösen das Problem jedoch nicht wirklich, sondern nur die Wahrscheinlichkeit mit der inkonsistente Daten gelesen werden, wird kleiner. Somit bleibt beim Einsatz einer iSeries im Produktivbetrieb ein geringes Restrisiko für inkonsistente Lesezugriffe.
4.11.4 Einschränkungen durch PostgreSQL
Alle SQL-Identifier in Anführungszeichen
PostgreSQL wandelt alle SQL-Identifier, wie Tabellennamen, Spaltennamen und Indexnamen, in Kleinbuchstaben um. Comarch ERP Enterprise verwendet jedoch durchgängig Großbuchstaben für SQL-Identifier. Aus diesem Grund müssen alle SQL-Identifier in doppelte Anführungszeichen eingeschlossen werden.
Feste Länge des GUID-Datentyps
Der GUID-Datentyp hat in PostgreSQL eine feste Länge von 16 Bytes. Damit können in PostgreSQL keine GUIDs mit einer kürzeren Länge gespeichert werden. GUIDs mit einer kürzeren Länge als 16 Bytes sind jedoch – unabhängig von PostgreSQL – fehlerhaft.
Datenbankname im Zugriffspfad
Der Name der Datenbank muss im Zugriffspfad auf eine PostgreSQL-Datenbank angegeben werden:
jdbc:postgresql://<host>:<port>/<dbName>
Beispiel:
jdbc:postgresql://pgsql.xyz.com:5432/ABC12301
4.12 Groß-/Kleinschreibung
Über die ERP-System-Property com.cisag.sys.kernel.caching.CaseSensi-tivityMode können Sie die Behandlung der Groß-/Kleinschreibung beeinflussen.
Die möglichen Werte sind:
- 1 = In allen Textfeldern kann Groß-/Kleinschreibung eingegeben und gesucht werden.
- 2 = Die Suche nach Beschreibungen sind groß-/kleinschreibungs-unabgängig.
- 3 = Die Suche nach Identifikationen und Bezeichnungen ist groß-/kleinschreibungs-unabgängig.
- 4 = In Identifikationsfelder können nur noch Großbuchstaben eingegeben werden.
Der Standardwert bei der Installation ist Case-Sensitivity-Mode 4.
Bei Case-Sensitivity-Mode 3 oder 4 werden alle Identifikationsfelder, bis auf die in der Java-Klasse com.cisag.app.general.log.CaseSensitivityRegistry erfassten Ausnahmen, in Großbuchstaben gesucht. Voraussetzung dafür ist, dass auf der Datenbank die Inhalte aller Identifikationsfelder bereits in Großbuchstaben vorliegen. Bei der Suche werden alle Suchmuster vor dem Ausführen auf der Datenbank in Großbuchstaben umgewandelt. Damit muss die Datenbank beim Ausführen der Anfrage die Groß-/Kleinschreibung nicht mehr ändern. So kann die Datenbank beim Ausführen der Anfragen somit Indexe auf den Identifikationsfeldern verwenden.
Wenn Sie bei einem System nachträglich den Case-Sensitivity-Mode 3 oder 4 einstellen, ist es möglich dass Datensätze mit Kleinschreibung in einem Identifikationfeld gibt. Diese Datensätzen können mit den Suchen nicht gefunden werden. Stellen Sie daher sicher, dass alle Identifikationsfelder in allen Tabellen nur Großbuchstaben enthalten bevor Sie Case-Sensitivity-Mode 3 oder 4 einstellen.
Wenn Case-Sensitivity-Mode 3 oder 4 aktiv ist, können in Identifikationsfelder nur Großbuchstaben eingeben werden. In diesem Fall können Sie keine Kleinbuchstaben in Identifikationsfeldern abspeichern.
Bei Case-Sensitivity-Mode 2, 3 oder 4 werden alle Beschreibungen, bis auf die in der Java-Klasse com.cisag.app.general.log.CaseSensitivityRegistry erfassten Ausnahmen, in groß-/kleinschreibungs-unabhängig gesucht. Dafür werden bei der Ausführung der Anfrage das Suchmuster sowie das Datenbankfeld in Großbuchstaben umgewandelt. Die Datenbank kann beim Ausführen der Suchanfrage voraussichtlich keinen Index für die Einschränkung auf Beschreibungsfeldern verwenden. Daher wird, wenn auf ein Beschreibungsfeld Teil in einem Index enthalten ist, dieses Feld nicht groß-/kleinschreibungs-unabhängig gesucht, damit die Datenbank den Index bei den Suchen nutzen kann.
4.13 Sprachspezifische Einschränkungen
Die DBMS arbeiten mit unterschiedlichen Sortieralgorithmen, die mit jeweils unterschiedlichen Sortiertabellen (Collations) arbeiten. Daraus folgt, dass jedes DBMS Zeichenketten für eine Sprache im Detail anders sortiert. Für eine zu verwendende Datenbanksortierung muss festgestellt werden, ob diese zum ERP-System kompatibel ist.
Eine Datenbanksortierung ist zum ERP-System kompatibel, wenn sie eine eindeutige Ordnung der Unicode-Zeichen für Vergleiche, Gruppierungen und Sortierungen von Zeichenketten besitzt. Dabei soll die gewählte Sortierung für eine Sprache möglichst entsprechend den Benutzererwartungen sortieren.
4.13.1 Oracle, SQL-Server und DB2/400
In der nachfolgenden Tabelle sind die empfohlenen Default-Datenbankeinstellungen bzgl. des verwendeten DBMS und der für die Datenbank im ERP-System konfigurierten Hauptsprache aufgeführt. Für eine Datenbank der DBMS DB2/400 und Oracle werden diese Einstellungen automatisch vom ERP-System vorgenommen, eine MS-SQL-Server-Datenbank muss bei der Erstellung entsprechend konfiguriert werden.
| Sprache | DBMS | ||
| DB2/400
(LANGID, sort table) |
MS-SOL-Server
(Collation) |
Oracle
(NLS_SORT) |
|
| Deutsch | DEU, QSYS/QLA10111U | Latin1_General_CS_AS | GERMAN |
| Englisch | ENG, QSYS/QLA1011DU | Latin1_General_CS_AS | WEST_EUROPEAN |
| Französisch | FRA, QSYS/QLA10129U | French_CS_AS | FRENCH |
| Italienisch | ITA, QSYS/QLA10118U | Latin1_General_CS_AS | ITALIAN |
| Kroatisch | HRV, QSYS/QLA20366U | Croatian_CS_AS | CROATIAN |
| Niederländisch | NLD, QSYS/QLA10025U | Latin1_General_CS_AS | DUTCH |
| Polnisch | PLK, QSYS/QLA20366U | Polish_CS_AS | POLISH |
| Russisch | RUS, QSYS/QRUS0401U | Cyrillic_CS_AS | RUSSIAN |
| Slowakisch | SKY, QSYS/QLA20366U | Slovak_CS_AS | SLOVAK |
| Slowenisch | SLO, QSYS/QLA20366U | Slovenian_CS_AS | SLOVENIAN |
| Tschechisch | CSY, QSYS/QLA20366U | Czech_CS_AS | CZECH |
| Türkisch | TRK, QSYS/QTRK0402U | Turkish_CS_AS | TURKISH |
| Ungarisch | HUN, QSYS/QLA20366U | Hungarian_CS_AS | HUNGARIAN |
| Chinesisch | CHS, QSYS/QBCHS04B0U | Chinese_Simplified_Pinyin_100_BIN2 | BINARY |
Für diese aufgeführten Einstellungen werden mit dem Installationsmedium passende ERP-System-Collations ausgeliefert. Diese werden benutzt, um für Sortierungen von Zeichenketten im Hauptspeicher nachzubilden, so dass der Benutzer möglichst keinen Unterschied zwischen den Sortierungen bemerkt.
4.13.2 PostgreSQL
PostgreSQL kennt keine Sortiertabellen für spezielle Sprachen. Die Sortierung basiert auf dem jeweils eingesetzten Betriebssystem. Das bedeutet, dass die Sortierung in der Datenbank in den unterschiedlichen Windows- und Linux-Versionen jeweils unterschiedlich sein kann.Comarch ERP Enterprise verwendet im Application-Server die Java-Standard-Sortierung für die jeweilige Primärsprache der Datenbank. Abweichungen können entstehen zwischen der Betriebssystem-spezifischen Datenbanksortierung und der Sortierung im Application-Server. Je größer die Abweichungen sind, desto wahrscheinlicher werden Inkonsistenzen in Comarch ERP Enterprise, z. B. beim Blättern in nicht anpassbaren Cockpits.
Hinweis:
Achten Sie darauf, dass die Datenbanksortierung und die Primärsprache der Datenbank zusammenpassen. Sie sollten die Unix-Sortierungen für die Datenbank wählen. Beispielsweise „de_DE“ für Deutsch. Die Unix-Sortierung ist ähnlich der Java-Sortierung. Verwenden Sie nur case-sensitive Sortierungen und keinesfalls case-insensitive Sortierungen.
4.14 Datenbank-Failover
Die meisten Datenbank-Management-Systeme (DBMS) haben Failover-Mechanismen. Das bedeutet, dass mehrere Datenbankinstanzen parallel auf der gleichen bzw. auf einer gespiegelten Datenbasis laufen. Wenn eine Datenbankinstanz aufgrund eines Fehlers nicht mehr zur Verfügung steht, so kann eine andere Datenbankinstanz die Aufgaben der ausgefallenen Instanz übernehmen. Es gibt häufig auch innerhalb eines DBMS mehrere Möglichkeiten wie das Failover für ein Datenbanksystem konfiguriert werden kann. Die von Comarch ERP Enterprise unterstützten Konfigurationen finden Sie in der Installationsdokumentation.
Weitere Informationen zum Datenbank-Failover finden Sie in der Dokumentation „Hochverfügbarkeit“.
4.15 Transaction-Isolation-Level
Das ERP-System verwendet für alle Datenbankverbindungen mindestens den Transaction-Isolation-Level „READ_COMMITTED“. Mit diesem Transaction-Isolation-Level gibt das Datenbanksystem bei einer Anfrage nur Daten zurück, die durch eine erfolgreich abgeschlossene Transaktion (mit Commit) in die Datenbank geschrieben wurden. Daten aus noch nicht abgeschlossenen Transaktionen sind in diesen Verbindungen nicht sichtbar.
Bei interaktiven Dialog-Suchen werden im Allgemeinen relativ komplexe Anfragen gestellt. Vom Anfrageergebnis werden nur sehr wenige Daten durch ein Programm weiterverwendet. Meist sind das die Primärschlüssel des ausgewählten Business Objects. Alle Werte, die aus einer Dialog-Suche kommen, werden durch die Anwendung geprüft, da das Ergebnis der Suche immer veraltet und damit inkonsistent sein kann. Da alle Verwender von Dialog-Suchen damit rechnen müssen, dass das Ergebnis veraltet und inkonsistent ist, kann bei interaktiven Suchen auf „READ_COMMITTED“ verzichtet werden.
Das ERP-System verwendet aus diesem Grund bei der iSeries und beim MS-SQL-Server den Transaction-Isolation-Level „READ_UNCOMMITTED“. Komplexe Anfragen können auf diesen DBMS mit dem Transaction-Isolation-Level „READ_UNCOMMITTED“ schneller verarbeitet werden als mit dem Transaction-Isolation-Level „READ_COMMITTED“.