
1 Kurzbeschreibung
Im Rahmen der Entwicklung oder für Adaptierungen kann es notwendig werden, die Laufzeit eines Anwendungsprogramms zu verbessern. Dieses Dokument beschreibt insbesondere die Optimierungsmöglichkeiten in Anwendungsprogrammen beim Zugriff auf den Persistenzdienst.
2 Zielgruppe
Die Zielgruppe dieses Dokuments sind Anwendungsentwickler.
3 Begriffsbestimmung
O-Notation
Wenn man die Leistung eines Systems verbessern will, muss man wissen, welche Operation wie viel Zeit kostet. Die Zeit, die eine Operation kostet, ist jedoch häufig abhängig von dem Umfang der betrachteten Daten. Aus diesem Grund benutzt man die O-Notation, um die Komplexität einer Operation abzuschätzen. Die vollständige mathematisch korrekte Definition können Sie in der entsprechenden Grundlagenliteratur nachlesen.
Die Menge O(f(n)) umfasst alle Funktionen g(n) für die es Konstanten c und n0 gibt, so dass für alle m>n0 gilt 0<=g(m)<c*f(m).
Wir benutzen im Wesentlichen die folgenden Mengen:
- O(c) für alle konstanten Funktionen
- O(log(n))
- O(n)
- O(n*log(n))
Es wird von den folgenden Voraussetzungen ausgegangen:
- Ein Zugriff auf eine Hash-Tabelle hat einen konstanten Zeitaufwand, das heißt ist in O(c). Obwohl im allgemeinen Fall der Aufwand O(n) ist, aber aufgrund der Annahme, dass die verwendete Hash-Funktion gut ist und der Voraussetzung, dass der Füllungsgrad der Tabelle auf 75 % beschränkt ist, ist diese Abschätzung gerechtfertigt.
- Ein Zugriff auf einen DB-Index hat einen Zeitaufwand in O(log(n))
- Das Lesen aller Sätze einer Tabelle hat einen Zeitaufwand von O(n)
4 Grundlagen
Wenn ein Programm bzw. eine Funktion eines Programms mehr Zeit benötigt, als für diese Funktion akzeptiert werden kann, muss dieses Problem behoben werden. Als erstes sollten Sie die Konfiguration eines Systems prüfen:
- Prüfen Sie, ob der Datenbank und dem Application-Server genügend realer Hauptspeicher zur Verfügung steht.
- Prüfen Sie, ob die Caches der Datenbank und des Application-Servers eine ausreichende Größe haben.
- Prüfen Sie, ob die von Ihnen verwendete Hardware den Anforderungen entsprechen kann.
Wenn Sie alle Möglichkeiten ausgeschöpft haben, um das System durch Änderungen an der Systemkonfiguration zu beschleunigen, kann das Problem in den verwendeten Anwendungen liegen.
Die im Folgenden verwendeten Zeit- und Größenangaben dienen zum Verdeutlichen der Zusammenhänge und haben keinen direkten Bezug zu einem realen System. Siehe Dokumentation System-Checklist.
4.1 Richtlinien
Anwendungen in Semiramis müssen massendaten- und leistungsfähig sein. Das bedeutet, dass ein Programm große Datenmengen in einer für den Anwender akzeptablen Zeit verarbeiten können muss, ohne dass dieses Programm übermäßig viel Hauptspeicher oder andere vitale Ressourcen verbraucht.
Die grundlegenden Regeln, die bei der Entwicklung von leistungsfähigen Programmen beachtet werden sollten, werden im Folgenden erklärt. Komplexere Sachverhalte lassen sich jedoch nicht in einfachen Regeln formulieren. Aus diesem Grund muss nach der Fertigstellung eines Programms dessen Ressourcenbedarf gemessen werden. Gegebenenfalls müssen daraufhin Schwachpunkte im Programm korrigiert werden.
4.1.1 Optimierungsziele
Alle Semiramis Application Server (SAS) greifen auf ein gemeinsames Datenbanksystem (DBS) zu. Das DBS hat eine nach oben begrenzte Leistungsfähigkeit. Wenn das DBS eine oder mehrere komplexe Anfragen ausführt, dann dauert auch die Ausführung einfacher Anfragen deutlich länger als bei einem unbelasteten DBS.
Beispiel
Wenn eine Anfrage nur 10 ms CPU-Zeit braucht, dann braucht die Anfrage bei 0 % CPU-Auslastung im DBS 10 ms. Bei 90 % CPU-Auslastung im DBS benötigt die gleiche Anfrage ca. 100 ms.
Ein Ziel der Leistungsoptimierung ist, dass komplexe Datenbankanfragen mit einer Laufzeit von mehr als 2-3 Sekunden im Normalbetrieb von Semiramis nicht oder nur selten vorkommen.
Ebenso wie komplexe Datenbankanfragen können auch einfache Datenbankanfragen zu Problemen führen, wenn diese zu häufig ausgeführt werden. Die vielfache Ausführung einer einfachen Datenbankanfrage hat den gleichen Effekt wie das Ausführen einer komplexen Datenbankanfrage.
Beispiel
Wenn eine Datenbankanfrage, die 10 ms CPU-Zeit braucht, 90 mal pro Sekunde ausgeführt wird, dann hat das DBS 90 % CPU-Auslastung.
Ein weiteres Ziel ist daher, auch die Anzahl der einfachen Datenbankanfragen zu reduzieren.
Wenn das DBS ausgelastet ist, dann werden, wie oben beschrieben, alle Operationen im gesamten Semiramis-System langsam. Das bedeutet, dass bei einem ausgelasteten DBS auch Operationen, die eigentlich ausreichend schnell sind, für den Benutzer unerträglich langsam werden. Das bedeutet, dass die Operation, die auffällig langsam ist, nicht immer die Ursache für die schlechte Leistung ist. Insbesondere, wenn die Benutzer von einem stark wechselnden Verhalten sprechen, d. h. mal ist alles schnell und mal ist alles langsam, dann liegt nahe, dass die Ursache nicht bei der direkt beobachteten Operation liegt.
Beispiel:
Bei einem Kunden dauert das Übernehmen einer Auftragsposition 0,5 s. Das Drucken eines Lieferscheins erzeugt 60 Sekunden Datenbanklast. Während des Drucks eines Lieferscheins dauert das Übernehmen einer Auftragsposition 5 Sekunden. Die Benutzer beschweren sich über die schlechte Leistung beim Erfassen von Auftragspositionen, da dies eine essenzielle Aktion für die meisten Benutzer ist.
Genauso wie die Last des DBS das gesamte System ausbremst, genauso bremst die CPU-Last auf einem SAS alle angemeldeten Benutzer auf diesem SAS aus. CPU-intensive Berechnungen sollten daher in Dialog-Anwendungen vermieden werden.
Der Hauptspeicher in jedem SAS ist beschränkt. Eine Dialog-Anwendung darf daher auch nur eine beschränkte Menge an Hauptspeicher verwenden.
Die Betriebssysteme und Datenbank-Management-Systeme verhalten sich bei Last sehr unterschiedlich. Einige Systeme verkraften Hochlastphasen besser als andere Systeme. Generelle Aussagen, wie sich Hochlast auf das Antwortverhalten eines Systems auswirkt, können daher allgemeingültig nicht getroffen werden.
4.1.2 Erst messen und prüfen, dann ändern
Um die Leistungsfähigkeit eines Programms, bei dessen Entwicklung die grundlegenden Regeln eingehalten worden sind, zu verbessern, muss prinzipiell zuerst eine Messung und erst danach eine Änderung des Programms erfolgen. Solange nicht bekannt ist, wo die kritische Ressource (Hauptspeicher oder Laufzeit) verbraucht wird, lohnt es sich nicht, etwas zu optimieren.
Beispiel:
Eine Funktion f teilt sich in die folgenden Teile:
- Daten sammeln (benötigt 60 % der Gesamtlaufzeit).
- Daten berechnen (benötigt 5 % der Gesamtlaufzeit).
- Daten schreiben (benötigt 20 % der Gesamtlaufzeit).
- Daten anzeigen (benötigt 15 % der Gesamtlaufzeit).
Eine Optimierung, die die Laufzeit einer Teilfunktion halbiert, hat jeweils die folgenden Effekte:
- Wird die Zeit für das Daten-Sammeln halbiert, reduziert sich die Gesamtlaufzeit um 30 %.
- Wird die Zeit für das Daten berechnen halbiert, reduziert sich die Gesamtlaufzeit um 2,5 %.
- Wird die Zeit für das Daten schreiben halbiert, reduziert sich die Gesamtlaufzeit um 10 %.
- Wird die Zeit für das Daten berechnen halbiert, reduziert sich die Gesamtlaufzeit um 7,5 %.
Aus dem obigen Bespiel folgt, dass, wenn die Gesamtlaufzeit der Funktion f zu lang ist, eine Optimierung bei der Teilfunktion „Daten sammeln“ den größten Effekt hat. Eine Optimierung der Teilfunktion „Daten berechnen“ wird der Benutzer hingegen kaum merken.
Dieses Bespiel zeigt, dass es sehr wichtig ist, zunächst den Teil eines Programms zu finden, der den größten Ressourcenverbrauch hat. Bei diesem Programmteil sollten Sie mit der Optimierung beginnen. Je besser Sie die Funktion mit dem höchsten Ressourcenverbrauch eingrenzen können, umso gezielter können Sie die Optimierung durchführen.
4.1.3 Datenbankzugriff überprüfen
Bei komplexen Programmen sind repräsentative Testdaten für eine aussagekräftige Messung notwendig. Das bedeutet, dass die Testdaten im Umfang und Aufbau dem Anwendungsfall entsprechen müssen, der optimiert werden soll. Die Erzeugung von Testdaten kann unter Umständen relativ aufwendig sein. Es empfiehlt sich, sofern dies möglich ist, auf reale Daten zurückzugreifen. Wenn ein Performance-Problem bei einem Kunden besteht, sollte möglichst eine Kopie der OLTP-Datenbank mit den realen Daten auch an das Entwicklungssystem des Partners angehängt werden. Zu kleine oder zu einfach strukturierte Testdaten verfälschen die Messergebnisse und können dazu führen, dass die falschen Teilfunktionen optimiert werden.
Beachten Sie bei Messungen auf dem Entwicklungssystem, dass im Entwicklungssystem die OLTP-Datenbank meist nicht die Größe der OLTP-Datenbank im Produktivsystem hat und daher Datenbankanfragen ein anderes Laufzeitverhalten als im Produktivsystem haben. Auch ist die Last für die Datenbank und die Application-Server im Entwicklungssystem deutlich geringer als im Produktivsystem. Im Entwicklungssystem arbeiten nur wenige Entwickler zur gleichen Zeit auf dem System, während im Produktivsystem viele Benutzer unterschiedliche Operationen gleichzeitig ausführen. Im Entwicklungssystem stehen daher die Caches im Application-Server und in der Datenbank fast exklusiv für eine Operation zur Verfügung, während im Produktivsystem sich diese Caches von vielen aktiven Sessions geteilt werden müssen. Aus diesem Grund sind Zeitmessungen auf dem Entwicklungssystem immer nur mit Vorsicht zu bewerten.
Die Datenbankmanagementsysteme (DBMS) erstellen zu jeder SQL-Anweisung einen Zugriffsplan. Ein Zugriffplan beschreibt, wie das DBMS bei der Abarbeitung der SQL-Anweisung auf Tabellen und Indexe zugreift. Alle DBMS bieten Ihnen die Möglichkeit, den Zugriffsplan einer SQL-Anweisung grafisch anzuzeigen. Insbesondere, wenn eine bestimmte SQL-Anweisung eine besonders lange Laufzeit hat, müssen Sie den Zugriffsplan der SQL-Anweisung kontrollieren. Nutzen Sie die Dokumentation des DBMS, um Zugriffspläne abzufragen und zu interpretieren.
Der Optimierer eines DBMS arbeitet meist kostenbasiert. Das bedeutet, dass der Optimierer aufgrund von statistischen Informationen versucht, die Kosten für die Ausführung einer SQL-Anweisung abzuschätzen. Wenn mehrere alternative Zugriffspläne zur Verfügung stehen, wählt der Optimierer den Zugriffsplan mit den geringsten Kosten aus. Es kann daher sein, dass, obwohl passende Indexe existieren, diese nicht benutzt werden, da die Kosten für den Zugriff mit Index höher sind als für den Zugriff ohne Index.
Fast jedes DBMS hat eine Monitoring-Funktion, mit der der Ressourcenverbrauch der SQL-Anweisungen, die in einem bestimmten Zeitraum ausgeführt wurden, protokolliert werden kann. Nutzen Sie diese Funktion, wenn Sie Lasttests durchführen. Wenn auf einem Produktivsystem ein Performance-Problem besteht, können Sie diese Funktion auch nutzen, müssen jedoch dabei unbedingt sicherstellen, dass durch die Messung das Produktivsystem nicht zu stark behindert wird.
Semiramis kann über die Leistungsmonitore detaillierte Leistungsinformationen zu Anwendungen und Berichten aufzeichnen. Die Leistungsinformationen können Statistiken über den Datenbankzugriff einer Anwendung oder eines Berichtes enthalten. Nutzen Sie die Leistungsinformationen in dem Optimierungsprozess.
Die Profiling-Protokolle liefern eine detaillierte Analyse einzelner Anwendungen oder anwendungsbezogener Aktionen. Weitere Informationen finden Sie im Abschnitt „Leistungsmessungen“.
4.1.4 Speicherverbrauch
Java hat eine dynamische Speicherverwaltung mit einem Garbage-Collector, der nicht mehr referenzierte Objekte regelmäßig im Hintergrund freigibt. Der Garbage-Collector kann zu einer bedeutenden CPU-Belastung führen, wenn in kurzer Zeit sehr viele Objekte erzeugt werden. Sie sollten daher unnötige Erzeugungen von neuen Java-Objekten vermeiden. Mit Memory-Profilern, wie z. B. Optimize-It, können Sie analysieren, wie viele Objekte von welcher Klasse erzeugt wurden. Nutzen Sie diese Werkzeuge, um Ihre Anwendungen zu optimieren.
Zu diesem Thema existieren diverse Beschreibungen im Internet und in den Buchhandlungen. Aus diesem Grund wird die Optimierung des Speicherverbrauchs im Folgenden nicht weiter behandelt.
Beachten Sie, dass die meisten Leistungsprobleme in betriebswirtschaftlichen Anwendungen durch ungünstige oder zu viele Datenbankzugriffe verursacht werden. Leistungsprobleme durch einen zu hohen Speicherverbrauch bzw. zu viele temporär erzeugte Objekte sind eher selten.
4.1.5 Leistungsmessungen
Für Leistungsmessungen stehen Ihnen unter anderem die in diesem Abschnitt vorgestellten Werkzeuge zur Verfügung. Ein Ergebnis einer Leistungsmessung kann eine Menge von Datenbankanweisungen sein, die für das Antwortverhalten einer Anwendung oder eines Berichtes verantwortlich sind. Im Abschnitt „Datenbankanweisungen in Anwendungen finden“ ist beschrieben, wie Sie problematische Datenbankanweisungen in Anwendungen lokalisieren können.
Leistungsmonitore
Die Leistungsmonitore in Semiramis zeichnen ausgewählte Operationen über eine längere Zeit auf. Diese Aufzeichnung können Sie, abhängig vom Detaillierungsgrad der Aufzeichnung, auch auf Produktivsystemen aktivieren. Bei den Leistungsmonitoren werden auch die Ausführungszeiten der einzelnen Operationen gemessen.
Mit den Datenbank-Leistungsmonitoren kann jeder Anwendungsentwickler die von Ihm entwickelten Operationen bezüglich des Persistenzdienstzugriffs kontrollieren. In vielen Fällen bewährt sich das folgende Vorgehen:
- Starten Sie die Anwendung „Leistungsmonitore“
- Legen Sie einen neuen Leistungsmonitor an.
- Verwenden Sie die Vorlage-Datei „DatabaseMonitor-FullAnalysis.xml“.
- Schränken Sie den Leistungsmonitor auf den von Ihnen verwendeten Application-Server ein.
- Schränken ggf. Sie den Leistungsmonitor auf Ihren Benutzer ein.
- Speichern Sie den Leistungsmonitor
- Aktivieren Sie den Leistungsmonitor
- Führen Sie die relevanten Funktionen aus.
- Beenden Sie den Leistungsmonitor.
- Werten Sie den Leistungsmonitor aus.
Weitere Informationen finden Sie in den Dokumenten „Leistungsmonitore“.und „Leistungsinformationen nutzen“
Profiling-Protokolle
Die Profiling-Protokolle zählen wie häufig ausgewählte Persistenzdienstoperationen in welchem Kontext (Anwendung) aufgerufen werden.
Weitere Informationen finden Sie in dem Dokument „Profiling-Protokolle abfragen“.
Memory-Profiler
Memory-Profiler in Java-Entwicklungsumgebungen (z. B. der Memory-Profiler von Optimize-It) können auf Produktivsystemen häufig nicht eingesetzt werden, sind aber die einzige Möglichkeit, um Speicherprobleme in Semiramis analysieren zu können.
CPU-Profiler
CPU-Profiler in Java-Entwicklungsumgebungen (z. B. der CPU-Profiler von Optimize-It) können auf Produktivsystemen häufig nicht eingesetzt werden und haben häufig in einem Multi-Threaded/Multi-User/Multi-Session-System wie Semiramis Probleme, die Messungen dem richtigen Benutzer-Kontext zuzuordnen. Außerdem verfälschen einige Java-Profiler insbesondere die Zeitmessung dadurch, dass entweder Hot-Spot nicht vollständig läuft oder zu viele unnötige Messpunkte die Laufzeit verlängern.
Für Messungen in Semiramis eignen sich in vielen Fällen Java-Profiler daher nicht. Die Leistungsmonitore und die Profiling-Protokolle liefern in normalerweise bessere Daten als die Java-Profiler.
Ausgabe von Datenbankanfragen
Während der Entwicklung können die ausgeführten Datenbankanfragen mit dem folgenden Befehl ausgegeben werden.
Hinweis:
Verwenden Sie diese Ausgabe nur auf dem Entwicklungssystem, insbesondere auf dem Produktivsystem kann die Ausgabe die Leistungsfähigkeit des Application-Servers stark einschränken.
dbgcls -class:com.cisag.sys.kernel.sql.CisPreparedStatement
Mithilfe des optionalen Parameters -level können Sie den Schwellwert bzgl. der Ausführungszeit zur Ausgabe des Datenbankstatements einstellen.
| Parameter | Schwellwert |
| kein Level angegeben bzw.
level:100 |
kein Schwellwert |
| -level:2 | 250 ms |
| -level:5 | 1000 ms |
4.2 Indexe
Ein Index ist eine Zugriffstruktur, die den Zugriff auf einzelne Zeilen einer Tabelle beschleunigen kann. Ein Index ist durch eine geordnete Folge von Attributen einer Tabelle definiert. Diese Attribute sind die Indexattribute. Detaillierte Informationen der internen Funktionsweise von Indexen entnehmen Sie der Grundlagenliteratur zu Datenbanken.
Ein Index enthält (vereinfacht) für jede Zeile der Tabelle, auf der der Index definiert ist, einen Eintrag. Ein Eintrag besteht aus einem Wert und einem Verweis auf die zugeordnete Zeile in der Tabelle. Der Index hat eine Zugriffsstruktur, sodass auf dem Wert der Indexeinträge effizient gesucht werden kann. Von dem Indexeintrag kann das Datenbankmanagementsystem (DBMS) effizient auf die Tabellenzeile zugreifen.
Der Wert eines Indexeintrags bestimmt sich aus den Werten der Indexattribute der Tabellenzeile, auf die der Verweis zeigt. Die in Semiramis verwendeten Indexe sind sortiert, d.h. die Indexeinträge sind gemäß dem Wert sortiert. Neben dem optimierten Zugriff kann ein Index vom DBMS bei der Sortierung des Anfrageergebnisses verwendet werden.
Beispiel:
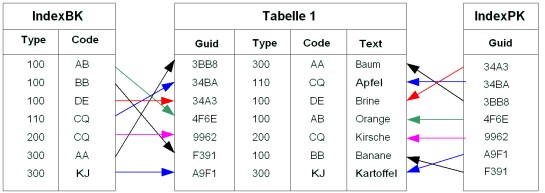
Beispiel für eine Tabelle mit zwei Indexen
Die Tabelle 1 in diesem Beispiel hat zwei Indexe. Der Index BK (Business Key) ist auf den Attributen „Type“ und „Code“ definiert und der Index PK (Primary Key) auf dem Attribut „Guid“. Jede Zeile eines Indexes zeigt auf eine Zeile der Tabelle.
4.2.1 Lesen mit Index
Über einen Index können bestimmte Zeilen einer Tabelle ausgewählt werden. Der Zeitaufwand der Suche eines Eintrags in einem Index liegt in O(log(n)). D.h. die Suche benötigt meist einen logarithmischen Zeitaufwand (Index-Scan). Im Gegensatz dazu liegt der Zeitwand der Suche eines Eintrags in einer Tabelle in O(n), das heißt der Zeitaufwand ist linear (Full-Table-Scan).
Beispiel
| Anzahl
Datensätze |
Zeit für
Full-Table-Scan |
Zeit für
Index-Scan |
| 100 | 0,1 s | 0,01 s |
| 10.000 | 1 s | 0,02 s |
| 1.000.000 | 10 s | 0,03 s |
| 100.000.000 | 100 s | 0,04 s |
Je mehr Zeilen in der Tabelle sind, desto größer ist der Zeitvorteil beim Zugriff über einen Index. Dieses Beispiel verdeutlicht, dass ein Zugriff auf eine große Datenmenge ohne die Verwendung eines Indexes nicht akzeptabel ist (Full-Table-Scan). Die Anzahl der Indexattribute (bzw. deren Größe) hat einen Einfluss auf den Zeitaufwand beim Index-Scan. Der Zugriff auf einen Index mit 5 Attributen ist langsamer als bei einem Index mit einem Attribut. Indexe sollten daher nicht zu viele Indexattribute umfassen.
Ein Index kann nur bei einer Anfrage verwendet werden, wenn die ersten n Indexattribute in der Anfrage mit „=“ eingeschränkt wurden. Die Vergleiche der Indexattribute sollten mit „AND“ verknüpft und in der gleichen Reihenfolge wie im Index aufgeführt werden. Durch komplexe Klammerungen und durch „AND“ und „OR“ Kombinationen wird es für den Optimierer schwieriger zu erkennen, dass er den Index benutzen kann.
SELECT * FROM Tabelle1 WHERE guid=’3BB8’
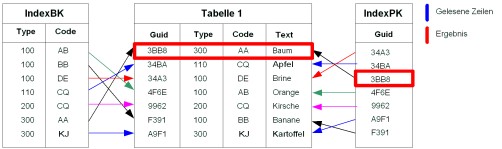
Beispiel für Zugriff mit allen Indexattributen
Diese Anfrage kann den Index „IndexPK“ verwenden, daher liegt der Zeitaufwand der Anfrage in O(log(n)).
Bei der folgenden Anfrage kann der Index „IndexBK“ verwendet werden, da „type“ das erste Indexattribut dieses Indexes ist:
SELECT * FROM Tabelle1 WHERE type=’100’
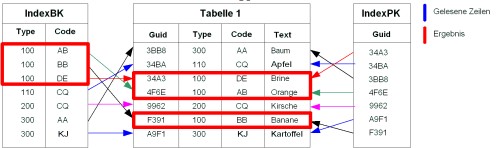
Beispiel für den Zugriff mit den ersten n Indexattributen
Im Gegensatz dazu ist bei der folgenden Anfrage ein Full-Table-Scan notwendig, da der Index „IndexBK“ nicht mit dem Attribut „code“ beginnt:
SELECT * FROM Tabelle1 WHERE code=’AB’
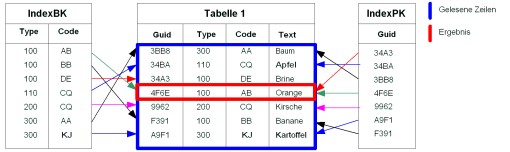
Beispiel für einen Full-Table-Scan
Bei der folgenden Anfrage kann der Index „IndexBK“ verwendet werden, da mit „type“ das erste Indexattribut dieses Indexes zur Selektion verwendet wird und alle Indexattribute in der korrekten Reihenfolge beim ORDER BY angegeben wurden:
SELECT * FROM Tabelle1 WHERE type=’100’ ORDER BY type, code
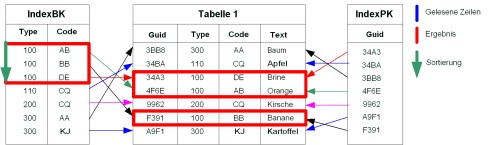
Beispiel für die Sortierung über einen Index
Im Gegensatz dazu kann bei der folgenden Anfrage der Index „IndexBK“ nur zur Selektion verwendet werden, nicht aber zur Sortierung, da die Sortierung nicht die ersten n Indexattribute des Indexes umfasst.
SELECT * FROM Tabelle1 WHERE type=’100’ OR type=’200’ ORDER BY code
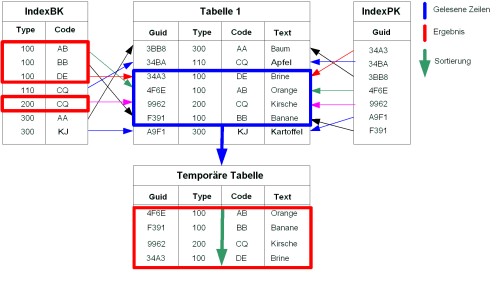
Beispiel für die Sortierung in einer temporären Tabelle
4.2.2 Wahl der Indexattribute
Ein Index kann vom DBMS nur dann sinnvoll zur Selektion verwendet werden, wenn der Index die Menge der möglichen Ergebniszeilen deutlich einschränkt. Wenn ein Index beispielsweise die Menge der möglichen Tabellenzeilen nur um 50 % einschränkt, wird der Index vom DBMS voraussichtlich nicht verwendet, da ein Full-Table-Scan in diesem Fall günstiger ist als ein Index-Scan.
Beispiel:
Ein Index mit dem einzigen Indexattribut „Geschlecht“ ist nicht sinnvoll.
Versuchen Sie immer, Indexe so zu definieren, dass ein Indexeintrag möglichst wenige Tabellenzeilen referenziert. Je größer die Differenz zwischen der Anzahl der Indexeinträge und der Anzahl der Tabellenzeilen ist, desto fragwürdiger ist der Index.
Eine Ausnahme von der obigen Regel ist, wenn die Verwendung der Werte des Indexattributs nicht gleich verteilt ist.
Beispiel:
Wenn 95% aller Aufträge erledigt sind und 5% in einem Status ungleich erledigt, ist ein Index mit dem eigenen Indexattribut „Status“ sinnvoll.
Die Datenbank verwendet meist nur einen Index pro Tabelle in der Anfrage für die Selektion. Es ist also sinnlos, für jedes Attribut einen einzelnen Index (mit geringer Selektivität) anzulegen. Sie müssen Attributkombinationen mit einer hohen Selektivität finden, die in möglichst vielen relevanten Anfragen verwendet werden. Für diese Attributkombinationen können Sie Indexe anlegen. Nutzen Sie dafür die Monitoring-Funktionen des DBMS.
4.2.3 Schreiben mit Index
Beim Einfügen, Ändern und Löschen von Tabellenzeilen müssen alle Indexe, die für die geänderte Tabelle definiert sind, aktualisiert werden. Der Zeitaufwand zum Aktualisieren eines Indexes liegt in O(log(n)). Der Zeitaufwand zum Einfügen, Ändern und Löschen von Tabellenzeilen steigt somit linear mit der Anzahl der Indexe.
Beispiel:
| Anzahl
Datensätze |
Ändern bei
1 Index |
Ändern bei
2 Indexen |
Ändern bei
4 Indexen |
Ändern bei
8 Indexen |
| 100 | 5 ms | 10 ms | 20 ms | 40 ms |
| 10.000 | 10 ms | 20 ms | 40 ms | 80 ms |
| 1.000.000 | 15 ms | 30 ms | 60 ms | 160 ms |
| 100.000.000 | 20 ms | 40 ms | 80 ms | 320 ms |
Bei Änderungen kostet die Aktualisierung der Indexe relativ viel Zeit. Bei Daten, die sich häufig ändern (z. B. Bewegungsdaten), sollten daher nicht zu viele Indexe für eine Tabelle definiert werden. Bei Tabellen, deren Daten sich kaum ändern (z. B. Stammdaten), wirkt sich der erhöhte Zeitaufwand bei Änderungen nicht negativ aus.
4.2.4 Beziehungen
Beziehungen werden in Semiramis fast immer über den Primärschlüssel definiert.
Bei 1:1 Beziehungen wird der Primärschlüssel der Ziel-Business-Object-Instanz in der Quell-Business-Object-Instanz gespeichert. Wenn die Beziehung zu der Ziel-Instanz abgefragt wird, kann beim Datenbankzugriff der Primär-Index des Zielobjekts verwendet werden.
Bei 1:n Beziehungen wird der Primärschlüssel der Quell-Business-Object-Instanz in der Ziel-Business-Object-Instanz gespeichert. Sie sollten im Datenmodell unbedingt einen Index im Ziel-Business-Object anlegen, der die Kopien der Primärschlüsselattribute des Quell-Business-Objects vollständig umfasst bzw. zumindest damit beginnt.
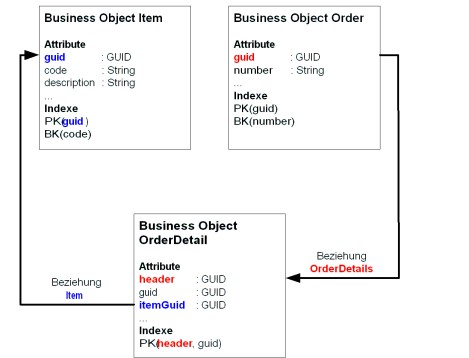
Beispiel für die Anlage von Indexen bei 1:1 und 1:n Beziehungen
Der Index „PK“ im Business Object „OrderDetail“ beginnt mit dem Attribut „header“, das den Wert des Attributs „guid“ der zugehörigen Order enthält. Damit kann beim Auflösen der Beziehung „OrderDetails“ der Index „PK“ vom Business ‚Object „OrderDetail“ verwendet werden, um die zugehörigen Instanzen zu ermitteln.
Insbesondere bei Dependents kann es sinnvoll sein, den Primärschlüssel des Entitys (d.h. dessen GUID) als ersten Teil des Primärschlüssels des Dependents zu verwenden.
Der Primärschlüssel hat auf einigen Datenbanken eine besondere Bedeutung. Auf einigen Datenbanken werden die Tabellenzeilen gemäß der Sortierung im Index abgelegt (Cluster). Dies hat den Vorteil, dass bei einem Index-Scan der Zugriff auf die Tabellenzeilen sequentiell erfolgt und damit das DBMS deutlich weniger Daten laden muss, um das Anfrageergebnis zu berechnen.
4.2.5 Bewegungsdaten
Bewegungsdaten teilen sich häufig in die aktiven Daten und die historischen Daten. Beispielsweise gehören alle Aufträge, die in einem Status ungleich erledigt sind, zu den aktiven Daten und alle erledigten Aufträge sind eher historische Daten. Zwischen den aktiven und den historischen Daten gibt es die folgenden Unterschiede:
- Das Datenvolumen der aktiven Daten ist deutlich kleiner als das der historischen Daten.
- Auf den aktiven Daten erfolgen im laufenden Betrieb häufig lesende und schreibende Zugriffe.
- Auf den historischen Daten gibt es nur noch lesende, aber kaum noch schreibende Zugriffe.
Die Trennung nach aktiven bzw. historischen Bewegungsdaten geschieht häufig mit Hilfe eines Statusattributs im Entity-Kopf. Falls Indexe zur Performancesteigerung angelegt werden, sollte dieses Statusattribut möglichst an erster Stelle des Indexes kommen.
4.2.6 Stammdaten
Auf Stammdaten gibt es sehr viele lesende, aber relativ wenig schreibende Zugriffe. Das Datenvolumen von Stammdaten hängt sehr von dem konkreten Anwendungsfall ab.
Beispiel:
Ein Kunde hat 100 Artikel, ein anderer Kunde kann auch 100.000 Artikel haben.
4.3 ORDER BY
Wenn kein Index für die Sortierung des Anfrageergebnisses verwendet werden kann, liegt der Zeitbedarf für die Sortierung des Ergebnisses in O(n*log(n)).
In der Praxis sind Sortierungen kleiner Datenmengen meist überproportional schneller als die Sortierung großer Datenmengen. Kleine Datenmengen (z. B. <1 MB) kann das DBMS im Hauptspeicher sortieren. Für große Datenmengen ist ggf. das Zwischenspeichern der Sortierergebnisse auf der Festplatte notwendig.
Das DBMS muss das vollständige Anfrageergebnis berechnen, bevor der erste Datensatz einer sortierten Ergebnismenge zurückgegeben werden kann. Dies bedeutet insbesondere, dass das Anfrageergebnis in der Datenbank zwischengespeichert werden muss. Auch aus diesem Grund sind Sortierungen auf großen Ergebnismengen sehr zeitaufwendig.
Wenn für die Sortierung ein Index verwendet werden kann, ist der Zeitbedarf für das Sortieren in O(n). Das heißt der Zeitbedarf steigt linear mit der Anzahl der Datensätze im Ergebnis.
Beispiel:
| Anzahl
Datensätze |
Zeit für
Sortierung ohne Index |
Zeit für
Sortierung mit Index |
| 100 | 0,2 s | 0,2 s |
| 10.000 | 10 s | 2 s |
| 1.000.000 | 150 s | 20 s |
| 100.000.000 | 2000 s | 200 s |
Wenn eine Sortierung notwendig ist, sollten Sie also entweder die Ergebnismenge so klein halten, dass die Sortierung nicht übermäßig aufwendig ist oder aber einen Index anlegen, der bei der Sortierung genutzt werden kann.
4.4 GROUP BY
Der Zeitbedarf bei der Abfrage der vollständigen Ergebnismenge von einer Anfrage mit GROUP BY liegt wie bei der Sortierung in O(n*log(n)). Wie bei den Sortierungen kann auch für GROUP BY ein Index verwendet werden, wenn das GROUP BY aus der Folge der ersten n Indexattribute des Indexes besteht.
4.5 DISTINCT
Der Zeitbedarf bei der Abfrage der vollständigen Ergebnismenge von einer Anfrage mit DISTINCT liegt wie bei der Sortierung in O(n*log(n)). Bei DISTINCT ist es jedoch nicht immer unbedingt notwendig, das vollständige Abfrageergebnis zu berechnen, bevor die erste Ergebniszeile zurückgegeben wird.
5 Optimierungen
5.1 Datenbankzugriff
Fast alle Anwendungen besitzen einige oder alle der folgenden Teilfunktionen:
- Daten von der Datenbank lesen
- Daten verarbeiten
- Daten auf die Datenbank schreiben
- Daten anzeigen
Meist werden in Anwendungen mehr Daten gelesen als geschrieben. Das Lesen und Schreiben von Daten von der Datenbank benötigt häufig die meiste Zeit in einer Anwendung.
Sofern keine unnötigen Schreiboperationen durchgeführt werden und die Transaktionsgröße weder zu klein noch zu groß ist, besteht bei Schreiboperationen nur ein geringes Optimierungspotential.
5.1.1 Bedeutung des Shared Caches
Die lesenden Zugriffe benötigen häufig die meiste Zeit. Der Zugriff auf die Datenbank ist im Vergleich zu dem Zugriff auf Daten innerhalb des Application-Servers sehr langsam. Semiramis besitzt aus diesem Grund den Shared Cache, der häufig gelesene Business Object Instanzen wieder verwendet. Der Shared Cache besitzt eine begrenzte Größe und kann eine bestimmte Menge von Business Object Instanzen zwischenspeichern.
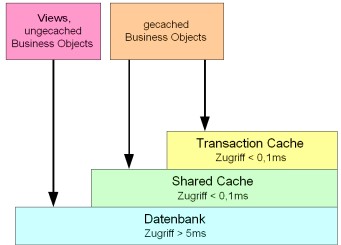
Zeit für Zugriff auf ein Business Object
Der Zugriff auf die Datenbank kann einen Faktor größer 50 langsamer sein als der Zugriff auf den Shared Cache. Die Cache-Hit-Rate gibt an, bei wie viel Prozent der Zugriffe die angefragte Business-Object-Instanz im Shared Cache gefunden wurde.
Beispiel: Angenommen der Zugriff auf die Datenbank ist um Faktor 50 langsamer als der Zugriff auf den Shared Cache. Für ein Business Object sei die Cache-Hit-Rate bei 95 %. Das bedeutet, dass 95 % aller Lesezugriffe auf eine einzelne Business-Object-Instanz durch den Shared Cache beantwortet werden und 5% aller Lesezugriffe einen Datenbankzugriff benötigen. Daraus folgt, dass die Datenbankzugriffe 72 % der durchschnittlichen Zugriffszeit benötigen.
Durch den großen Unterschied in der Zugriffszeit auf den „schnellen“ Shared Cache und auf die „langsame“ Datenbank sind selbst bei einer relativ hoch erscheinenden Cache-Hit-Rate von über 90 % der Datenbankzugriffe die tatsächlich ausgeführten Datenbankzugriffe der entscheidende Faktor beim durchschnittlichen Zeitverbrauch.
Der Shared Cache speichert nur existierende Objekte und speichert im Allgemeinen nicht, welche Objekte gelöscht bzw. nicht existent sind. Das bedeutet, wenn getObject mit einem Schlüssel aufgerufen wird, zu dem keine Business Object Instanz existiert, kann der Persistenzdienst diese Anfrage nicht aus dem Shared Cache beantworten, sondern muss eine Datenbankanfrage stellen.
Insbesondere bei dem Entwurf bzw. dem Erweitern von Business Objects sollte darauf geachtet werden, dass bei 1:1 Beziehungen aus dem Zustand des Quellobjekts die Existenz des Zielobjekts abgeleitet werden kann.
5.1.2 Verwendung der getObjectArray
Der Lesezugriff für eine Business Object Instanz auf der Datenbank aus Semiramis durchläuft die folgenden Schichten:

Unterschiedliche Schichten beim Datenbankzugriff
Zunächst wird für den Lesezugriff eine SQL-Anfrage erzeugt, diese wird an die Datenbank übertragen, dort ausgeführt und aus dem Ergebnis der Anfrage eine Business Object Instanz erzeugt:
- Der Zeitaufwand, um die Anfrage aufzubauen, um aus dem Anfrageergebnis eine Business-Object-Instanz zu erzeugen, hängt davon ab, wie viele Attribute das Business Object umfasst. Je höher die CPU-Leistung des Rechners, auf dem der Application-Server läuft, ist, desto geringer ist der Zeitaufwand für das Business Object Mapping.
- Der Zeitaufwand für die Kommunikation hängt ebenfalls von der Komplexität des Business Objects ab. Bei der Kommunikation ist die Art der Netzwerkverbindung zwischen Application-Server und Datenbankserver der entscheidende Faktor für den Zeitaufwand. Wenn Application-Server und Datenbankserver auf dem gleichen Rechner laufen, ist der Kommunikationsaufwand minimal.
- Der Zeitbedarf der Datenbank hängt von vielen Einflussfaktoren ab. Wenn die Anfrage im datenbankinternen Cache beantwortet wird, kann die Antwortzeit im Bereich von wenigen Millisekunden liegen. Wenn auf die Festplatten zugegriffen wird, benötigt die Anfrage leicht mehr als 10 ms.
Wenn Sie n Business-Object-Instanzen, die nicht im Shared Cache sind, mit der Methode getObject lesen, wird n-mal die Zeit für das Business-Object-Mapping, die Kommunikation und die Datenbankanfrage benötigt.
Mit der Methode getObjectArray können Sie mehrere Business-Object-Instanzen mit einer Datenbankanfrage lesen. Dadurch verkleinert sich der Kommunikationsaufwand, da die Anfrage nur einmal an den Datenbankserver übermittelt und das Anfrageergebnis als Block von dem Datenbankserver an den Application-Server übertragen wird.
Wenn der Datenbankserver und der Application-Server nicht auf dem gleichen Rechner sind, kann die Verwendung von getObjectArray den Lesezugriff ihres Programms auf die Daten um bis zu Faktor 3 beschleunigen.
5.1.3 Verwendung von INSERT
Mit dem Flag CisObjectManager.INSERT prüft der Persistenzdienst nicht, ob ein Objekt bereits auf der Datenbank existiert. Beim Lesen eines Objekts mit INSERT greift der Persistenzdienst nicht auf die Datenbank zu. Wenn das Objekt dennoch auf der Datenbank existiert, führt die Verwendung von INSERT zu einem Laufzeitfehler. Wenn mit dem Flag READ_WRITE neue Objekte angelegt werden, ist für jedes neue Objekt ein Lesezugriff auf die Datenbank notwendig, um zu prüfen, ob das Objekt bereits existiert. Wenn INSERT verwendet werden kann, wird der Lesezugriff eingespart. Dies führt zu einer deutlichen Zeitersparnis.
Das Flag CisObjectManager.INSERT sollte immer dann verwendet werden, wenn aufgrund des Programmablaufs das zu erzeugende Objekt noch nicht auf der Datenbank existiert. Bei Neuanlagen von Entitys reicht es, falls überhaupt notwendig, das Haupt-Business-Object des Entitys mit READ_WRITE zu erzeugen. Alle Dependents des Entitys können mit INSERT angelegt werden, wenn das Haupt-Business Object nicht persistent ist.
5.1.4 Konstanten in OQL
Verwenden Sie niemals Textkonstanten für Anfrageparameter in OQL, sondern den Platzhalter „?“. Jede OQL-Anweisung wird in OQL übersetzt. Zu diesem Zweck wird die OQL-Anweisung geparst und mit Hilfe der Objektbeschreibungen der Business Objects eine SQL-Anweisung generiert. Da diese Übersetzung unter Umständen relativ aufwendig ist, werden die bereits aus der Übersetzung hervorgegangenen SQL-Anweisungen in einem Cache gehalten. Jeder OQL-Anweisung, zu dem noch keine SQL-Anweisung im Cache existiert, muss neu übersetzt werden. Im Allgemeinen sind die Werte der Anfrageparameter nicht konstant. Wenn anstatt der Platzhalter „?“ direkt Textkonstanten für die Abfrageparameter in der OQL-Anweisung verwendet werden, entsteht somit immer einer neue OQL-Anweisung. Diese muss jedes Mal erneut in SQL übersetzt werden. Weiterhin kann jede neue Datenbankanweisung weitere Datenbankzugriffe für das Leistungsmonitoring zur Folge haben. Aus diesen Gründen ist die Verwendung von Textkonstanten für .Anfrageparameter in OQL nicht zulässig.
Bei der Kommunikation mit der Datenbank werden SQL-Anweisungen mehrfach verwendet (Prepared-Statements). Wenn Anfrageparameter als Textkonstanten übergeben werden, steigt auch die Belastung für die Datenbank, da die Prepared-Statements nicht wieder verwendet werden können.
Beispiel:
Schlechtes Beispiel für Anfrageparameter in OQL:
CisObjectIterator i=om.getObjectIterator(
“SELECT FROM com.cisag.app.general.obj.Item i WHERE “+
“i:guid=TOGUID(‘”+Guid.toHexString(itemGuid)+”’)”);
Gutes Beispiel für Anfrageparameter in OQL:
CisObjectIterator i=om.getObjectIterator(
“SELECT FROM com.cisag.app.general.obj.Item i WHERE “+
“i:guid=?”);
i.setGuid(1,itemGuid);
5.1.5 Verwendung von getObjectIterator
Die Methode getObjectIterator selektiert eine Folge von Business Object Instanzen eines Business Objects.
Sofern das Business Object die Caching-Einstellung LRU hat oder mit den Flag READ_UPDATE bzw. READ_WRITE gelesen wird, selektiert die aus dem OQL erzeugte SQL-Anfrage die Primärschlüsselattribute des Business Objects.
Beispiel:
Aus der OQL-Anfrage
SELECT FROM com.cisag.app.sales.obj.SalesOrder o
WHERE o:number>?
wird bei einem mit LRU im Cache gehaltenen Business Object die SQL-Anfrage:
SELECT O.GUID FROM SALESORDER O WHERE O.NUMBER>?
Mit den Primärschlüsselattributen werden mit der Methode getObjectArray die Business-Object-Instanzen geladen.
Wenn das Business Object nicht aus dem Cache oder mit dem Flag BYPASS_CACHE gelesen wird, selektiert die aus dem OQL erzeugte SQL-Anfrage alle Attribute des Business Objects.
Beispiel:
Aus der OQL-Anfrage
SELECT FROM com.cisag.app.sales.obj.SalesOrder o
WHERE o:number>?
wird bei einem nicht im Cache gehaltenen Business Object die SQL-Anfrage:
SELECT * FROM SALESORDER O WHERE O.NUMBER>?
Die Selektion der Primärschlüsselattribute ist ab einer Cache-Hit-Rate von ca. 70 % schneller als die Selektion aller Attribute. Meist ist es für die Anwendung jedoch nicht entscheidbar, welche Art des Zugriffs günstiger ist. In Massendatenverarbeitungen kann es jedoch günstig sein, auch auf im Cache gehaltene Objekte mit BYPASS_CACHE zuzugreifen.
Bei einer Cache-Hit-Rate von 0 % ist die Selektion über den Primärschlüssel deutlich langsamer als die Selektion des vollständigen Objekts. Bei einer Cache-Hit-Rate von 100 % ist die Selektion über den Primärschlüssel deutlich schneller als die Selektion des vollständigen Objekts.
5.1.6 Verwendung von getResultSet
Mit der Methode getResultSet wird wie bei einer SQL-Anfrage eine Menge von Werten aus beliebigen Business Objects selektiert.
Wenn nur relativ wenige Attribute aus einem Business Object benötigt werden und die Cache-Hit-Rate dieses Business Object nicht übermäßig hoch (< 95 %) ist, kann es günstiger sein, die Attribute mit getResultSet zu lesen, als die vollständigen Objekte mit getObjectIterator aufzubauen.
Beispiel:
OQL-Anfrage für getObjectIterator
SELECT FROM com.cisag.app.sales.obj.SalesOrder o
WHERE o:number>?
braucht länger als die OQL-Anfrage für getResultSet
SELECT o:guid, o:pickingStatus
FROM com.cisag.app.sales.obj.SalesOrder o
WHERE o:number>?
5.1.7 Verwendung von „getUpdateStatement()“
Die Methode „getUpdateStatement()“ erlaubt es UPDATE- und DELETE-Anweisungen direkt auf der Datenbank auszuführen. Der Zeitbedarf dieser UPDATE-Anweisungen ist meist deutlich geringer als der Zeitbedarf von einer äquivalenten Logik, die mit Business-Object-Instanzen arbeitet. Nach der Verwendung eines Update Statements werden alle Instanzen des betroffenen Business Objects aus allen Caches aller Application-Server in dem System entfernt. So wird die Konsistenz der Shared Caches mit dem Datenbankinhalt gesichert. Die häufige Verwendung von „getUpdateStatement()“ verkleinert damit die Effektivität des Shared Caches beträchtlich. Aus diesem Grund sollten UPDATE-Anweisungen primär in Reorganisationen und Massendatenverarbeitungen verwendet werden.
5.1.8 Blockorientierung in Logikklassen
Jeder Verarbeitungsschritt muss Daten in angemessen großen Einheiten verarbeiten. Diese Einheiten dürfen weder zu groß noch zu klein sein.
Wenn die Verarbeitung in zu großen Einheiten erfolgt, ist der Ressourcenbedarf (Hauptspeicher und zum Teil CPU) im Application-Server zu hoch.
Beispiel:
Wenn eine Logik alle Auftragspositionen eines Auftrages in den Hauptspeicher lädt, ist dies sehr schlecht, da die Anzahl der Positionen eines Auftrags nicht begrenzt ist. Einige Kunden verwenden Aufträge mit weniger als 10 Positionen, andere können auch durchaus mehr als 10.000 Positionen haben. Wenn eine Anwendung 10.000 Positionen in den Hauptspeicher lädt, verbraucht diese Anwendungsinstanz sehr viel Hauptspeicher und kann damit den Hauptspeicher zum Überlaufen bringen, was den Application-Server wegen Speichermangel beendet.
Wenn die Verarbeitung in zu kleinen Einheiten erfolgt, ist der Ressourcenbedarf (Datenbanklast und zum Teil CPU) im Application-Server ebenfalls zu hoch. Bei zu kleinen Einheiten werden die Daten in zu kleinen Transaktionen geschrieben, was zu einer hohen Datenbanklast führt. Außerdem sind in diesem Fall auch die Lesezugriffe meist nicht blockorientiert.
Die folgenden Regeln sollten beim Entwurf von Logikklassen beachtet werden:
- Eine Transaktion sollte maximal 1000 Business Objects umfassen.
- Alle Lesezugriffe sollten mit „getObjectArray()“ blockweise erfolgen.
- Die Logik darf nur eine beschränkte Menge des Hauptspeichers benötigen.
- Eine OQL-Anweisung sollte maximal 4000 Zeichen lang sein.
Beispiel:
Schlechtes Beispiel für Blockorientierung:
for (…) {
…
i=om.getObjectIterator(
“SELECT FROM com.cisag.app.sales.obj.SalesOrder so “+
“WHERE so:status=? AND ”
“so:totalValue.grossValue.amount>=? AND “+
“so:totalValue.grossValue.amount<?”;
i.setShort(1,x);
i.setDecimal(2,y);
i.setDecimal(3,z);
…
}
In dem obigen Programm wird für jeden Durchlauf der äußeren Schleife ein Zugriff auf die Tabelle SalesOrder durchgeführt. Da auf dem Attribut „totalValue.grossValue.amount“ kein Index ist, ist dieser Zugriff relativ aufwendig.
Gutes Beispiel für Blockorientierung:
StringBuffer oql = new StringBuffer(“SELECT “+
”FROM com.cisag.app.sales.obj.SalesOrder so
“WHERE so:status=? AND (“);
ArrayList values = new ArrayList();
String separator = “”;
for (…) {
…
oql.append(separator);
oql.append(“(so:totalValue.grossValue.amount>=? AND “+
“so:totalValue.grossValue.amount<?)”
values.add(x);
values.add(y);
values.add(z);
separator=” OR “;
if (blockSize>10 || …) {
oql.append(“)”);
i=om.getObjectIterator(oql.toString());
int idx=1;
for (Iterator v=values.iterator(); v.hasNext();) {
i.setShort(idx++,((Short)v.next()).shortValue());
i.setDecimal(idx++,(CisDecimal)v.next());
i.setDecimal(idx++,(CisDecimal)v.next());
}
…
separator = “”;
oql = new StringBuffer(“SELECT “+
”FROM com.cisag.app.sales.obj.SalesOrder so
“WHERE so:status=? AND (“);
…
}
In dem obigen Programm wird nur für jeden 10. Durchlauf der äußeren Schleife ein Zugriff auf die Tabelle SalesOrder durchgeführt. Dadurch wird die Datenbanklast näherungsweise um den Faktor 10 kleiner.
5.1.9 Datenbankanweisungen in Anwendungen finden
Wenn Sie durch die Leistungsmonitore oder aber du die Profiling-Protokolle eine oder mehrere Datenbankanweisungen ermittelt haben, die für die ungenügende Antwortzeit einer Anwendung verantwortlich sind, so müssen Sie die Methoden der Klassen finden, die die Datenbankanweisungen ausführen:
- Starten Sie den Application-Server im Debugger.
- Melden Sie sich auf dem Application-Server an.
- Bereiten Sie die Umgebung soweit vor, dass Sie die problematische Funktion der Anwendung ausführen können.
- Setzen Sie einen Breakpoint im Debugger in der Anwendung auf die erste Zeile der problematischen Funktion.
- Aktivieren Sie die Ausgabe aller ausgeführten Datenbankanweisungen:
dbgcls -class:com.cisag.sys.kernel.sql.CisPreparedStatement
- Führen Sie die problematische Funktion aus.
- Debuggen Sie solange bis die gesuchte Datenbankanweisung als Debug-Ausgabe ausgegeben wird.
Optimieren Sie bei langen Ausführungszeiten die Datenbankanweisung oder reduzieren Sie bei sehr häufigen Ausführungen mit kurzen Ausführungszeiten die Ausführungshäufigkeit.
5.2 Suchen und Cockpits
In Suchen und Cockpits werden meist komplexe Datenbankanfragen erzeugt. Diese Anfragen werden abhängig von den verwendeten Suchparametern dynamisch zusammengebaut. Jedes System kann abhängig von der von ihm genutzten Funktionalität andere Anfragen erzeugen. Daher ist es insbesondere bei Cockpits nicht immer einfach, im Standard Indexe auszuliefern, die für alle möglichen Kundenanforderungen nützlich sind.
5.2.1 Wahl der Vorschlagswerte für Suchfelder
In Suchen und Cockpits sind die Listen, in denen das Suchergebnis ausgegeben wird, immer sortiert. Das Sortieren von großen Ergebnismengen ist sehr zeitaufwendig. Es ist nur selten möglich, für die Sortierung in Suchen einen sinnvollen Index anzulegen. Viele Benutzer öffnen eine Suche und starten diese Suche, ohne das Suchergebnis mit Suchmerkmalen einzuschränken. Wenn die Vorschlagswerte der Suche nicht eingeschränkt sind, wird der gesamte Datenbestand ausgewählt und muss wahrscheinlich noch sortiert werden. Dies erzeugt beispielsweise bei Bewegungsdaten eine extrem hohe Datenbanklast. Wenn die Vorschlagswerte der Suchfelder so gewählt werden, dass die Ergebnismenge eine beschränkte Größe hat, wird das System durch den Start einer Suche mit Vorschlagswerten nicht so stark belastet.
Insbesondere Bewegungsdaten teilen sich häufig in die aktiven und die historischen Daten. Beispielsweise gehören alle Aufträge, die in einem Status ungleich erledigt sind, zu den aktiven Daten, und alle erledigten Aufträge sind eher historische Daten. Das Datenvolumen der aktiven Daten ist deutlich kleiner als das der historischen Daten. Die Suchfelder in Suchen und Cockpits sollten immer so vorbelegt werden, dass diese nur auf den aktiven Daten suchen.
5.2.2 Kundenspezifische Anpassung
Suchen und insbesondere Cockpits können bei Leistungsproblemen kundenspezifisch angepasst werden. Dabei sollten alle Such- und Sortierfelder ausgeblendet werden, die der Kunde nicht benötigt. Je weniger Such- und Sortiermöglichkeiten bestehen, desto besser können kundenspezifische Indexe angelegt werden.
Wenn sehr viele Such- und Sortiermöglichkeiten existieren und diese nicht beschränkt werden, kann es Kombinationen geben, die ein sehr ungünstiges Zeitverhalten haben.
5.2.3 Nutzung von Fragmenten
Teilen Sie die verwendete OQL-Suche in so viele Fragmente wie möglich auf. Durch die Fragmente kann die resultierende SQL-Anfrage abhängig von den Anforderungen dynamisch erweitert werden. Je feiner die Fragmente definiert werden, desto besser kann die Anfrage anpasst werden und desto geringer ist die für die Datenbank erzeugte Last.
5.3 Interaktive Anwendungen
In interaktiven Anwendungen erwartet der Benutzer kurze Antwortzeiten auf seine Interaktion. Welche Antwortzeit der Benutzer toleriert, hängt von der Funktion ab, die der Benutzer nutzt. Beim Laden und Speichern von umfangreichen Objekten akzeptiert der Benutzer beispielsweise Antwortzeiten zwischen 0,5 und 5 Sekunden. Bei der Bearbeitung eines Auftrags muss das Hinzufügen einer neuen Position unter 0,5 Sekunden erfolgen, um vom Benutzer nicht als störend empfunden zu werden.
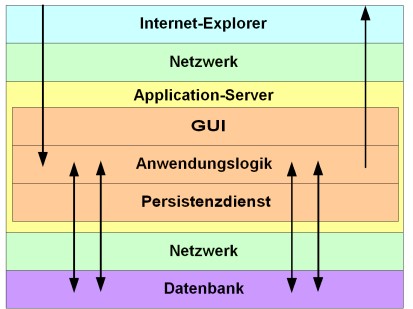
Beispiel für den Ablauf eines Round-Trips
Die für den Benutzer spürbare Round-Trip-Zeit setzt sich aus den folgenden Teilen zusammen:
- Zeit für den Bildschirmaufbau im Internet Explorer
- Zeit für Datenübertragung
- Zeit für Berechnung der GUI
- Zeit zum Durchführen der Anwendungslogik
- Zeit für den Datenbankzugriff
Die GUI (inklusive Datenübertragung und Bildschirmaufbau im Internet-Explorer) benötigt gerade bei kurzen Round-Trips (<1 s) einen relativ hohen prozentualen Anteil der Gesamtzeit. Da dieser Anteil sehr stark von dem konkreten Anwendungsfall abhängt, sind hier Messungen unerlässlich.
Beispiel:
Wenn ein Round-Trip maximal 500 ms dauern darf und die GUI 200 ms der Zeit verbraucht, bleiben für die Anwendungslogik nur 300 ms übrig. Wenn ein Datenbankzugriff im Mittel 10 ms benötigt, dann dürfen in diesem Round-Trip maximal 30 Datenbankzugriffe erfolgen.
Die Anzahl der Datenbankzugriffe ist meist ein entscheidender Faktor in der von der Anwendungslogik verbrauchten Zeit. In einem Round-Trip sollten keinesfalls mehr als 50 Datenbankzugriffe erfolgen. Die Anzahl der Datenbankzugriffe pro Round-Trip wird mit dem Standard-Datenbank-Leistungsmonitor gemessen. Sie können diese mit dem Bericht „Zeitaufwendigste Aktionen sortiert nach Summe“ ausgeben. Wenn bei einer häufig benötigten Operation mehr als 50 Datenbankzugriffe erfolgen, dann muss diese Operation optimiert werden. Natürlich ist nicht nur die Anzahl, sondern auch die Laufzeit der Datenbankzugriffe relevant.
Mit den Leistungsmonitoren oder mit der Ausgabe von Datenbankanfragen mit langer Laufzeit können Sie Datenbankanfragen mit einer langen Laufzeit identifizieren. In einer Dialog-Anwendung müssen komplexe Datenbankanfragen unbedingt vermieden werden. Prüfen Sie daher unbedingt den Zugriffsplan jeder Datenbankanfrage, deren Ausführung länger 100 ms dauert. Full-Table-Scans in Dialog-Anwendung führen bei steigender Datenmenge im Produktivsystem zu einem inakzeptablen Antwortverhalten der Dialog-Anwendung.
Bei interaktiven Funktionen müssen Sie unabhängig von der Datenbasis eine Obergrenze für die maximal benötigte Zeit kennen. Wenn Sie keine Obergrenze angeben können, da beispielsweise der Zeitverbrauch von der verarbeiteten Datenmenge abhängt, führen Sie diese Funktion in einer Hintergrundverarbeitung aus.