
1 Themenübersicht
Bei der Automatisierung von Abläufen spielen maschinenlesbare Daten eine wichtige Rolle. Um Daten maschinenlesbar zu machen, wurden verschiedene Techniken entwickelt. Zu diesen Techniken zählen beispielsweise die Strichcodes (engl. Barcode) und die OCR-Schriften. In einigen Anwendungsbereichen werden auch so genannte „2D-“ oder „Matrixcodes“ eingesetzt.
Das Ausgabe-Management von Semiramis unterstützt die Verwendung (Ausgabe) von Strichcodes und OCR-Schriften in Beleg- und Berichtsdokumenten. Im Lieferumfang von Semiramis sind spezielle Schriftarten und Zusatzfunktionen für eine Vielzahl von Strichcodetypen und OCR/MICR-Schriften bereits enthalten.
Das Dokument gliedert sich in folgende Abschnitte:
| Thema | Inhalt |
| Einführung | Was sind Strichcodes (Barcodes)? |
| Installation | Hinweise zur Installation der Schriftarten und der Zusatzfunktionen für Crystal Reports |
| Strichcodes in Crystal Reports verwenden | Hinweise für die Verwendung der Schriftarten und Zusatzfunktionen in Crystal Reports |
| Übersicht | Übersicht über die im Lieferumfang von Semiramis enthaltenen Schriftarten und der damit unterstützten Strichcodetypen und Standards |
| Spezifikationen | Detaillierte Informationen zu den einzelnen Strichcodetypen, Schriftarten und Funktionen |
| Druckhinweise | Was muss beim Drucken beachtet werden, damit die Strichcodes korrekt gelesen werden können? |
| Weitere Informationen | Wo kann man weitere Informationen zu Strichcodes und Standards bekommen? |
| Bekannte Probleme | Welche Probleme existieren und wie kann man sie lösen oder umgehen? |
2 Zielgruppe
Dieses Dokument richtet sich vorrangig an „Report-Designer“, also diejenigen, die mit Crystal Reports Berichte oder Belege für Semiramis erstellen. Entsprechende Kenntnisse im Umgang mit Crystal Reports (Version 9 oder 10) werden daher vorausgesetzt.
Für Administratoren ist das Kapitel „Installation“ von Bedeutung, hier lässt sich nachlesen, welche Software wo installiert werden muss.
3 Einführung
Im Laufe der Zeit wurden verschiedene Techniken zum maschinellen Lesen von Daten entwickelt. Dieses Dokument beschäftigt sich vorrangig mit den Techniken, die üblicherweise im Handel oder in der Industrie zum Einsatz kommen. Hauptsächlich werden hier verschiedene Varianten von so genannten Strichcodes eingesetzt. Die OCR- bzw. MICR-Schriften werden insbesondere im Bereich des Rechungswesens verwendet.
Da sich der Hauptteil dieses Dokuments den Strichcodes (Barcodes) widmet, erfolgt hier zunächst eine kurze Erläuterung, was Strichcodes sind und wozu man sie einsetzt. Dabei werden auch beispielhaft ein paar Strichcode-Varianten vorgestellt.
3.1 Was sind Strichcodes?
Ein Strichcode ist eine Anordnung von unterschiedlich breiten oder unterschiedlich hohen Strichen (Balken, engl.: „bar“), die abwechselnd schwarz oder weiß gedruckt sind.
Strichcodes dienen dazu, Ziffern und Zeichen so darzustellen (codieren), dass sie mithilfe von speziellen Lesegeräten (sog. Barcode-Scannern) schnell und sicher in ein EDV-System eingelesen werden können. Die Nutzung von Strichcodes bietet sich immer dann an, wenn ansonsten die Daten abgelesen und anschließend von Hand eingegeben werden müssten. Barcode-Scanner arbeiten dabei nicht nur schneller, sondern auch deutlich fehlerfreier – und damit natürlich kostengünstiger.
Es wurden im Laufe der Zeit verschiedene Arten und Varianten von Strichcodes entwickelt. Die Unterschiede zwischen den verschiedenen Strichcodes liegen dabei in:
- ihrer Einfachheit (bzw. Komplexität) bei der Generierung bzw. bei den Lesegeräten,
- dem Umfang des unterstützten Zeichensatzes,
- der erzielbaren Darstellungsdichte (Platzbedarf),
- der Robustheit (Fehlervermeidung, Fehlererkennung, Fehlerkorrektur).
Weiterhin gibt es länderspezifische und branchenspezifische „Standards“.
Die nachfolgende Tabelle zeigt verschiedene Varianten von Strichcodes. Wie man sehen kann, wird die Information nicht in allen Fällen über die Breite von Strichen oder Lücken kodiert, sondern manchmal auch nur über die Länge. Im Fall von „DataMatrix“ kann man eigentlich schon nicht mehr von Strichcodes sprechen (es handelt sich um einen so genannten 2-D bzw. Matrixcode):
| Typ/Symbologie | Strichcode | Daten |
| Code 128 |  |
1234ABCabc |
| EAN-13 |  |
4012345678901 |
| POSTNET | 12345-6789 | |
| DataMatrix[1] |  |
This is a test of the DataMatrix barcode in Semiramis |
3.2 Aufbau von Strichcodes
Der grundsätzliche Aufbau eines Strichcodes wird hier (anhand von Code 128) kurz erläutert. Bei den anderen Strichcodevarianten gelten häufig dieselben Prinzipien, auch wenn sie teilweise anders aussehen.
Ein Strichcode besteht aus parallelen, sich abwechselnden dunklen Strichen und hellen Lücken. Die Informationen sind entweder nur in den Linien, meistens aber auch in den Lücken enthalten. Lücken und Striche werden als (Strichcode-)Elemente bezeichnet.

Typischer Aufbau eines Strichcodes
Die einzelnen Zeichen eines Strichcodes werden durch eine eindeutige Folge von verschieden breiten Elementen definiert. Die meisten Codes verwenden entweder zwei oder vier verschiedene Elementbreiten.
Das schmalste Element wird auch als „Modul“ bezeichnet. Die Breite des schmalsten Elements wird auch als „Modulbreite“ oder „X“ bezeichnet. Die Breite der anderen Elemente wird in der Regel als ein Mehrfaches der Modulbreite angegeben.
Das erste Zeichen eines Strichcodes ist immer ein eindeutiges Startzeichen, das letzte Zeichen ist ein Stoppzeichen. Anhand dieser Zeichen kann der Strichcodetyp und die Lage (Leserichtung) des Strichcodes erkannt werden. Diese beiden Zeichen sind zusätzlich zu den eigentlichen Nutzdaten erforderlich.
Viele Strichcodes bieten zudem die Möglichkeit, eine Prüfziffer (in der oben stehenden Abbildung als „Check Char“ bezeichnet) hinzuzufügen. Der Scanner kann veranlasst werden, beim Lesen diese Prüfziffer ebenfalls zu berechnen und mit dem gelesenen Wert zu vergleichen. Prüfziffern bieten den besten Weg, die Lesesicherheit zu erhöhen. Ein Strichcode kann auch „selbstüberprüfend“ sein. So kann z. B. anhand der Anzahl der gelesenen breiten und schmalen Elemente pro Zeichen erkannt werden, ob das Zeichen richtig erkannt wurde oder nicht.
Vor und hinter einem Strichcode befinden sich die hellen Ruhezonen (in der oben stehenden Abbildung als „Quiet Zone“ bezeichnet). Ihre Breite muss bei den meisten Strichcodes mindestens die 10-fache Modulbreite bzw. 2,5 mm betragen.
Häufig wird die, in dem Strichcode enthaltene, Information zusätzlich auch noch als Text dargestellt (z. B. unterhalb des Strichcode). Dies erlaubt, dass die Daten auch von Menschen, d. h. ohne technische Hilfsmittel (Scanner) gelesen werden können.
3.3 Drucken von Strichcodes
Grundsätzlich gibt es verschiedene Möglichkeiten Strichcodes zu drucken:
- Spezialdrucker (z.B. für Etiketten)
- Drucken von (Bitmap- oder Vektor-)Grafiken, die mithilfe von spezieller Software „errechnet“ werden.
- Verwenden von speziellen Strichcode-Schriftarten
Alle genannten Möglichkeiten haben je nach Anwendungsgebiet ihre speziellen Vor- und Nachteile. Für das Ausgabe-Management von Semiramis ist wichtig, dass die betreffende Lösung zusammen mit Crystal Reports funktioniert und die Lösung möglichst druckerunabhängig ist (ein erstellter Bericht sollte auf unterschiedlichen Druckern ohne Anpassungen ausgegeben werden können). Diese Anforderungen werden am besten durch den Einsatz von Strichcode-Schriftarten erfüllt. Im Folgenden wird daher auf die anderen Verfahren, Strichcodes zu drucken, nicht weiter eingegangen.
3.3.1 Strichcode-Schriftarten
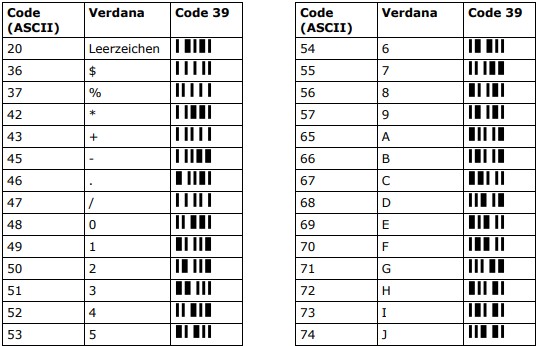
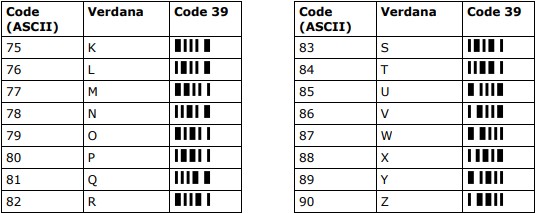
Grundsätzlich arbeiten Strichcode-Schriftarten (Fonts) wie jede andere Schriftart (Verdana, Curier, Symbol, …): Je Zeichencode (z. B. „83“) wird eine Darstellung definiert (z. B. „S“ bei „Verdana“ oder „S“ bei „Symbol“). Die nachfolgende Tabelle zeigt die unterschiedliche Darstellung von Zeichencodes in Abhängigkeit der Schriftart. Als normale Schriftart wurde hier „Verdana“ verwendet (dies ist die Standardschriftart in diesem Dokument). In der letzten Spalte sind dieselben Zeichencodes als „Strichcode-Zeichen“ (Code 39) zu sehen. Wie man sehen kann, enthält ein Zeichen aus dem Strichcode-Zeichensatz alle Elemente (Striche und Lücken), die notwendig sind, um den Zeichencode zu kodieren.
Üblicherweise repräsentiert ein Strichcode natürlich mehr als nur ein Zeichen. Wie bei normalem Text, lassen sich auch Zeichenfolgen mit den Strichcode-Schriftarten darstellen und auf diese Weise als Strichcode kodieren. Die Zeichenfolge „ABC123“, welche in „Verdana“ als „ABC123“ dargestellt wird, erscheint in „Code 39“ als:

Dies ist aber noch kein gültiger Strichcode, da mindestens das Start- und das Stoppzeichen noch fehlen. Für den hier als Beispiel verwendeten „Code 39“ ist das Zeichen „*“ (ASCII 42) als Start- und Stoppzeichen spezifiziert. In diesem Fall (Code 39) reicht es, die eigentliche Information rechts und links jeweils um „*“ zu erweitern, also aus „ABC123“ einfach „*ABC123*“ zu machen:
![]()
Wenn man jetzt noch rechts und links die Ruhezonen berücksichtigt, d.h. genügend Abstand zu anderen Elementen auf der Seite hat, lässt sich der Strichcode von einem Scanner erfassen.
Dieses einfache Verfahren funktioniert jedoch nur bei bestimmten Strichcodestandards (z.B. Code 39 oder Codabar). Bei Standards, die eine Prüfziffer (-zeichen) vorschreiben, muss diese entweder bereits in den Daten enthalten sein oder vor der Ausgabe berechnet werden. Einige Strichcodestandards verwenden auch Zeichensätze, die sich nicht 1:1 auf druckbare ASCII bzw. Unicode-Zeichen abbilden lassen. In diesen Fällen müssen die Daten erst „transformiert“ werden, bevor sie mit Hilfe einer Schriftart ausgegeben werden können. Gleiches gilt für Standards, bei denen die Kodierung von der Position (oder Nachbarzeichen) abhängig ist.
Das allgemeine Verfahren besteht daher darin, die Daten nicht direkt auszugeben, sondern vorher mit Hilfe von entsprechenden Tools in eine Zeichenfolge zu transformieren, die zu der verwendeten Schriftart passt. Im Lieferumfang von Semiramis befinden sich daher nicht nur Schriftarten für die verschiedenen Strichcodes, sondern zusätzlich auch Funktionen für Crystal Reports, um die für die jeweilige Schriftart notwendigen Zeichenketten zu berechnen.
Die nachfolgende Tabelle soll dieses Verfahren anhand von Beispielen etwas verdeutlichen:
| Code 39 | Code 128 | Interleaved 2 of 5 | EAN-13 | |
| Daten | 12345ABCDE | 1234ABCabc | 1234567890 | 401234567890 |
| Funktion | Code39 | Code128 | I2of5 | EAN13 |
| Ergebnis 1 | !12345ABCDE! | Í,BÈABabc(Î | Ë-CYo{Ì | Y(0B23EF*QRSTKL( |
| Schriftart | C39* | C128* | I25* | UPCEANL |
| Ergebnis 2 |  |
 |
 |
3.3.2 Schriftgröße
Die Ausgabe von Strichcodes mit Hilfe von Schriftarten bietet den Vorteil, dass man die Ausgabegröße in weiten Bereichen skalieren und so den gegebenen Platzverhältnissen anpassen kann[2]. Grundsätzlich sind dabei jedoch die Spezifaktionen des jeweiligen Standards zu beachten. Diese definieren beispielsweise für die Modulbreite einen Nominalwert und/oder Mindest- und Maximalwerte. Üblicherweise gibt es auch für die Strichhöhe bestimmte Vorgaben. Bei Codes mit variabler Länge wird beispielsweise die Mindesthöhe häufig als 15 % Prozent von der Gesamtlänge des Strichcodes spezifiziert, d.h. umso mehr Zeichen kodiert werden, desto größer ist die minimale Strichhöhe. Wenn man versuchen würde, dies mit Hilfe der Schriftgröße anzupassen, würde man gleichzeitig wieder die Gesamtlänge ändern – und natürlich auch die Modulbreite! Ideal wäre, wenn man die Schrift in X- und Y-Richtung unterschiedlich skalieren könnte, aber leider unterstützen dies nur wenige Programme (Crystal Reports beispielsweise nicht). Bei der Auswahl der richtigen Schriftgröße ist daher grundsätzlich anders vorzugehen: Die Schriftgröße wird nur dazu benutzt, die Modulbreite (und einhergehend die Gesamtbreite) des Strichcodes festzulegen. Die Strichhöhe ergibt durch Auswahl einer entsprechenden Schriftvariante. Dazu liegen die ausgelieferten Schriftarten jeweils in verschiedenen Größen (z.B. „XS“, „S“, „M“, „L“, „XL“ und „XXL“) vor. Die Modulbreite ist jeweils gleich, aber die Strichhöhe variiert. Es ist dann die Variante zu wählen, die möglichst gut mit den Spezifikationen bzw. den vorhandenen Platzverhältnissen harmoniert.
3.4 Strichcodes in Crystal Reports
Um in Crystal Reports Strichcodes ausgeben zu können, müssen entsprechende Schriftarten installiert sein. In den meisten Fällen ist noch zusätzliche Software erforderlich (z. B. für das Hinzufügen von Start- und Stoppzeichen sowie für das Berechnen von Prüfziffern, siehe Abschnitt Strichcode-Schriftarten). Hauptbestandteil solcher Software ist meist eine spezielle DLL mit zusätzlichen Funktionen für Crystal Reports. Diese Art von DLL wird auch als „User Function Library“ oder „UFL“ bezeichnet.
Im Lieferumfang von Semiramis sind die gebräuchlichsten (1-D) Strichcodes sowie die dafür notwendige „UFL“ bereits enthalten. Die Schriftarten wurden von „IDAutomation, Inc.“ lizenziert und dürfen nur im Zusammenhang mit Semiramis benutzt werden. Eine Erweitung um zusätzliche Strichcodes oder 2‑D Codes ist grundsätzlich möglich. Die dafür notwendigen Schriftarten und Zusatztools können beispielsweise von „IDAutomation, Inc.“ erworben werden. Neben „IDAutomation, Inc.“ gibt es auch noch weitere Anbieter, deren Lösungen kompatibel mit Crystal Reports sind.
Detaillierte Angaben über die Verwendung der ausgelieferten Schriftarten und Funktionen in Crystal Reports ist in dem Abschnitt „Strichcodes in Crystal Reports verwenden“ zu finden.
4 Installation
Bei der Installation ist zu beachten, dass die Schriftarten und die zusätzliche Software nicht nur bei dem Erstellen (Design) oder Anpassen von Reports (*.rpt Dateien) benötigt werden, sondern auch zur Laufzeit.
Um die Installation zu vereinfachen, sind die Installationsprogramme für den Semiramis ODBC Treiber und den Semiramis Output Manager (SOM) so erweitert worden, dass sie die Strichcode-Schriftarten und die Zusatzsoftware (UFL) bei Bedarf mitinstallieren. Die beiden Installationsprogramme unterscheiden sich jedoch in ihren Standardeinstellungen. So installiert das Installationsprogramm für den Semiramis ODBC Treiber in der Standardeinstellung („typisch“) überhaupt keine Strichcode-Schriftarten und auch nicht die Zusatzsoftware. Hingegen installiert das Installationsprogramm für den Semiramis Output Manager (SOM) in der Standardeinstellung („typisch“) schon eine kleine Auswahl von häufig verwendeten Strichcode-Schriftarten sowie die notwendige Zusatzsoftware. Für beide Installationsprogramme gilt aber, dass bei Anwahl der „angepassten Installation“ („Custom“), die benötigten Schriftarten manuell ausgewählt werden können[3].
Installationsfenster
Die zu installierenden Schriftarten können dann im Installationsassistenten ausgewählt werden. Für jeden Strichcodetyp stehen meistens mehrere Varianten von Schriftarten zur Verfügung, beispielsweise mit und ohne Text.
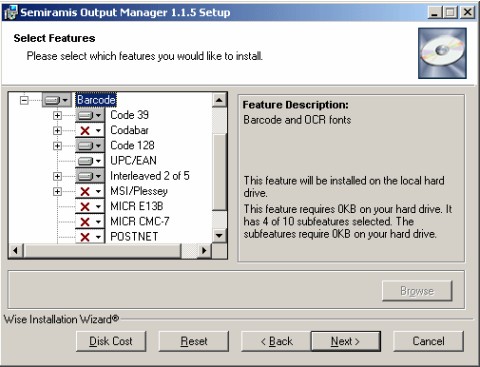
Installationsfenster
Die folgende Tabelle zeigt, welche Schriftarten den einzelnen „Features“ zugeordnet sind bzw. welches „Feature“ installiert werden, muss um eine bestimmte Schriftart nutzen zu können.
| Strichcode | Variante | Schriftarten |
| Code 39 | Standard | IDAutomationC39* |
| Extended (full ASCII) | IDAutomationXC39* | |
| Human readable fonts (Standard Code 39) | IDAutomationHC39* | |
| Human readable fonts (Extended Code 39) | IDAutomationXHC39* | |
| Codabar | With no text below the barcode | IDAutomationCB* |
| With text below the barcode | IDAutomationHCB* | |
| Code 128 | Standard Code 128 | IDAutomationC128* |
| Human readable fonts (code set B) | IDAutomationHbC128* | |
| Human readable fonts (code set C) | IDAutomationHcC128* | |
| UPC/EAN | IDAutomationUPCEAN* | |
| Interleaved 2 of 5 | With no text below the barcode | IDAutomationI25* |
| With text below the barcode | IDAutomationHI25* | |
| MSI/Plessey | With no text below the barcode | IDAutomationMSI* |
| With text below the barcode | IDAutomationHMSI* | |
| MICR E13B | E-13B IDAutomationMICR* MICR |
|
| MICR CMC-7 | IDAutomationCMC7* | |
| POSTNET | IDAutomationFIM IDAutomationPLANET* IDAutomationPOSTNET* |
|
| OCR Fonts | IDAutomationA1euro IDAutomationOCRa IDAutomationOCRb* |
Eine detaillierte Beschreibung der verschiedenen Strichcode-Typen und der zugehörigen Schriftarten ist im Abschnitt „Spezifikationen“ zu finden.
Die Installation der Zusatzsoftware (UFL für Crystal Reports) erfolgt automatisch, wenn mindestens ein (Sub-)Feature ausgewählt wurde.
4.1 Lizenzbestimmungen
Die mit Semiramis ausgelieferten und hier beschriebenen Schriftarten (Fonts) zur Darstellung von Strichcodes wurden von „IDAutomation.com, Inc.“ lizenziert. Diese Schriftarten dürfen nur in Verbindung mit Semiramis verwendet werden.
4.2 Zusätzliche Schriftarten installieren
Die mit Semiramis ausgelieferten Strichcode-Schriftarten und die dazugehörige Software unterstützen die gebräuchlichsten (1-D) Strichcodes. Eine Erweiterung um weitere Strichcodes (oder 2-D Codes) ist aber grundsätzlich möglich. Es gibt eine Vielzahl von Herstellern, die Strichcode-Schriftarten anbieten. Bei der Auswahl und Installation ist jedoch darauf zu achten, dass eine entsprechende Unterstützung für Crystal Reports vorhanden ist und die Schriftarten sowie die eventuell notwendige Zusatzsoftware sowohl auf den Client-Computern (Report-Design) als auch auf dem SOM-Computer installiert werden muss.
5 Strichcodes in Crystal Reports verwenden
Dieser Abschnitt beschreibt, wie die mit Semiramis ausgelieferten Strichcode-Schriftarten in Crystal Reports benutzt werden können, um Strichcodes zu drucken. Dabei wird davon ausgegangen, dass die benötigten Strichcode-Schriftarten sowie die zugehörige Software bereits installiert sind (siehe Kapitel „Installation“).
Wenn die Zusatzsoftware korrekt installiert wurde, stehen die Funktionen im Formeleditor von Crystal Reports unter „Funktionen/Zusätzliche Funktionen/
Visual Basic-UFLs (u2lcom.dll)“ zur Verfügung:
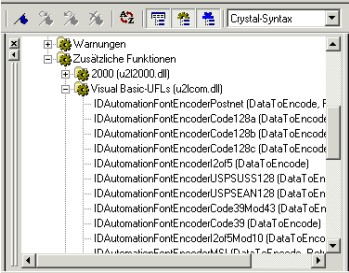
Formeleditor von Crystal Reports 9.0
5.1 Vorgehensweise
Für die meisten Strichcodes gilt, dass die Daten erst aufbereitet bzw. transformiert werden müssen, bevor sie mit einer der Strichcode-Schriftarten ausgeben werden können. Die installierten „IDAutomationFontEncoder*“-Funktionen dienen genau diesem Zweck. Welche der verfügbaren Funktionen für einen bestimmten Strichcode bzw. für eine bestimmte Schriftart zu verwenden ist, kann man dem Abschnitt „Spezifikationen“ entnehmen. Dort sind für jeden Strichcodetyp auch die Beschreibungen der zugehörigen Funktionen zu finden.
Am Beispiel des Strichcodes „Code 128“ sollen hier die in Crystal Reports notwendigen Schritte kurz erläutert werden. Das Beispiel gilt sinngemäß auch für alle anderen Strichcodetypen. Nur sind jeweils die entsprechenden Schriftarten und Funktionen zu verwenden.
5.1.1 Formelfeld erstellen
Im ersten Schritt ist ein „Formelfeld“ zu erstellen, welches aus dem gewünschten Datenfeld (hier: {app_general_Item.number}) mit Hilfe der passenden Funktion (hier: „IDAutomationFontEncoderCode128“) die Zeichenfolge berechnet, die später mit Hilfe der zugehörigen Schriftart (hier: „IDAutomationC128M“) angezeigt werden soll.
Um ein neues Formelfeld zu erstellen kann man wie folgt vorgehen:
- Im „Feld-Explorer“ mit rechtem Mausklick auf „Formelfelder“ das zugehörige Kontextmenü öffnen
- Im Kontextmenü den Punkt „Neu…“ auswählen
- Im folgenden Dialog den Namen für das Formelfeld eingeben (z.B. „Code128“) und anschließend die Schaltfläche „Editor verwenden“ drücken.
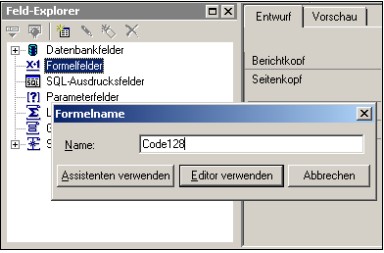
Formeleditor starten
- Es öffnet sich der Formeleditor
- Im Ordner „Funktionen“ (mittlere Spalte) den Unterordner „Zusätzliche Funktionen“ öffnen und darin wiederum den Unterordner „Visual Basic-UFLs (u2lcom.dll)“ öffnen.
- Die gewünschte Funktion auswählen (Doppelklick). In diesem Beispiel wird die Funktion „IDAutomationFontEncoderCode128“ verwendet
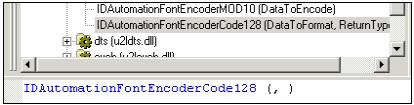
Funktion auswählen
- In diesem Fall erwartet die Funktion zwei Parameter: Die eigentlichen Daten („DataToFormat“) als Text und eine Zahl („ReturnType“), die angibt welche Art von Rückgabeergebnis gewünscht ist. In diesem Beispiel werden das Datenfeld „{app_general_Item.number}“ und der Wert „0“ (es soll die Zeichenkette für die Strichcode-Schriftart zurückgeben werden) verwendet. Die Daten sind immer als Text (String) zu übergeben. Wenn sie nicht in dieser Form vorliegen sollten, müssen sie mit Hilfe von zusätzlichen Funktionen konvertiert werden.

Formel mit Parametern
- Wenn die Formel vollständig und korrekt ist, kann sie gespeichert und der Formeleditor geschlossen werden
In einigen Fällen ist es wünschenswert, nicht nur den Strichcode, sondern zusätzlich auch einen lesbaren Text (Klarschrift) zu bekommen. Für viele der Strichcode-Schriftarten stehen daher auch Varianten zur Verfügung, die von sich aus einen solchen Text unterhalb des Strichcodes hinzufügen. Es gibt jedoch Anwendungsfälle, in denen diese Lösung unpraktikabel ist. Beispielsweise wenn man die Position, den Inhalt oder die Formatierung des Textes selbst bestimmen möchte. Zu diesem Zweck besitzen einige Funktionen den Parameter „ReturnType“. Wenn man hier den Wert „1“ übergibt, liefern diese Funktionen eine Zeichenkette, die man für eine Klarschriftausgabe verwenden kann. Das Ergebnis ist dabei abhängig vom Strichcodetyp und kann neben den eigentlichen Daten auch manchmal eine Prüfziffer oder zusätzliche Formatierungen enthalten.
Wenn man einen solchen Text ausgeben möchte, ist dafür ein weiteres Formelfeld zu definieren. In diesem Beispiel wird es „Code128Text“ genannt. Die oben aufgeführten Punkte 1 bis 8 sind dazu einfach zu wiederholen, wobei allerdings bei Punkt 3 „Code128Text“ als Formelname zu verwenden ist und bei Punkt 7 der Wert „1“ zu übergeben ist:

Formel für Klarschrifttext
5.1.2 Formelfeld verwenden
Die erstellten Formelfelder kann man jetzt (statt der eigentlichen Datenfelder) in dem Bericht verwenden. Man kann sie beispielsweise aus dem Feld-Explorer einfach in den Entwurf (z.B. Detailbereich) „ziehen“:
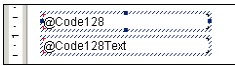
Formelfelder in der Entwurfsansicht
Wenn man jetzt in die Vorschau-Ansicht wechselt, sieht man welche Ergebnisse die Formelfelder zurückliefern:

Formelfelder in der Vorschau
Bei einigen Strichcodes (z.B. Code 128 und Interleaved 2 of 5) werden die Zeichenketten stärker transformiert als bei anderen (z.B. Code 39). So kann es durchaus vorkommen, dass das Ergebnis scheinbar „verschlüsselt“ aussieht bzw. „merkwürdige“ Zeichen am Anfang oder Ende stehen.
Jetzt sollte man wieder in die Entwurfsansicht wechseln und dort für das Formelfeld, das den Strichcode ausgeben soll (hier „Code128“), die Schriftart ändern (hier „IDAutomationC128M“).
Hinweis: Schriftarten, die mit „@“ beginnen sollten nicht verwendet werden, da dies zu fehlerhaften Strichcodes führen kann. Stattdessen sind immer die Schriftarten zu verwenden, die mit direkt „IDAutomation“ beginnen.
Als Nächstes sollte die Schriftgröße angepasst werden, wobei die Spezifikation des jeweiligen Strichcodes bzw. des verwendeten Scanners zu beachten ist (siehe Abschnitt „Druckhinweise“). Schließlich ist noch die Feldgröße so anzupassen, dass der Strichcode vollständig angezeigt wird.
Hinweis:
In der Entwurfsansicht wird der Name des Formelfeldes mit der Strichcode-Schriftart dargestellt. Zur Beurteilung des Ergebnisses und des Platzbedarfs sollte daher besser die Vorschau benutzt werden.
Das Ergebnis dieses Beispiels sieht dann in der Vorschau folgendermaßen aus:

6 Übersicht
Dieses Kapitel bietet einen Überblick über die im Lieferumfang von Semiramis enthaltenen bzw. unterstützten Strichcodes, OCR- und MICR-Schriftarten. Es sei darauf hingewiesen, dass es auch Standards gibt, die keinen eigenen Strichcode (Symbologie) definieren, sondern auf einem bestehenden Strichcodestandard (Symbologie) aufsetzen. In der Regel werden bei solchen „abgeleiteten“ Standards lediglich konkretere Vorschriften für einige Parameter (Größe, Daten, Prüfziffer etc.) festgelegt. Beispiele hierfür sind EAN 128 (bzw. UCC 128), der auf dem „Code 128“ basiert, und „SSC-14“, der auf dem „Interleaved 2 of 5“ basiert.
Im ersten Teil dieses Überblicks werden dazu alle Strichcodes und Schriftarten mit typischen Daten exemplarisch aufgelistet (visueller Index). Der zweite Teil zeigt (als Kurzfassung), welche konkreten Schriftarten und Funktionen für einen bestimmten Strichcodetyp bzw. Standard zu verwenden sind. Eine detaillierte Beschreibung ist im Kapitel „Spezifikationen“ zu finden.
6.1 Beispiele
Die folgende Tabelle listet alle in Semiramis enthaltenen Strichcodes, OCR- und MICR-Schriftarten mit typischen Daten exemplarisch auf (visueller Index):
| Typ | Daten/Symbol |
| Codabar | 1234567890
|
| Code 2/5 Interleaved | 1234567890
|
| Code 39 | 12345ABCDE
|
| Code 39 Extended | 1234ABCabc
|
| Code 128 | 1234ABCabc
|
| EAN-8 |  |
| EAN-13 |  |
| EAN-13 mit Addon 2 |  |
| EAN-13 mit Addon 5 |  |
| EAN-18 NVE SSCC-18 |
 |
| EAN-128 UCC-128 |
 |
| FIM |  |
| MICR CMC‑7 | |
| MICR E13‑B | |
| MSI / Plessey |  |
| OCR-A | |
| OCR-B | 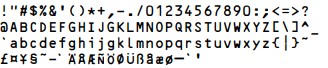 |
| PLANET | |
| POSTNET | |
| SCC-14 (ITF-14) |  |
| SCC-14 (EAN-128) |  |
| UPC-A |  |
| UPC-E |  |



6.2 Kurzreferenz
Die nachfolgende Tabelle zeigt, welche Schriftarten und welche Funktionen für einen bestimmten Strichcode bzw. eine bestimmte Symbologie vorgesehen sind. Zusätzlich zu den Schriftarten ist auch der empfohlene Mindest- oder Nominalwert für die Schriftgröße angegeben.
| Standard | Symbologie | Schriftart | Schriftgröße | Funktionen |
| Codabar | Codabar | CB*, HCB* |
12 pt | Codabar |
| Code 2/5 Interleaved | Code 2/5 Interleaved | I25*, HI25* |
12 pt | I2of5, I2of5Mod10 |
| Code 39 | Code 39 | C39*, HC39* |
12 pt | Code39, Code39Mod43 |
| Code 39 Extended | Code 39 (extended) | XC39*, XHC39* |
12 pt | |
| Code 128 | Code 128 | C128*, HbC128*, HcC128* |
12 pt | Code128, Code128a, Code128b, Code128c |
| EAN-8 | EAN/UPC | UPCEANM | 20 pt (nominal) | EAN8 |
| EAN-13 | EAN/UPC | UPCEANL | 20 pt (nominal) | EAN13 |
| EAN/UCC-18 SSCC-18 |
EAN-128 | C128* | X = 0,25 mm | SSCC18 Code128 |
| EAN/UCC-128 | Code 128 | C128* | X = 0,25 mm | UCC128 Code128 |
| FIM | FIM | 36 pt (48 pt) |
||
| JAN | EAN/UPC | UPCEANL | 20 pt (nominal) | EAN13 |
| MICR CMC‑7 | CMC7 | 12 pt (nominal) | ||
| MICR E13‑B | MICR | 12 pt (nominal) | ||
| MSI / Plessey | MSI / Plessey | MSI*, HMSI* |
12 pt | MSI |
| OCR-A | A1euro OCRa |
9 pt (nominal) (12 pt) |
||
| OCR-B | OCRb | 14 pt (nominal) | ||
| PLANET | PLANET | PLANET* | 12 pt (nominal) | Postnet |
| POSTNET | POSTNET | POSTNET* | 12 pt (nominal) | Postnet |
| SCC-14 (ITF-14) |
Code 2/5 Interleaved | I25*, HI25* |
X = 1,016 mm (nominal) | I2of5Mod10 |
| SCC-14 (EAN-128) |
EAN-128 | C128* | X = 1,016 mm (nominal) | SCC14 Code128 |
| UPC-A | EAN/UPC | UPCEANL | 20 pt (nominal) | UPCa |
| UPC-E | EAN/UPC | UPCEANL | 20 pt (nominal) | UPCe |
| USPS (EAN128) | EAN-128 | C128L | 20 pt (nominal) | USPS_EAN128 Code128 |
7 Spezifikationen
Die hier aufgeführten Beschreibungen zu den Strichcode-Standards und Schriftarten soll deren Verwendung im Zusammenhang mit Semiramis vereinfachen. Ausführliche Informationen zu den jeweiligen Standards sind in der Regel bei den jeweiligen Organisationen (ANSI, DIN/EN, AIM, EAN, …) verfügbar (siehe Kapitel „Weitere Informationen“). Zusätzliche Informationen über die Strichcode-Schriftarten sind unter http://www.idautomation.com/ verfügbar.
7.1 Codabar
7.1.1 Eigenschaften
| Eigenschaft | Ausprägung |
| Spezifikation (Standard) | EN 798, ANSI/AIM BC3‑1995 |
| Synonyme | NW-7, USD-4, 2 of 7 |
| Anwendungsgebiete | Medizinischer Bereich (Blutbanken), Büchereien, FedEx |
| Zeichensatz (-umfang) | Numerischer Code mit 6 zusätzlichen Sonderzeichen (Ziffern 0 – 9, -, $, :, /, ., +). |
| Länge | variabel (keine fest vorgegebene Länge) |
| Start- /Stoppzeichen | Die Zeichen „A“, „B“, „C“ und „D“ können anwendungsspezifisch als Start- bzw. Stoppzeichen verwendet werden. |
| Prüfziffer | Keine |
| Aufbau | Jeweils 4 Striche und 3 Lücken, wobei entweder 2 breite und 5 schmale oder 3 breite und 4 schmale Elemente verwendet werden. |
| Selbstüberprüfbar | ja |
| Druckverhältnis „V“ | Das Verhältnis von breiten zu schmalen Elementen muss zwischen 2,25:1 und 3:1 liegen |
| Ruhezonen | 10-fache Modulbreite (10 X) bzw. 0,1 Zoll (2,54 mm) |
| Informationsdichte | 5,5 mm/Ziffer bei Modulbreite X = 0,3 mm und Druckverhältnis V = 3:1 |
| Vorteil | Außer 0 ‑ 9 lassen sich noch 6 Sonderzeichen darstellen |
| Nachteil | Niedrige Informationsdichte |
7.1.2 Schriftarten
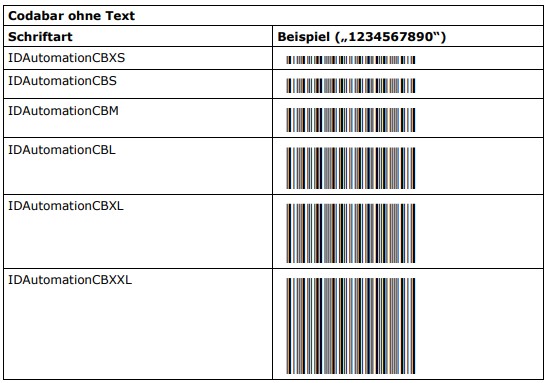
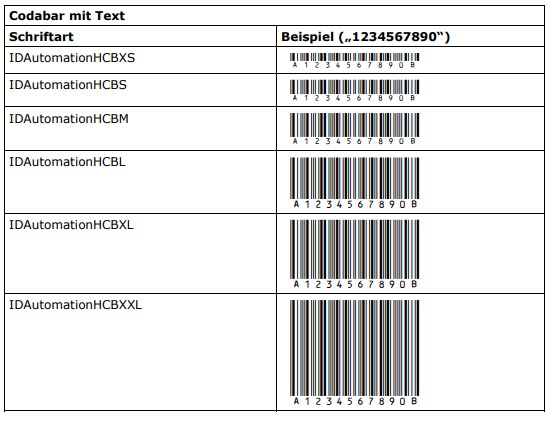
Für Codabar werden Schriftarten in zwei Varianten angeboten:
- Ohne Text (IDAutomationCB*)
- Mit Text unterhalb des Strichcodes (IDAutomationHCB*)
Zu jeder Variante existieren wiederum 6 Subvarianten, die sich jeweils in ihrer Strichhöhe unterscheiden:
- XS (19,2%)
- S (34,6%)
- M (57,7%)
- L (100%)
- XL (142,3%)
- XXL (230,8%)
Die empfohlene Schriftgröße für alle Varianten und Subvarianten ist 12 Punkt. Bei dieser Schriftgröße ergibt sich für alle Varianten und Subvarianten die empfohlene Mindestmodulbreite von ca. 0,19 mm bzw. 7,5 mil (1 mil = 1/1000″). Die jeweilige Strichhöhe hängt von der gewählten Subvariante und Schriftgröße ab. Die Strichhöhe der „L“-Varianten beträgt beispielsweise bei einer Schriftgröße von 12 Punkt ca. 12,7 mm bzw. 1/2″. Die nachfolgenden Tabellen zeigen die Schriftarten jeweils bei 12 Punkt.
7.1.3 Funktionen für Crystal Reports
Für Codabar steht folgende Funktion (Visual Basic UFLs) zur Verfügung:
IDAutomationFontEncoderCodabar
IDAutomationFontEncoderCodabar
Diese Funktion fügt der übergebenen Zeichenkette am Anfang ein „A“ (Startzeichen) und am Ende ein „B“ (Stoppzeichen) hinzu.
Hinweis: Bei Codabar können anwendungsspezifisch die Buchstaben „A“, „B“, „C“ bzw. „D“ als Start- bzw. Stoppzeichen verwendet werden. Diese Funktion verwendet aber grundsätzliche „A“ als Start- und „B“ als Stoppzeichen.
Hinweis: Diese Funktion kann in Crystal Reports auch einfach als Formel nachgebildet werden, z.B. mit: ‘A’ + {Table.Field} + ‘B’.
| Parameter | Beschreibung |
| DataToEncode | Die um die Start- und Stoppzeichen zu erweiternde Zeichenkette. Die Zeichenkette darf nur die Ziffern 0-9 und die Sonderzeichen „-“, „$“, „:“, „/“, „.“, „+“ enthalten. |
Beispiele
| DataToEncode | Ergebnis | IDAutomationHCBM (12 pt) |
| 1234567890 | A1234567890B |
7.2 Code 2/5 Interleaved
7.2.1 Eigenschaften
| Eigenschaft | Ausprägung |
| Spezifikation (Standard) | EN 801, ANSI/AIM BC2‑1995 |
| Synonyme | USS ITF 2/5, ITF |
| Verwandte Standards | ITF-14, EAN-14, SSC-14, DUN-14 |
| Anwendungsgebiete | Artikelnummerierung, industrielle Anwendungen |
| Zeichensatz (-umfang) | Numerischer Code (Ziffern 0 – 9) |
| Länge | variabel (keine fest vorgegebene Länge), aber nur gerade Anzahl von Ziffern möglich |
| Prüfziffer | Optional (Modulo 10) |
| Aufbau | Jeweils 2 breite und 3 schmale Striche bzw. 2 breite und drei schmale Lücken. Ziffern werden abwechselnd (interleaved) mit Strichen und Lücken dargestellt (1., 3., 5., … Ziffer als Striche; 2., 4., 6. ,… Ziffer als Lücke). |
| Selbstüberprüfbar | ja |
| Druckverhältnis „V“ | Das Verhältnis von breiten zu schmalen Elementen muss zwischen 2:1 und 3:1 liegen (mindestens 2,25:1 wenn die Modulbreite X kleiner als 0,50 mm ist) |
| Ruhezonen | 10-fache Modulbreite (10 X) bzw. 0,1 Zoll (2,54 mm) |
| Informationsdichte | 2,7 mm/Ziffer bei Modulbreite X = 0,3 mm und Druckverhältnis V = 3:1 |
| Vorteil | Hohe Informationsdichte |
| Nachteil | Kleine Toleranz |
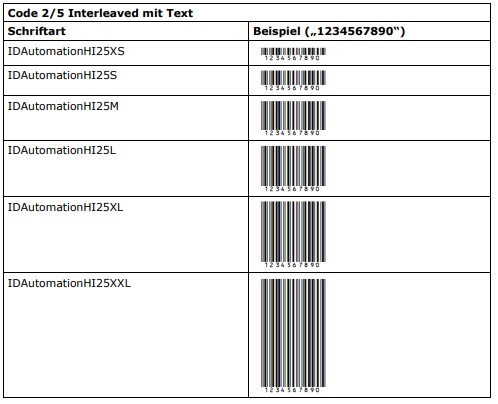
7.2.2 Schriftarten
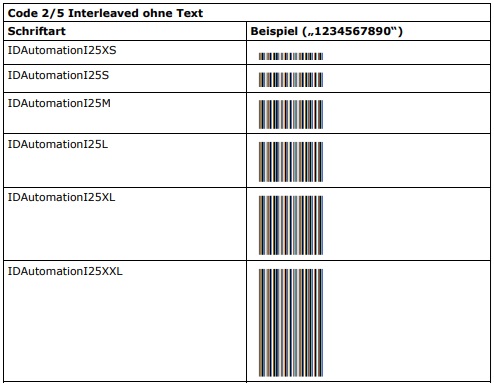
Für „Code 2/5 Interleaved“ werden Schriftarten in zwei Varianten angeboten:
- Ohne Text (I25*)
- Mit Text unterhalb des Strichcodes (HI25*)
Zu jeder Variante existieren wiederum 6 Subvarianten, die sich jeweils in ihrer Strichhöhe unterscheiden:
- XS (12,5%)
- S (25%)
- M (70,8%)
- L (100%)
- XL (137,5%)
- XXL (250%)
Das Verhältnis von schmalen zu breiten Elementen beträgt 2,75.
Die empfohlene Schriftgröße für alle Varianten und Subvarianten ist 12 Punkt. Bei dieser Schriftgröße ergibt sich für alle Varianten und Subvarianten die empfohlene Mindestmodulbreite von ca. 0,21 mm bzw. 8 mil (1 mil = 1/1000″). Die jeweilige Strichhöhe hängt von der gewählten Subvariante und Schriftgröße ab. Die Strichhöhe der „L“-Varianten beträgt beispielsweise bei einer Schriftgröße von 12 Punkt ca. 12,7 mm bzw. 1/2″. Die nachfolgenden Tabellen zeigen die Schriftarten jeweils bei 12 Punkt.
7.2.3 Funktionen für Crystal Reports
Bei Code 2/5 Interleaved werden Ziffernfolgen jeweils paarweise als Striche (erste Ziffer) und Lücken (zweite Ziffer) kodiert. Die Schriftarten IDAutomationI25* und IDAutomationHI25* unterstützen dies, indem sie die Strichfolgen für solche „Doppelziffern“ jeweils in einem Unicode-Zeichen zusammenfassen. Um eine Ziffernfolge mit diesen Schriftarten ausgeben zu können, müssen die Ziffern zuvor in eine Folge von Unicode-Zeichen umgerechnet werden. Dazu dient die Funktion IDAutomationFontEncoderI2of5. Weiterhin werden von dieser Funktion die Start- und Stoppzeichen ergänzt. Prüfziffern werden bei Code 2/5 Interleaved normalerweise nicht verwendet, da der Code bereits „selbstprüfend“ ist.
Bei einigen Spezialanwendungen ist jedoch eine zusätzliche Prüfziffer vorgeschrieben (siehe ITF-14 bzw. SCC-14), in diesen Fällen ist die Funktion IDAutomationFontEncoderI2of5Mod10 zu verwenden.
7.2.3.1 IDAutomationFontEncoderI2of5
Diese Funktion unterstützt als Parameter nur Ziffernfolgen mit einer geraden Anzahl von Ziffern.
| Parameter | Beschreibung |
| DataToEncode | Die als Code 2/5 Interleaved zu kodierende Zeichenfolge. Es erlaubt Ziffern (0-9), und die Anzahl der Ziffern muss gerade sein (sonst wird automatisch eine 0 vorangestellt). Start- und Stoppzeichen sind nicht anzugeben. |
Beispiele
| DataToEncode | Ergebnis | IDAutomationHI25M (12 pt) |
| 1234567890 | Ë-CYo{Ì | |
| 123456789 | Ë”8NdzÌ |
7.2.3.2 IDAutomationFontEncoderI2of5Mod10
Diese Funktion unterstützt als Parameter nur Ziffernfolgen mit einer ungeraden Anzahl von Ziffern (durch das automatische Hinzufügen der Prüfziffer ergibt sich wieder eine gerade Anzahl von Ziffern).
| Parameter | Beschreibung |
| DataToEncode | Die als Code 2/5 Interleaved zu kodierende Zeichenfolge. Es erlaubt Ziffern (0-9), und die Anzahl der Ziffern muss ungerade sein (sonst wird automatisch eine 0 vorangestellt). Start-, Prüf- und Stoppzeichen sind nicht anzugeben. |
| ReturnType | Ein numerische Wert, der angibt, welche Daten die Funktion zurückliefern soll:
0 Die notwendige Zeichenfolge für die Schriftarten „IDAutomationI25*“ bzw. „IDAutomationHI25*“ inkl. aller Steuerzeichen (z.B. Start-, Prüf- und Stoppzeichen). 1 Die Daten in Klarschrift inkl. Prüfziffer, aber ohne Start- und Stoppzeichen. 2 Nur die Prüfziffer |
Beispiele
| DataToEncode | Ergebnis (0, 1, 2) | IDAutomationHI25M (12 pt) |
| 123456789 | Ë-CYoÆÌ, 1234567895, 5 |
 |
| 1234567890 | Ë”8Ndz&Ì, 012345678905, 5 |
7.3 Code 39
7.3.1 Eigenschaften
| Eigenschaft | Ausprägung |
| Spezifikation (Standard) | EN 800, ANSI/AIM BC1‑1995 |
| Verwandte Standards | LOGMARS[4] |
| Anwendungsgebiete | Elektronik, Industrie, Behörden und Handel |
| Zeichensatz (-umfang) | Alphanumerischer Code (Ziffern 0 – 9, 26 Buchstaben und 7 Sonderzeichen). Mit Hilfe einer Zweizeichen-Kodierung ist eine Erweitung auf den vollständigen ASCII-Zeichensatz möglich (siehe Erweiterter Zeichensatz (Code 39 Extended)) |
| Länge | variabel (keine fest vorgegebene Länge) |
| Start- / Stoppzeichen | Das „*“-Zeichen wird sowohl als Start- als auch als Stoppzeichen verwendet. |
| Prüfzeichen | Optional (Modulo 43) |
| Aufbau | Diskreter Code. Jeweils 5 Striche und 4 Lücken, wobei (mit Ausnahme der Sonderzeichen) jeweils 3 breite und 6 schmale Elemente verwendet werden. Die Lücken zwischen den Zeichen tragen keine Information. |
| Selbstüberprüfbar | ja |
| Modulbreite „X“ | Für offene Systeme sollte die Modulbreite X den Wert von 7,5 mil (0,19 mm) nicht unterschreiten. |
| Druckverhältnis „V“ | Das Verhältnis von breiten zu schmalen Elementen muss zwischen 2:1 und 3:1 liegen (mindestens 2,25:1, wenn die Modulbreite X kleiner als 0,50 mm ist). |
| Strichhöhe | Die Strichhöhe sollte mindestens 15% der Gesamtbreite bzw. 0,25 Zoll (6,35 mm) entsprechen. Wobei die Gesamtbreite näherungsweise[5] mit folgender Formel berechnet werden kann:
B = (C + 2)16X |
| Ruhezonen | 10-fache Modulbreite (10 X) bzw. 0,1 Zoll (2,54 mm) |
| Informationsdichte | 4,8 mm/Ziffer bei Modulbreite X = 0,3 mm und Druckverhältnis V = 3:1 |
| Vorteil | Alphanumerische Darstellung möglich |
| Nachteil | Niedrige Informationsdichte, kleine Toleranz |
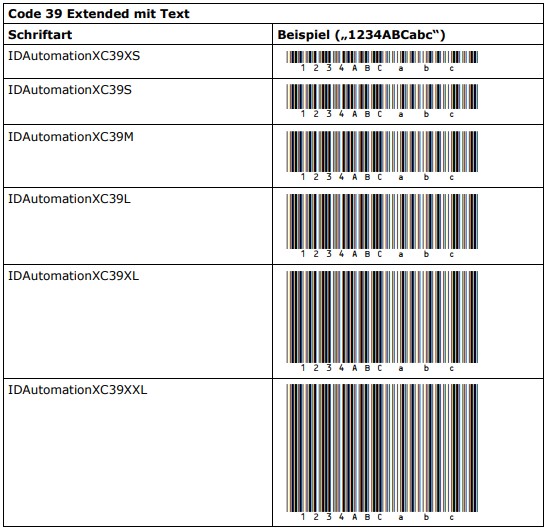
Erweiterter Zeichensatz (Code 39 Extended)
Es existiert eine Variante des Code 39, der so genannten „Extended Code 39“, der den vollständigen ASCII Zeichensatz unterstützt. Dies wird dadurch erreicht, dass alle Kleinbuchstaben, Sonder- und Steuerzeichen als Folge von jeweils zwei Zeichen kodiert werden. Dazu werden die Zeichen „+“, „/“, „%“ und „$“ als „Umschalt“-Zeichen verwendet. Da diese Zeichen beim Extended Code 39 anders interpretiert werden als im Standardfall, müssen die Lesegeräte allerdings entsprechend konfiguriert werden (eine automatische Erkennung ist im Allgemeinen nicht möglich).
Der Extended Code 39 hat keine besonders große Verbreitung gefunden, da bei entsprechenden Anwendungsfällen eher der Code 128 zum Einsatz kommt: Dieser unterstützt ebenfalls alle ASCII-Zeichen, verfügt aber über eine höhere Dichte.
Semiramis bzw. die mitgelieferten Strichcode-Schriftarten und Funktionen bieten nur eine eingeschränkte Unterstützung für den Extended Code 39: Die Schriftarten IDAutomationXC39* bzw. IDAutomationXHC39* sorgen selbst für korrekte Umsetzung von ASCII-Zeichen auf die Zweizeichen-Codes. Eine spezielle Funktion zum Hinzufügen von Start-, Stopp oder gar Prüfzeichen steht aber nicht zur Verfügung, dies muss also manuell erfolgen. Auch Leerzeichen müssen speziell behandelt (durch „~“ ersetzt) werden.
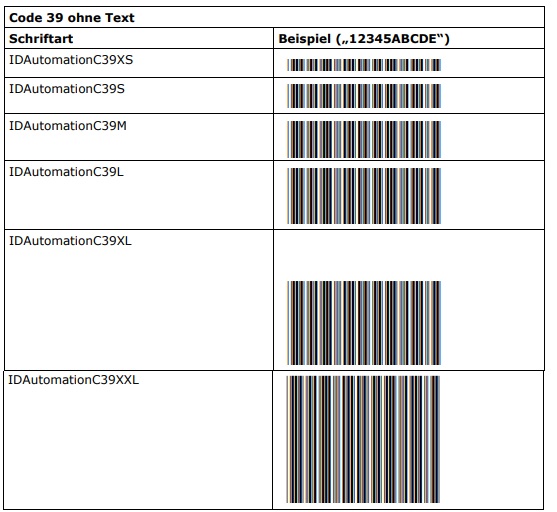
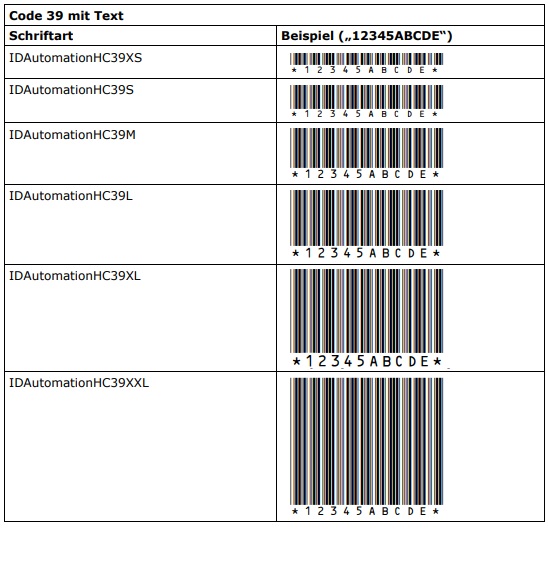
7.3.2 Schriftarten
Für Code 39 werden Schriftarten in zwei Varianten angeboten:
- Ohne Text (C39*)
- Mit Text unterhalb der Striche (HC39*)
Für den erweiterten (extended) Code 39 werden zwei zusätzliche Varianten angeboten (siehe oben):
- Ohne Text (XC39*)
- Mit Text unterhalb der Striche (XHC39*)
Zu jeder Variante existieren wiederum 6 Subvarianten, die sich jeweils in ihrer Strichhöhe unterscheiden:
- XS (21,2%)
- S (42,3%)
- M (71,2%)
- L (100%)
- XL (150%)
- XXL (227,3%)
Die empfohlene Schriftgröße für alle Varianten und Subvarianten ist 12 Punkt. Bei dieser Schriftgröße ergibt sich für alle Varianten und Subvarianten die empfohlene Mindestmodulbreite von ca. 0,21 mm bzw. 8 mil (8/1000″). Die jeweilige Strichhöhe hängt von der gewählten Subvariante und Schriftgröße ab. Die Strichhöhe der „L“-Varianten beträgt beispielsweise bei einer Schriftgröße von 12 Punkt ca. 12,7 mm bzw. 1/2″. Die nachfolgenden Tabellen zeigen die Schriftarten jeweils bei 12 Punkt.
7.3.3 Funktionen für Crystal Reports
Für Code 39 stehen folgende Funktionen (Visual Basic UFLs) zur Verfügung:
- IDAutomationFontEncoderCode39
- IDAutomationFontEncoderCode39Mod43
Die erste Funktion fügt nur Start- und Stoppzeichen („!“) hinzu, lässt die übergebenen Daten aber ansonsten unverändert (Ausnahme: Leerzeichen). Die zweite fügt zusätzlich noch ein Prüfzeichen (Modulo 43) ein, verhält sich aber ansonsten identisch.
Für den Code 39 Extended sind keine speziellen Funktionen vorhanden. Bei Verwendung der Schriftarten IDAutomationC39* bzw. IDAutomationHC39* können die Funktionen für Code 39 verwendet werden. Es ist jedoch zu beachten, dass die für den erweiterten Zeichensatz notwendige Kodierung nicht durch diese Funktionen erfolgt, sie fügen lediglich die Start-, Stopp- bzw. Prüfzeichen hinzu.
Die Funktionen für Code 39 sind nicht kompatibel mit den Schriftarten IDAutomationXC39* bzw. IDAutomationXHC39*. Dafür übernehmen diese Schriftarten die notwendige Zwei-Zeichen-Kodierung für den erweiterten Zeichensatz selbst. Start- und Prüfzeichen („*“) müssen aber manuell (z.B. per Formel) hinzugefügt werden. Falls ein Prüfzeichen benötigt wird, muss dies ebenfalls manuell berechnet werden. In diesem Fall bringt die Verwendung dieser Schriftarten nur wenig Vorteile und es sollte stattdessen mit den Schriftarten IDAutomationC39* bzw. IDAutomationHC39* gearbeitet werden (d.h. manuelle Kodierung des erweiterten Zeichensatzes, aber Prüfziffer über Funktion).
7.3.3.1 IDAutomationFontEncoderCode39
Diese Funktion fügt der übergebenen Zeichenkette am Anfang und Ende jeweils das Zeichen „!“ hinzu. Dieses Zeichen wird von den Schriftarten IDAutomationC39* bzw. IDAutomationHC39* als Start- und Stoppzeichen interpretiert.
In der Regel findet, anders als beispielsweise bei „IDAutomationFontEncoderCode128“, keine Transformation der übergebenen Zeichen statt. Eine Ausnahme stellen Leerzeichen dar, diese werden durch „=“ ersetzt[6]. Die Schriftart IDAutomationC39* ist so entworfen, dass sie aus dem „=“ den Strichcode für das Leerzeichen erzeugt.
Hinweis: Bei den Schriftarten IDAutomationC39* und IDAutomationHC39* kann sowohl „*“ als auch „!“ benutzt werden, um das Start- bzw. Stoppzeichen zu erzeugen. Bei den Schriftarten IDAutomationXC39* und IDAutomationXHC39* für den Code 39 Extended ist hingegen nur „*“ zulässig, daher kann diese Funktion für diese Schriftarten nicht benutzt werden.
Hinweis: Unter der Voraussetzung, dass in den Daten kein Leerzeichen vorkommen kann, kann diese Funktion in Crystal Reports auch einfach als Formel nachgebildet werden, z.B. mit: ‘*’ + {Table.Field} + ‘*’. Dies funktioniert dann auch mit den Schriftarten IDAutomationXC39* und IDAutomationXHC39*.
| Parameter | Beschreibung |
| DataToEncode | Die um die Start- und Stoppzeichen zu erweiternde Zeichenkette. |
Beispiele
| DataToEncode | Ergebnis | IDAutomationHC39M (12 pt) |
| 1234567890 | !1234567890! |  |
| ABCDEFGHIJ | !ABCDEFGHIJ! |  |
| abcdefghij | !abcdefghij! |  |
| +A+B+C+D+E | !+A+B+C+D+E! |  |
7.3.3.2 IDAutomationFontEncoderCode39Mod43
Diese Funktion fügt der übergebenen Zeichenkette am Anfang und Ende jeweils das Zeichen „!“ hinzu und transformiert ggf. Leerzeichen in „=“ (siehe IDAutomationFontEncoderCode39). Zusätzlich wird ein Prüfzeichen berechnet (Modulo43) und vor dem Stoppzeichen eingefügt.
Hinweis: Diese Funktion ist wie IDAutomationFontEncoderCode39 nicht kompatibel mit den Schriftarten IDAutomationXC39* und IDAutomationXHC39*.
| Parameter | Beschreibung |
| DataToEncode | Die um die Start-, Prüf- und Stoppzeichen zu erweiternde Zeichenkette. Kleinbuchstaben werden automatisch in Großbuchstaben umgewandelt. |
| ReturnType | Ein numerische Wert, der angibt, welche Daten die Funktion zurückliefern soll:
0 Die notwendige Zeichenfolge für die Schriftarten „IDAutomationC39*“ bzw. „IDAutomationHC39*“ inkl. aller Steuerzeichen (z.B. Start-, Prüf- und Stoppzeichen). 1 Die Daten in Klarschrift inkl. Prüfziffer, aber ohne Start- und Stoppzeichen. 2 Nur die Prüfziffer |
Beispiele
| DataToEncode | Ergebnis (0, 1, 2) | IDAutomationHC39M (12 pt) |
| 1234567890 | !12345678902!, 12345678902, 2 |
 |
| ABCDEFGHIJ | !ABCDEFGHIJG!, ABCDEFGHIJG, G |
 |
| abcdefghij | !ABCDEFGHIJG!, ABCDEFGHIJG, G |
 |
| +A+B+C+D+E | !+A+B+C+D+E7!, +A+B+C+D+E7, 7 |
 |
7.4 Code 128
Code 128 ist ein universeller Strichcode, der alle 128 Zeichen des ASCII-Zeichensatzes unterstützt.
7.4.1 Eigenschaften
| Eigenschaft | Ausprägung |
| Spezifikation (Standard) | EN 799, ANSI/AIM BC4‑1999 |
| Verwandte Standards | EAN/UCC 128[7], SSCC-18, SCC-14 |
| Anwendungsgebiete | Logistik |
| Zeichensatz (-umfang) | · Alle 128 ASCII Zeichen (0 ‑ 127)
· 4 Steuerzeichen (FCN1 ‑ FCN4) · 4 Steuerzeichen zur Zeichensatzauswahl · 3 Startzeichen · 1 Stoppzeichen |
| Länge | variabel (keine fest vorgegebene Länge) |
| Start-/Stoppzeichen | Spezielle, nicht druckbare Codes. Drei verschiedene Startcodes (zur Zeichensatzauswahl) |
| Prüfziffer | Pflicht (Modulo 103) |
| Aufbau | kontinuierlicher Code mit vier unterschiedlichen Elementbreiten (1, 2, 3 und 4‑fach). Jedes Zeichen besteht aus jeweils 3 Strichen und 3 Lücken, die zusammen immer die Breite von 11 Modulen (X) ergeben. Die einzige Ausnahme ist das Stoppzeichen, welches aus 4 Strichen und 3 Lücken besteht und insgesamt 13 Module breit ist. |
| Selbstüberprüfbar | ja |
| Bidirektional lesbar | ja |
| Modulbreite „X“ | Für offene Systeme sollte die Modulbreite X den Wert von 7,5 mil (0,19 mm) nicht unterschreiten. |
| Ruhezonen | 10-fache Modulbreite (10 X) bzw. 0,1 Zoll (2,54 mm) |
| Informationsdichte | 11 Module/Zeichen (5,5 Module/Zeichen bei Zeichensatz C) |
| Overhead | 35 Module (Start-, Prüf- und Stoppzeichen) |
| Vorteil | Alphanumerische Darstellung möglich |
| Nachteil | kleine Toleranz |
7.4.2 Schriftarten
Für Code 128 werden Schriftarten in drei Varianten angeboten:
- Ohne Text (C128*)
- Mit Text (Zeichensatz „B“) unterhalb der Striche (HbC128*)
- Mit Text (Zeichensatz „C“) unterhalb der Striche (HcC128*)
Hinweis: Die Versionen mit Text werden selten verwendet, da sie auch das Prüfzeichen (Modulo 103) enthalten. Normalerweise ist es besser, die Variante ohne Text zu wählen und zusätzlich die Daten mit einer normalen Schriftart als Text über oder unter dem Strichcode zu drucken.
Zu jeder Variante existieren wiederum 6 Subvarianten, die sich jeweils in ihrer Strichhöhe unterscheiden:
- XS (12,5%)
- S (25%)
- M (50%)
- L (100%)
- XL (125%
- XXL (200%)
Die empfohlene Schriftgröße für alle Varianten und Subvarianten ist 12 Punkt. Bei dieser Schriftgröße ergibt sich für alle Varianten und Subvarianten die empfohlene Mindestmodulbreite von ca. 0,21 mm bzw. 8 mil (8/1000″). Die jeweilige Strichhöhe hängt von der gewählten Subvariante und Schriftgröße ab. Die Strichhöhe der „L“-Varianten beträgt beispielsweise bei einer Schriftgröße von 12 Punkt ca. 12,7 mm bzw. 1/2″. Die nachfolgenden Tabellen zeigen die Schriftarten jeweils bei 12 Punkt.
| Code 128 ohne Text | |
| Schriftart | Beispiel („1234ABCabc“) |
| IDAutomationC128XS | |
| IDAutomationC128S | |
| IDAutomationC128M | |
| IDAutomationC128L | |
| IDAutomationC128XL |  |
| IDAutomationC128XXL |  |
| Code 128 mit Text (Zeichensatz „B“) | |
| Schriftart | Beispiel („1234ABCabc“) |
| IDAutomationHbC128XS | |
| IDAutomationHbC128S | |
| IDAutomationHbC128M | |
| IDAutomationHbC128L |  |
| IDAutomationHbC128XL |  |
| IDAutomationHbC128XXL |  |
| Code 128 mit Text (Zeichensatz „C“) | |
| Schriftart | Beispiel („1234567890“) |
| IDAutomationHcC128XS | |
| IDAutomationHcC128S | |
| IDAutomationHcC128M | |
| IDAutomationHcC128L |  |
| IDAutomationHcC128XL |  |
| IDAutomationHcC128XXL |  |
7.4.3 Funktionen für Crystal Reports
Um die für Code 128 erforderlichen Berechnungen (Prüfzeichen) und Zeichensatzumformungen durchzuführen stehen folgende Funktionen (Visual Basic UFLs) zur Verfügung:
- IDAutomationFontEncoderCode128
- IDAutomationFontEncoderCode128a
- IDAutomationFontEncoderCode128b
- IDAutomationFontEncoderCode128c
Für die meisten Anwendungsfälle empfiehlt sich die Funktion „IDAutomationFontEncoderCode128“, da sie den vollen ASCII Zeichenumfang unterstützt und automatisch die richtigen/optimalen Zeichensätze für Code 128 auswählt.
7.4.3.1 IDAutomationFontEncoderCode128
Diese Funktion unterstützt alle Zeichen von ASCII 0 bis ASCII 127. Der notwendige bzw. optimale Zeichensatz wird dabei automatisch ausgewählt und ggf. dynamisch gewechselt. Es wird auch EAN/UCC-128 unterstützt. Weitere Angaben dazu sind in dem Abschnitt EAN/UCC 128 zu finden.
| Parameter | Beschreibung |
| DataToEncode | Die als Code 128 zu kodierende Zeichenfolge. Es sind alle ASCII-Zeichen (0-127) erlaubt. Start-, Prüf- und Stoppzeichen sind nicht anzugeben. |
| ReturnType | Ein numerische Wert, der angibt, welche Daten die Funktion zurückliefern soll:
0 Die notwendige Zeichenfolge für die Schriftart „IDAutomationC128“ inkl. aller Steuerzeichen (z. B. Start-, Prüf- und Stoppzeichen). 1 Die Daten in Klarschrift, d.h. in ASCII und ohne Start-, Stopp- und andere Code 128 spezifischen Steuerzeichen. 2 Nur die Prüfziffer |
Beispiele

7.4.3.2 IDAutomationFontEncoderCode128a
Diese Funktion akzeptiert nur Zeichen aus dem Zeichensatz „B“ (ASCII 32 -127), gibt sie aber so aus, dass ein Scanner sie als Zeichen aus dem Zeichensatz „A“ (ASCII 0-95) erkennt. Dies kann in den Fällen nützlich sein, wenn Steuerzeichen aus dem Zeichensatz „A“ benötigt werden, aber nicht eingeben bzw. übergegeben werden können. Wenn also beispielsweise ASCII 0 (NUL) benötigt wird, ist dieser Funktion stattdessen das Zeichen „`“ (ASCII 96) zu übergeben.
| Parameter | Beschreibung |
| DataToEncode | Die als Code 128 (Zeichensatz „A“) zu kodierende Zeichenfolge. Es sind nur Zeichen aus dem Zeichensatz „B“ (ASCII 32 -127) erlaubt. Start-, Prüf- und Stoppzeichen sind nicht anzugeben. |
Beispiele

7.4.3.3 IDAutomationFontEncoderCode128b
Diese Funktion akzeptiert nur Zeichen aus dem Zeichensatz „B“ (ASCII 32 -127) und gibt sie auch so aus, d.h. ein Scanner erkennt genau diese Zeichenfolge.
| Parameter | Beschreibung |
| DataToEncode | Die als Code 128 (Zeichensatz „B“) zu kodierende Zeichenfolge. Es sind nur Zeichen aus dem Zeichensatz „B“ (ASCII 32 -127) erlaubt. Start-, Prüf- und Stoppzeichen sind nicht anzugeben. |
Beispiele

7.4.3.4 IDAutomationFontEncoderCode128c
Mit Hilfe dieser Funktion können rein numerische Zeichenfolgen sehr effizient kodiert werden. Bei dem Zeichensatz „C“ werden immer zwei Ziffern auf einen Code abgebildet. Diese Funktion akzeptiert daher nur Ziffern (0-9) und außerdem muss die Anzahl der Ziffern immer gerade sein.
| Parameter | Beschreibung |
| DataToEncode | Die als Code 128 zu kodierende Ziffernfolge. Die Anzahl der Ziffern muss gerade sein. Start-, Prüf- und Stoppzeichen sind nicht anzugeben. |
| ReturnType | Ein numerischer Wert, der angibt, welche Daten die Funktion zurückliefern soll:
0 Die notwendige Zeichenfolge für die Schriftart „IDAutomationC128“ oder „IDAutomationHcC128“ inkl. aller Steuerzeichen (z.B. Start-, Prüf- und Stoppzeichen). 1 Die Daten in Klarschrift, d.h. in ASCII und ohne Start-, Stopp- und andere Code 128 spezifischen Steuerzeichen. 2 Nur die Prüfziffer |
Beispiele

7.5 EAN-8
EAN-8 ist eine Variante von EAN-13 und wird benutzt, wenn auf Verpackungen nicht genügend Platz für den EAN-13 vorhanden ist. Die Platzersparnis wird dadurch erzielt, dass der Herstellercode weggelassen wird. Dies hat zur Folge, dass der Produktcode nicht mehr durch den jeweiligen Hersteller vergeben werden kann, sondern bei der (nationalen) EAN-Organisisation beantragt werden muss. Durch die Einsparung an Stellen ergibt sich ein kürzerer Strichcode und daraus wiederum auch eine geringere Strichhöhe.
7.5.1 Eigenschaften
Die allgemeinen Eigenschaften von EAN‑8 sind identisch zu denen von EAN‑13 und werden deshalb hier nicht wiederholt.
7.5.2 Schriftarten
EAN-8 wird, wie EAN-13, mit der Schriftart IDAutomationUPCEAN* erzeugt. Allgemeine Informationen zu dieser Schriftart und ihren Varianten sowie Hinweise für den Druck ist in dem entsprechenden Abschnitt zu EAN-13 zu finden.
Der EAN-8 Standard definiert, analog zu EAN-13, eine „Nominalgröße“: Bei dieser Nominalgröße beträgt die Modulbreite („X“) 0,330 mm (wie bei EAN-13). Die Breite × Höhe des gesamten Symbols (inkl. Hellzonen (Ruhezonen) und Klarschrifttext) beträgt 26,73 mm × 21,31 mm. Diese Nominalgröße sollte nach Möglichkeit eingehalten werden. Es sind jedoch Vergrößerungsfaktoren von 0,8 bis 2,0 erlaubt, um die Druckqualität für ein gegebenes Ausgabegerät optimieren zu können.
Um ein EAN-8 Symbol in der Nominalgröße auszugeben, ist die „M“ Variante der Schriftart (IDAutomationUPCEANM) in der Größe 20 Punkt zu verwenden. Die oben genannten Vergrößerungsfaktoren von 0,8 bis 2,0 erlauben Schriftgrößen von 18 bis 36 Punkt. Die anderen Schriftvarianten (XSnoHR, XS, S, L) entsprechen nicht den Empfehlungen für EAN-8. Für spezielle Anwendungsfälle mögen diese Schriftarten aber trotzdem nützlich sein. Die nachfolgende Tabelle zeigt die ungefähren Größenverhältnisse bei 20 Punkt:
| XSnoHR | XS | S | M | L | |
| Modulbreite (X) | 0,330 mm | ||||
| Gesamtbreite | 26,73 mm | ||||
| Gesamthöhe | 8,0 mm | 10,4 mm | 16,5 mm | 21,2 mm | 25,9 mm |
| Strichhöhe | 8,0 mm | 6,2 mm | 12,8 mm | 17,8 mm | 22,8 mm |
In der nachfolgenden Tabelle werden Beispiele für die Schriftvarianten bei 20 Punkt gezeigt.

7.5.3 Funktionen für Crystal Reports
Um die Schriftarten IDAutomationUPCEAN* nutzen zu können, müssen die Daten entsprechend aufbereitet werden. Für den EAN-8-Standard ist die Funktion „IDAutomationFontEncoderEAN8“ zu nutzen.
IDAutomationFontEncoderEAN8
Diese Funktion berechnet die für die Schriftart IDAutomationUPCEAN* notwendige Zeichenfolgen.
| Parameter | Beschreibung |
| DataToEncode | Die als EAN-8 zu kodierende Ziffernfolge. Es sind die Ziffern 0 bis 9 erlaubt. Zusätzlich zu den 7 Stellen für die Daten kann auch die Prüfziffer angegeben werden (siehe nachfolgende Beispiele). Hierbei wird die Prüfziffer aber nicht verwendet, sondern stets aus den Daten berechnet. Die übergebene Zeichenfolge darf zudem das Zeichen „-“ enthalten, beispielsweise um die Lesbarkeit zu fördern. Diese Zeichen werden automatisch ausgefiltert und zählen nicht zu den Daten (Stellen). Bei unzulässigen Daten wird ein EAN-8 Code erzeugt, der nur aus Nullen besteht. |
Beispiele

7.6 EAN-13
Der EAN-13-tandard wurde von der International Article Numbering Association (EAN) entwickelt. Er basiert auf dem UPC-A Standard (siehe „UPC-A“) und ist, im Gegensatz zu diesem, für die internationale Verwendung entworfen worden.
7.6.1 Eigenschaften
| Eigenschaft | Ausprägung |
| Spezifikation (Standard) | EN 797 |
| Verwandte Standards | EAN-8, UPC-A, JAN |
| Anwendungsgebiete | Handel (POS) |
| Zeichensatz (-umfang) | Numerischer Code, Ziffern (0 – 9) |
| Länge | Feste Länge 12 Ziffern + Prüfziffer; Optionale Erweiterung um 2 oder 5 Ziffern |
| Aufbau | 11 Elemente. Alle Striche und Lücken tragen Information. |
| Selbstüberprüfbar | ja |
| Vorteil | Hohe Informationsdichte |
| Nachteil | Sehr kleine Toleranzen |
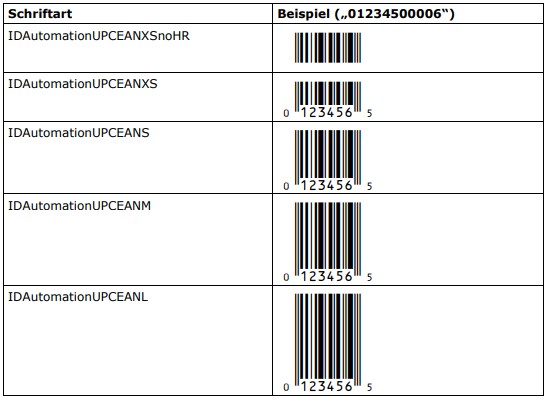
7.6.2 Schriftarten
Die Strichcodes für EAN-13, EAN-8, UPC-A, UPC-E und JAN werden alle mit Schriftart IDAutomationUPCEAN erzeugt. Diese Schriftart wird in insgesamt 5 Varianten angeboten, vier mit Text (XS, S, M, L) und eine ohne Text (XSnoHR).
Der EAN-13 Standard definiert eine „Nominalgröße“: Bei dieser Nominalgröße beträgt die Modulbreite („X“) 0,330 mm. Die Breite mal Höhe des gesamten Symbols (inkl. Hellzonen (Ruhezonen) und Klarschrifttext) beträgt 37,29 mm mal 25,91 mm. Diese Nominalgröße sollte nach Möglichkeit eingehalten werden. Es sind jedoch Vergrößerungsfaktoren von 0,8 bis 2,0 erlaubt, um die Druckqualität für ein gegebenes Ausgabegerät optimieren zu können.
Um ein EAN-13 Symbol in der Nominalgröße auszugeben, ist die „L“ Variante der Schriftart (IDAutomationUPCEANL) in der Größe 20 Punkt zu verwenden. Die oben genannten Vergrößerungsfaktoren von 0,8 bis 2,0 erlauben Schriftgrößen von 18 bis 36 Punkt. Bei der Wahl der konkreten Schriftgröße muss jedoch die jeweilige Druckerauflösung beachtet werden, hieraus ergeben sich sowohl Mindestgrößen als auch Stufenwerte für die Schrift. So empfiehlt IDAutomation, Inc. beispielsweise bei Auflösungen von 300 dpi bzw. 203 dpi nur die Schriftgrößen 20 pt bzw. 25 pt oder Werte größer 30 pt zu verwenden.
Die anderen Schriftvarianten (XSnoHR, XS, S, M) entsprechen nicht den Empfehlungen für EAN-13. Außerdem kann bei zu geringer Höhe die Möglichkeit verlorengehen, das Symbol lageunabhängig erfassen zu können. Für spezielle Anwendungsfälle mögen diese Schriftarten aber trotzdem nützlich sein. Die nachfolgende Tabelle zeigt die ungefähren Größenverhältnisse bei 20 Punkt:
| XSnoHR | XS | S | M | L | |
| Modulbreite (X) | 0,330 mm | ||||
| Gesamtbreite | 37,3 mm | ||||
| Gesamthöhe | 8,0 mm | 10,4 mm | 16,5 mm | 21,2 mm | 25,9 mm |
| Strichhöhe | 8,0 mm | 6,2 mm | 12,8 mm | 17,8 mm | 22,8 mm |
In der nachfolgenden Tabelle werden Beispiele für die Schriftvarianten bei 20 Punkt gezeigt.
| Schriftart | Beispiel („401234567890“) |
| IDAutomationUPCEANXSnoHR | |
| IDAutomationUPCEANXS | |
| IDAutomationUPCEANS |  |
| IDAutomationUPCEANM |  |
| IDAutomationUPCEANL |  |
7.6.3 Funktionen für Crystal Reports
Um die Schriftarten IDAutomationUPCEAN* nutzen zu können müssen die Daten entsprechend aufbereitet werden. Für den EAN-13-Standard ist die Funktion „IDAutomationFontEncoderEAN13“ zu nutzen.
IDAutomationFontEncoderEAN13
Diese Funktion berechnet die für die Schriftart IDAutomationUPCEAN* notwendige Zeichenfolgen.
| Parameter | Beschreibung |
| DataToEncode | Die als EAN-13 zu kodierende Ziffernfolge. Es sind die Ziffern (0-9) erlaubt. Zusätzlich zu den 12 Stellen für die Daten kann auch die Prüfziffer und/oder ein zwei- bzw. fünfstelliger Zusatzcode (Add-On) angegeben werden (siehe nachfolgende Beispiele). Wobei die Prüfziffer aber nicht verwendet, sondern stets aus den Daten berechnet wird. Die übergebene Zeichenfolge darf zudem die Zeichen „-“ und „+“ enthalten, beispielsweise um die Lesbarkeit zufördern. Diese Zeichen werden automatisch ausgefiltert und zählen nicht zu den Daten (Stellen). Bei unzulässigen Daten wird ein EAN-13 Code erzeugt, der nur aus Nullen besteht. |
Beispiele
| DataToEncode | Ergebnis | IDAutomationUPCEANL (20 pt) |
| 401234567890, 4012345678901, 4012345678902, 40-12345-67890 |
Y(0B23EF*QRSTKL( |  |
| 40123456789012, 401234567890112, 40-12345-67890+12, 40-12345-67890-1+12 |
Y(0B23EF*QRSTKL( +#!$ |  |
| 40123456789012345, 401234567890112345, 40-12345-67890+12345, 40-12345-67890-1+12345 |
Y(0B23EF*QRSTKL( +=!$!@!&!, |  |
| ABC, 1234, 4012345678901234 |
U(000000*KKKKKK( |  |
7.7 EAN/UCC 128
Der EAN/UCC 128 Standard definiert keine eigene Symbologie, sondern ein spezielles Datenformat. Dieses Datenformat erlaubt, in einem Strichcode mehrere Informationen gleichzeitig zu kodieren. Die Bedeutung der einzelnen Informationen wird durch so genannte „Application Identifier“ (AI) festgelegt, die jeweils als Präfix den eigentlichen Daten voranzustellen sind.
7.7.1 Eigenschaften
Technisch gesehen basiert der EAN‑128 Code auf der Symbologie von Code 128. Es wird lediglich direkt hinter dem Startzeichen ein weiteres Steuerzeichen (FCN 1) eingefügt.
Der EAN‑128 Standard definiert eine minimale Modulbreite von 0,250 mm (0,00984″) und eine maximale Modulbreite von 1,016 mm (0,040″). Zusätzlich können je nach Anwendung spezifische (engere) Grenzen für die Modulbreite festgelegt sein. Für die Strichhöhe ist 32 mm (1,25″) als Minimum festgelegt.
Application Identifier
Ein „Application Identifier“ (AI) definiert nicht nur die Bedeutung der nachfolgenden Daten, sondern gleichzeitig auch deren Länge und ihr Format. Für einige AIs ist eine feste Länge definiert, für andere AIs ist die Länge variabel (bis 30 Zeichen)[8]. Je nach AI, können die Daten numerisch oder alphanumerisch sein. Auch das Datumsformat oder die Anzahl der Nachkommastellen werden durch die AIs definiert. Die nachfolgende Tabelle zeigt (auszugsweise) einige AIs:
| AI | Dateninhalt | Format |
| 00 | Serial Shipping Container Code (SSCC) Nummer der Versandeinheit (NVE) |
18 Ziffern |
| 01 | Shipping Container Code (SCC) EAN der Handelseinheit |
14 Ziffern |
| 02 | EAN Nummer der in der Transporteinheit enthaltenen Waren | 14 Ziffern |
| 10 | Losnummer/Chargennummer | 1 – 20 Zeichen |
| 11 | Herstellungsdatum | 6 Ziffern (YYMMDD) |
| 12 | Fälligkeitsdatum | 6 Ziffern (YYMMDD) |
| 13 | Packdatum | 6 Ziffern (YYMMDD) |
| 15 | Mindesthaltbarkeitsdatum (Qualität) | 6 Ziffern (YYMMDD) |
| 17 | Verfallsdatum (Sicherheit) | 6 Ziffern (YYMMDD) |
| 20 | Produktvariante | 2 Ziffern |
| 21 | Seriennummer | 1 – 20 Zeichen |
| 22 | HIBCC Quantity, Date, Batch and Link | 1 – 29 Zeichen |
| 23x[9] | Chargennummer (Übergangslösung) | 1 – 19 Zeichen |
| 240 | zusätzliche Produktidentifkation des Herstellers | 1 – 30 Zeichen |
| 241 | Kundenteilenummer | 1 – 30 Zeichen |
| 250 | Seriennummer eines integrierten Bauteils | 1 – 30 Zeichen |
| 251 | Bezug auf die Grundeinheit | 1 – 30 Zeichen |
| 30 | Menge in Stück (mengenvariable Handelseinheit) | 1 – 8 Ziffern |
| 310y[10] | Nettogewicht in Kilogramm | 6 Ziffern |
| 311y | (Produkt) Länge/Dimension 1 in Meter | 6 Ziffern |
| 312y | (Produkt) Breite/Dimension 2 in Meter | 6 Ziffern |
| 313y | (Produkt) Höhe/Dimension 3 in Meter | 6 Ziffern |
| 314y | (Produkt) Fläche in Quadratmeter | 6 Ziffern |
| 315y | (Netto-)Volumen in Liter | 6 Ziffern |
| 316y | (Netto-)Volumen in Kubikmeter | 6 Ziffern |
| 330y | (Brutto-)Gewicht in Kilogramm | 6 Ziffern |
| 331y | (Container) Länge/Dimension 1 in Meter | 6 Ziffern |
| 332y | (Container) Breite/Dimension 2 in Meter | 6 Ziffern |
| 333y | (Container) Höhe/Dimension 3 in Meter | 6 Ziffern |
| 334y | (Container) Fläche in Quadratmeter | 6 Ziffern |
| 335y | (Brutto-)Volumen in Liter | 6 Ziffern |
| 336y | (Brutto-)Volumen in Kubikmeter | 6 Ziffern |
| 37 | Anzahl in der Transporteinheit enthaltenen Handelseinheiten | 1 – 8 Ziffern |
| 400 | Bestell- / Auftragsnummer des Kunden | 1 – 29 Zeichen |
| 410 | „Lieferung an“, Bundeseinheitliche Betriebsnummer | 13 Ziffern |
| 411 | „Rechnung an“, Bundeseinheitliche Betriebsnummer | 13 Ziffern |
| 412 | „Lieferung von“, bundeseinheitliche Betriebsnummer | 13 Ziffern |
| 420 | „Lieferung nach“, Postleitzahl (bei Versendung im Inland) | 1 – 9 Zeichen |
| 421 | „Lieferung nach“, 3-stelliger ISO-Ländercode + Postleitzahl | 4 – 12 Zeichen |
| 8001 | Rollenprodukte: Breite, Länge, Kerndurchmesser… | 14 Ziffern |
| 8002 | Electronic Serial Number (ESN) for Cellular Phone | 1 – 20 Zeichen |
| 8003 | EAN/UCC Identifikation für Mehrwegtransportbehälter und -verpackungen (GRAI) | 14 Ziffern für EAN plus 1 – 16 Zeichen für Seriennummer |
| 8004 | EAN/UCC Identifikation für individuelle / serielle Objekte (GIAI) | 1 – 30 Zeichen |
| 8005 | Abgabepreis pro Maßeinheit | 6 Ziffern |
| 8020 | Zahlscheinbezugsnummer | 1 – 25 Zeichen |
| 90 | Mutually Agreed Between Trading Partners Inforamtion für bilateral abgestimmte Anwendungen |
1 – 30 Zeichen |
| 91 | Internal Company Codes / USPS services Rohmaterial, Verpackung, Komponenten |
1 – 30 Zeichen |
| 92 | Internal Company Codes Rohmaterial, Verpackung, Komponenten |
1 – 30 Zeichen |
| 93 | Internal Company Codes Hersteller |
1 – 30 Zeichen |
| 94 | Internal Company Codes Hersteller |
1 – 30 Zeichen |
| 95 | Internal Company Carrieres Transporteure (Frachtbrief-Nr. etc.) |
1 – 30 Zeichen |
| 96 | Internal Company Carrieres Transporteure |
1 – 30 Zeichen |
| 97 | Internal Company Codes Groß- und Einzelhandel |
1 – 30 Zeichen |
| 98 | Internal Company Codes Groß- und Einzelhandel |
1 – 30 Zeichen |
| 99 | Internal Company Codes Frei vereinbarer Text |
1 – 30 Zeichen |
7.7.2 Schriftarten
Für EAN/UCC-128 wird die Schriftart IDAutomationC128* (Code 128) verwendet.
7.7.3 Funktionen für Crystal Reports
Um die für EAN‑128 erforderlichen Berechnungen (Prüfzeichen) und Zeichensatzumformungen durchzuführen stehen folgende Funktionen (Visual Basic UFLs) zur Verfügung:
- IDAutomationFontEncoderCode128
- IDAutomationFontEncoderCodeUCC128
- IDAutomationFontEncoderCodeSCC14
- IDAutomationFontEncoderCodeSSCC18
- IDAutomationFontEncoderCodeUSPSEAN128 (siehe USPS)
- IDAutomationFontEncoderCodeMod10
7.7.3.1 IDAutomationFontEncoderCode128
Die allgemeinen Eigenschaften dieser Funktion sind im Abschnitt IDAutomationFontEncoderCode128 beschrieben, dieser Abschnitt erläutert die EAN‑128 spezifischen Eigenschaften der Funktion.
Im Gegensatz zu den Funktionen IDAutomationFontEncoderCodeUCC128, IDAutomationFontEncoderCodeSCC14, IDAutomationFontEncoderCodeSSCC18 oder IDAutomationFontEncoderCodeUSPSEAN128 muss hier das für EAN‑128 notwendige Steuerzeichen „FCN1“ explizit angegeben werden. Zusätzliche FCN1 Codes sind ggf. erforderlich wenn AIs mit variabler Länge verwendet werden.
Um einen FCN1-Code in den Strichcode einzufügen muss das Unicodezeichen 0xCA (Ê) in die zu kodierende Zeichenfolge eingefügt werden.
Hinweis:
Je nach AI (z.B. 00 und 01) erfordern einige Daten eine eigene, zusätzliche Prüfziffer (Modulo 10). Falls diese nicht bereits vorliegt, kann sie mit der Funktion IDAutomationFontEncoderCodeMod10 berechnet werden.
| Parameter | Beschreibung |
| DataToEncode | Die als Code 128 zu kodierende Zeichenfolge. Es sind alle ASCII Zeichen (0-127) erlaubt. Start-, Prüf- und Stoppzeichen sind nicht anzugeben. |
| ReturnType | Ein numerische Wert, der angibt, welche Daten die Funktion zurückliefern soll:
0 Die notwendige Zeichenfolge für die Schriftart „IDAutomationC128“ inkl. aller Steuerzeichen (z.B. Start-, Prüf- und Stoppzeichen). 1 Die Daten in Klarschrift, d.h. in ASCII und ohne Start-, Stopp- und andere Code 128 spezifischen Steuerzeichen, aber ggf. mit zusätzlicher Formatierung. 2 Nur die Prüfziffer |
Beispiele
| DataToEncode | RT | Ergebnis |
| Ê0174012345678900 | 0 | ÍÊ!j!7McyÂLÎ |
| IDAutomationC128L (20 pt)
|
||
| 1 | (01) 74012345678900 | |
| 2 | L | |
| Ê00123456789012345675 | 0 | ÍÊÂ,BXnz,BXkJÎ |
| IDAutomationC128L (20 pt)
|
||
| 1 | (00) 123456789012345675 | |
| 2 | J | |
| Ê0114012345678908 Ê15041231Ê101234 |
0 | ÍÊ!.!7Mcy(Ê/$,?Ê*,BJÎ |
IDAutomationC128L (20 pt) |
||
| 1 | (01) 14012345678908 (15) 041231 (10) 1234 | |
| 2 | J |


7.7.3.2 IDAutomationFontEncoderUCC128
Diese Funktion kann benutzt werden, wenn die erste Prüfziffer (Modulo 10) bereits berechnet wurde (bzw. keine solche Prüfziffer berechnet werden soll). Die Funktion konvertiert die übergebene Zeichenfolge, sodass sie mit der Schriftart IDAutomationC128* ausgegeben werden kann. Dabei werden Startzeichen, (erstes) FCN1-Zeichen, (zweite) Prüfziffer (Modulo 103) und das Stoppzeichen automatisch zugefügt. Wenn weitere FCN1 erforderlich sind, kann man diese durch die Verwendung des Unicodezeichens 0xFA (ú) einfügen (nur an geraden Zeichenpositionen möglich).
| Parameter | Beschreibung |
| DataToEncode | Die als Code 128 (EAN-128) zu kodierende Zeichenfolge. |
Beispiele

7.7.3.3 IDAutomationFontEncoderSCC14
Diese Funktion bereitet die als „Shipping Container Code“ (SCC) übergebene Zeichenkette so auf, dass sie mit der Schrift IDAutomationC128* ausgegeben werden kann. Dabei werden Startcode, FCN1, Application Identifier (01), 1. Prüfziffer (Modulo 10), 2. Prüfziffer (Modulo 103) und Stoppcode automatisch berechnet und eingefügt.
| Parameter | Beschreibung |
| DataToEncode | Eine 13 bis 17-stellige Zahl (nur 13 Ziffern werden tatsächlich benutzt, der Application Identifier (01) und die Prüfziffer werden in jedem Fall neu berechnet). Die Zahl setzt sich dabei aus folgenden Komponenten zusammen:
· 1-stelliger „Packaging Indicator“ · 12-stellige EAN-13 Nummer (ohne Prüfziffer) · Prüfziffer (Modulo 10) Klammer (für AI) und Leerzeichen werden automatisch ausgefiltert. Bei ungültigen Daten wird ein Strichcode erzeugt, der nur Nullen enthält. |
| ReturnType(RT) | Ein numerischer Wert, der angibt, welche Daten die Funktion zurückliefern soll:
0 Die notwendige Zeichenfolge für die Schriftarten „IDAutomationC128*“ inkl. aller Steuerzeichen (z.B. Start-, Prüf- und Stoppzeichen). 1 Die Daten in Klarschrift inkl. Prüfziffer, aber ohne Start-, und Stoppzeichen. 2 Nur die Prüfziffer |
Beispiele

7.7.3.4 IDAutomationFontEncoderSSCC18
Diese Funktion bereitet die als „Serial Shipping Container Code“ (SSCC)[11] übergebene Zeichenkette so auf, dass sie mit der Schrift IDAutomationC128* ausgegeben werden kann. Dabei werden Startcode, FCN1, Application Identifier (00), 1. Prüfziffer (Modulo 10), 2. Prüfziffer (Modulo 103) und Stoppcode automatisch berechnet und eingefügt.
| Parameter | Beschreibung |
| DataToEncode | Eine 17 bis 21-stellige Zahl (nur 17 Ziffern werden tatsächlich benutzt, der Application Identifier und die Prüfziffer werden in jedem Fall neu berechnet). Die Zahl setzt sich dabei aus folgenden Komponenten zusammen:
· 1-stellige „Erweiterungsziffer“ · 7 bis 9-stellige „Basisnummer“ · 8 bis 10-stellige, individuelle (fortlaufende) Bezeichnung der logistischen Einheit · Prüfziffer (Modulo 10) Klammer (für AI) und Leerzeichen werden automatisch ausgefiltert. Bei ungültigen Daten wird ein Strichcode erzeugt, der nur Nullen enthält. |
| ReturnType(RT) | Ein numerischer Wert, der angibt, welche Daten die Funktion zurückliefern soll:
0 Die notwendige Zeichenfolge für die Schriftarten „IDAutomationC128*“ inkl. aller Steuerzeichen (z.B. Start-, Prüf- und Stoppzeichen). 1 Die Daten in Klarschrift inkl. Prüfziffer, aber ohne Start-, und Stoppzeichen. 2 Nur die Prüfziffer |
Beispiele

7.7.3.5 IDAutomationFontEncoderMod10
Einige EAN‑128 Anwendungen, beispielsweise „Serial Shipping Container Code“ (AI=00) oder „Shipping Container Code“ (AI=01), verwenden eine zusätzliche (zweite) Prüfziffer (Modulo 10) für die Nutzdaten. Diese Funktion kann dazu verwendet werden diese Prüfziffer zu berechnen.
| Parameter | Beschreibung |
| DataToEncode | Eine Zeichenkette aus Ziffern (0 – 9), für die eine Prüfziffer (Modulo 10) berechnet werden soll. |
Beispiel
Der Wert „34012345000000001“ sei als SSCC-18 auszugeben. Mit IDAutomationFontEncoderMod10(“34012345000000001”) kann zunächst die Prüfziffer berechnet werden. In diesem Fall ist das Ergebnis „7“. Der Application Identifier für SSCC ist „00“. Die drei Teile können nun einfach aneinandergehängt werden: “00” + “34012345000000001” + “7”. Das Ergebnis kann dann beispielsweise der Funktion IDAutomationFontEncoderUCC128 übergeben werden, um die notwendige Zeichenkette für die Schriftart IDAutomationC128L zu bekommen. Alternativ kann auch die Funktion IDAutomationFontEncoderCode128() verwendet werden, allerdings muss dann zusätzlich noch das Unicodezeichen 0xCA (Ê) vorangestellt werden, damit die Funktion den für EAN-128 notwendigen FCN1-Code einfügt.
Hinweis:
Für den genannten Anwendungsfall steht mit IDAutomationFontEncodeSSCC18 eine spezielle Funktion bereit, die dies vereinfacht. Das Beispiel hier soll nur verdeutlichen, wie für ähnliche Anwendungsfälle eine solche Funktion selbst erstellt werden kann.
7.8 MSI/Plessey
7.8.1 Eigenschaften
| Eigenschaft | Ausprägung |
| Anwendungsgebiete | Industrie, Büchereien |
| Zeichensatz (-umfang) | Numerischer Code (Ziffern 0 – 9) |
| Länge | variabel (keine fest vorgegebene Länge) |
| Prüfziffer | Modulo 10 |
| Aufbau | Jeweils 4 Striche und 4 Lücken |
| Selbstprüfbar | Nein |
| Vorteil | |
| Nachteil | Geringe Informationsdichte |
7.8.2 Schriftarten
Für MSI (Plessey) werden Schriftarten in zwei Varianten angeboten:
- Ohne Text (MSI*)
- Mit Text (HMSI*)
Zu jeder Variante existieren wiederum 4 Subvarianten, die sich jeweils in ihrer Strichhöhe unterscheiden:
- XS (25%)
- S (50%)
- M (100%)
- L (125%)
Die empfohlene Schriftgröße für alle Varianten und Subvarianten ist 12 Punkt. Bei dieser Schriftgröße ergibt sich für alle Varianten und Subvarianten eine Modulbreite von ca. 0,21 mm bzw. 8 mil (1 mil = 1/1000″). Die jeweilige Strichhöhe hängt von der Subvariante und der Schriftgröße ab. Die Strichhöhe der „M“-Varianten beträgt beispielsweise ca. 25,4 mm bzw. 1″. Die nachfolgenden Tabellen zeigen die Schriftarten jeweils bei 12 Punkt.
| MSI ohne Text | |
| Schriftart | Beispiel („1234567890“) |
| IDAutomationMSIXS | |
| IDAutomationMSIS |  |
| IDAutomationMSIM |  |
| IDAutomationMSIL |  |
| MSI mit Text | |
| Schriftart | Beispiel („1234567890“) |
| IDAutomationHMSIXS | |
| IDAutomationHMSIS |  |
| IDAutomationHMSIM |  |
| IDAutomationHMSIL |  |
7.8.3 Funktionen für Crystal Reports
Für MSI (Plessey) steht folgende Funktion (Visual Basic UFLs) zur Verfügung:
IDAutomationFontEncoderMSI
IDAutomationFontEncoderMSI
Diese Funktion fügt der übergebenen Zeichenkette am Anfang ein „(“ (Startzeichen) und am Ende ein „)“ (Stoppzeichen) hinzu. Weiterhin wird von dieser Funktion die Prüfziffer berechnet und vor dem Stoppzeichen eingefügt.
| Parameter | Beschreibung |
| DataToEncode | Die als MSI (Plessey) zu kodierende Ziffernfolge. Es sind nur Ziffern (0 bis 9) erlaubt, die Anzahl ist nicht beschränkt. Start-, Prüf- und Stoppzeichen sind nicht anzugeben. |
| ReturnType | Ein numerische Wert, der angibt, welche Daten die Funktion zurückliefern soll:
0 Die notwendige Zeichenfolge für die Schriftarten „IDAutomationMSI*“ bzw. „IDAutomationHMSI*“ inkl. aller Steuerzeichen (z.B. Start-, Prüf- und Stoppzeichen). 1 Die Daten in Klarschrift inkl. Prüfziffer[12], aber ohne Start-, und Stoppzeichen. 2 Nur die Prüfziffer |
Beispiele

7.9 UPC-A
7.9.1 Eigenschaften
| Eigenschaft | Ausprägung |
| Spezifikation (Standard) | EN 797 |
| Verwandte Standards | EAN-13, UPC-E |
| Anwendungsgebiete | Handel in den USA und Kanada (POS) |
| Zeichensatz (-umfang) | Numerischer Code Ziffern (0 – 9) |
| Länge | Feste Länge 11 Ziffern plus Prüfziffer; Optionale Erweiterung um 2 oder 5 Ziffern |
| Aufbau | 11 Elemente. Alle Striche und Lücken tragen Information. |
| Selbstüberprüfbar | ja |
| Vorteil | Hohe Informationsdichte |
| Nachteil | Sehr kleine Toleranzen |
7.9.2 Schriftarten
UPC-A wird, wie EAN-13, mit der Schriftart IDAutomationUPCEAN* erzeugt. Allgemeine Informationen zu dieser Schriftart und ihren Varianten sowie Hinweise für den Druck sind im entsprechenden Abschnitt zu EAN-13 zu finden.
In der nachfolgenden Tabelle werden Beispiele für die Schriftvarianten bei 20 Punkt gezeigt.
| Schriftart | Beispiel („01234567890“) |
| IDAutomationUPCEANXSnoHR | |
| IDAutomationUPCEANXS | |
| IDAutomationUPCEANS |  |
| IDAutomationUPCEANM |  |
| IDAutomationUPCEANL |  |
7.9.3 Funktionen für Crystal Reports
Um die Schriftarten IDAutomationUPCEAN* nutzen zu können müssen die Daten entsprechend aufbereitet werden. Für den UPC-A Standard ist die Funktion „IDAutomationFontEncoderUPCa“ zu nutzen.
IDAutomationFontEncoderUPCa
Diese Funktion berechnet die für die Schriftart IDAutomationUPCEAN* notwendige Zeichenfolgen.
| Parameter | Beschreibung |
| DataToEncode | Die als UPC-A zu kodierende Ziffernfolge. Es sind die Ziffern 0 bis 9 erlaubt. Zusätzlich zu den 11 Stellen für die Daten, kann auch die Prüfziffer und/oder ein zwei- bzw. fünfstelliger Zusatzcode (Add-On) angegeben werden (siehe nachfolgende Beispiele). Wobei die Prüfziffer aber nicht verwendet, sondern stets aus den Daten errechnet wird. Die übergebene Zeichenfolge darf zudem die Zeichen „-“ und „+“ enthalten, beispielsweise um die Lesbarkeit zu fördern. Diese Zeichen werden automatisch ausgefiltert und zählen nicht zu den Daten (Stellen). Bei unzulässigen Daten wird ein UPC-A Code erzeugt, der nur aus Nullen besteht. |
Beispiele
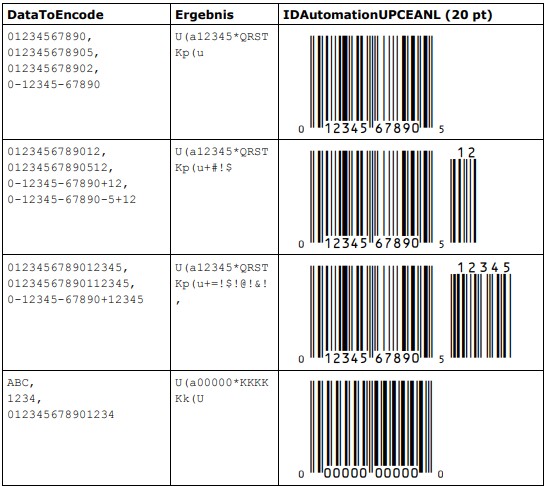
7.10 UPC-E
UPC-E ist die Kurzform von UPC-A. Sie wird verwendet, wenn auf den Verpackungen zu wenig Platz für den vollständigen UPC-A Code ist. Anders als bei EAN-8 ist der Hersteller in dem Code enthalten. Die Verkürzung kommt durch Kompression (Weglassen von Nullen) zustande.
7.10.1 Eigenschaften
Die allgemeinen Eigenschaften von UPC‑E sind identisch zu denen von „UPC-A“ und werden deshalb hier nicht wiederholt.
7.10.2 Schriftarten
UPC-E wird wie EAN-13 und UPC-A mit der Schriftart IDAutomationUPCEAN* erzeugt. Allgemeine Informationen zu dieser Schriftart und ihren Varianten, sowie Hinweise für den Druck sind im entsprechenden Abschnitt zu EAN-13 zu finden.
In der nachfolgenden Tabelle werden Beispiele für die Schriftvarianten bei 20 Punkt gezeigt.
7.10.3 Funktionen für Crystal Reports
Um die Schriftarten IDAutomationUPCEAN* nutzen zu können müssen die Daten entsprechend aufbereitet werden. Für den UPC-E Standard ist die Funktion „IDAutomationFontEncoderUPCe“ zu nutzen.
IDAutomationFontEncoderUPCe
Diese Funktion berechnet die für die Schriftart IDAutomationUPCEAN* notwendigen Zeichenfolgen. Abhängig davon, ob sich die Daten komprimieren lassen, wird eine Zeichenfolge für UPC-E oder UPC-A zurückgegeben.
| Parameter | Beschreibung |
| DataToEncode | Die als UPC-E oder UPC-A zu kodierende Ziffernfolge. Es sind die Ziffern 0 bis 9 erlaubt. Zusätzlich zu den 11 (!) Stellen für die Daten kann auch die Prüfziffer und/oder ein zwei- bzw. fünfstelliger Zusatzcode (Add-On) angegeben werden (siehe nachfolgende Beispiele). Wobei die Prüfziffer aber nicht verwendet, sondern stets aus den Daten errechnet wird. Die übergebene Zeichenfolge darf zudem die Zeichen „-“ und „+“ enthalten, beispielsweise um die Lesbarkeit zufördern. Diese Zeichen werden automatisch ausgefiltert und zählen nicht zu den Daten (Stellen). Abhängig davon, ob sich die Nummer gemäß UPC-E „komprimieren“ lässt oder nicht, wird eine Zeichenkette für UPC-E oder UPC-A erzeugt. Bei unzulässigen Daten wird ein UPC-A Code erzeugt, der den Wert „00005000000“ hat. |
Beispiele
| DataToEncode | Ergebnis | IDAutomationUPCEANL (20 pt) |
| 01234500006, 0-12345-00006 |
U(B23EF6)u |  |
| 01234500004, 0-12345-00004 |
U(a12345*KKKKOl(V |  |
| 01234000004, 0-12340-00004 |
U(B234EE)v |  |
| 0123000001234, 01230000012534, 0-12300-00012+34, 0-12300-00012-5+34 |
U(BC312D)X+@!& |  |
| 0120000012345678, 01200000123945678, 0-12000-00123+45678 |
U(B21C3A)y+[!,!.!_!: |  |
| ABC, 1234, 012345678901234 |
U(A00FA4)u |  |
7.11 OCR-A/OCR-B
Mit der OCR (Optical Character Recognition) Technologie können Zeichen und Texte direkt, also ohne spezielle Kodierung, gelesen werden. Um den dafür notwendigen Aufwand möglichst gering zu halten und gleichzeitig eine möglichst hohe Zuverlässigkeit bei der Erkennung sicherzustellen wurden spezielle OCR-Schriften entwickelt. Idealerweise können diese Schriften sowohl vom Menschen als auch maschinell gelesen werden.
Hauptanwendungsgebiet dieser OCR-Schriften sind Belege im Zahlungsverkehr (Schecks, Überweisungsträger, etc). Es werden dabei überwiegend zwei Schriften verwendet:
- OCR‑A (DIN 66008, ANSI X-3.17-1981)
- OCR‑B (DIN 66009, ANSI X-3.49-1982)
Wobei sich OCR‑B durch eine bessere Lesbarkeit durch den Menschen auszeichnet. Welche von beiden Schriften verwendet wird, hängt in der Regel von dem Anwendungsgebiet bzw. den landesspezifischen Standards ab.
Schriftarten
Für OCR‑A werden folgende Schriftarten (Varianten) angeboten:
| Schriftart | Verwendung |
| IDAutomationA1euro | Spezielle Variante mit Symbolen für den Scheckdruck. Für „Size I“ ist 9 Punkt als Schriftgröße zu verwenden. |
| IDAutomationOCRa | Standardschrift für OCR‑A. Für „Size I“ ist 9pt und für „Size II“ ist 12 Punkt als Schriftgröße zu verwenden. |
Für OCR‑B werden folgende Schriftarten (Varianten) angeboten:
| Schriftart | Verwendung |
| IDAutomationOCRb | Standardschrift für OCR‑B. Für „Size I“ ist 14 Punkt als Schriftgröße zu verwenden. |
| IDAutomationOCRbn | Eine etwas „schmalere“ Variante für Drucker, die sonst „zu breit“ drucken |
Der Zeichenumfang von OCR‑A und OCR‑B besteht aus Klein-, Großbuchstaben, Ziffern und verschiedenen Sonderzeichen.
7.12 MICR
In einigen Ländern wird statt (oder zusätzlich zu) der OCR-Technologie die MICR (Magnetic Ink Character Recognition) Technik verwendet. Bei dieser Technologie lassen sich die Zeichen nicht nur optisch, sondern auch „magnetisch“ lesen. Die dazu notwendigen Lesegeräte sind eng mit den Lesegeräten für Karten mit Magnetstreifen verwandt. Die Symbole wurden so entworfen, dass beim Abtasten mit einem solchen Lesegerät für jedes Symbol ein eindeutiges Signal entsteht. Zum Drucken dieser Symbole wird eine spezielle, leicht magnetische Tinte bzw. Toner benötigt.
Hauptanwendungsgebiet der MICR Schriften sind Bankschecks und Wechsel, man findet sie aber beispielsweise auch auf Kreditkarten.
Es haben sich zwei Standards etabliert:
- E-13B
- CMC-7
Der E-13B Standard wurde in den fünfziger Jahren von der ABA (American Banking Association) und der Stanford Universität entwickelt und 1959 als Standard eingeführt. Im Jahr 1963 wurde E-13B vom American National Standards Institute (ANSI) übernommen. Länder wie beispielsweise Kanada, Japan, Australien, Kolumbien, Venezuela und Großbritannien haben sich diesem Standard angeschossen.
CMC-7 wurde von der französischen Computerfirma „Machines Bull“ entwickelt und ist seit 1964 der offizielle Standard in Frankreich. Auch hier haben sich verschiedene Länder angeschlossen (siehe Tabelle).
Die folgende Tabelle zeigt welche europäischen Länder die MICR-Technik für Bankschecks einsetzen[13].
| Land | E-13B | CMC-7 |
| Belgien | [x] | |
| Dänemark | [x] | |
| Finnland | [x] | |
| Frankreich | [x] | |
| Großbritannien | [x] | |
| Italien | [x] | |
| Niederlande | [x] | |
| Norwegen | [x] | |
| Portugal | [x] | |
| Schottland | [x] | |
| Schweden | [x] | |
| Spanien | [x] |
Hinweis:
Um E-13B oder CMC-7 korrekt zu verwenden, d.h. Bankschecks zu drucken, die von entsprechenden Lesegeräten korrekt und zuverlässig gelesen werden können, sind eine Reihe von (landesspezifischen) Vorgaben zu beachten. Dies betrifft sowohl die notwendigen Daten als auch deren Formatierung und Platzierung.
Dieses Dokument beschränkt sich auf die Beschreibung der zur Verfügung stehenden Schriftarten. Die jeweils gültigen Spezifikationen können in der Regel bei den betroffenen Banken angefordert werden. Überhaupt ist sehr zu empfehlen, in dieser Sache mit einer Bank zusammenzuarbeiten, um beispielsweise entsprechende Leseproben durchführen zu lassen.
7.12.1 E-13B
Der Zeichenumfang von E-13B besteht aus 14 Zeichen, zehn Ziffern (0 bis 9) und vier Sonderzeichen („Transit“, „Amount“, „On-Us“, and „Dash“):

Schriftarten
Für MICR E-13B werden folgende Schriftarten (Varianten) angeboten:
| Schriftart | Verwendung |
| IDAutomationMICR | Standardschrift für E-13B. Die Verwendung dieser Schriftart sollte bei den meisten Laserdruckern zu korrekten (standardkonformen) Ergebnissen führen. |
| IDAutomationMICRb10 | Eine um ca. 10% „fettere“ Variante für Drucker, die ansonsten „zu hell“ drucken |
| IDAutomationMICRL15 | Eine um ca. 15% „leichtere“ Variante für Drucker, die ansonsten „zu dunkel“ drucken |
| IDAutomationMICRN1 | Eine etwas „schmalere“ Variante für Drucker, die ansonsten „zu breit“ drucken |
| MICR | Identisch mit „IDAutomationMICR“. Sie werden für den Fall bereitgestellt, dass Anwendungen diese speziellen Schriftnamen erfordern. |
| E-13B |
Grundsätzlich sollte für E-13B nur die Standardschrift („IDAutomationMICR“) verwendet werden. Bei E-13B sind die Toleranzen sehr eng und deshalb die Größen und Proportionen möglichst genau einzuhalten. Die zusätzlichen Schriftarten sind nur für den Fall gedacht, dass der verwendete Drucker die Größen nicht exakt reproduzieren sollte.
Die folgende Tabelle zeigt die verschiedenen Varianten anhand eines Beispiels[14]:
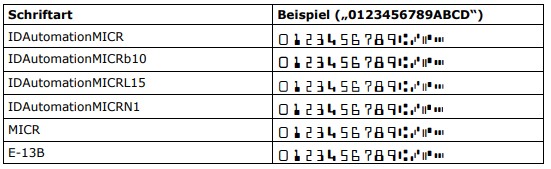
Schriftgröße
Für Bankschecks nach US-Standard ist 12 Punkt als Schriftgröße zu benutzen. In anderen Ländern kann eventuell eine abweichende Größe definiert sein.
Beispiel
![]()
Unicode/Symbol-Umsetzung
Die nachfolgende Tabelle zeigt, wie bei der Schriftart „IDAutomationMICR*“ die Abbildung von Unicode-Zeichen auf E-13B Symbole erfolgt. Mit Hilfe dieser Tabelle kann leicht ermittelt werden, welches Unicode-Zeichen zu verwenden ist, um ein bestimmtes E‑13B Symbol zu erzeugen.
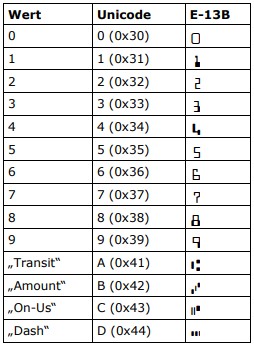
Die Schriftart „IDAutomationMICR*“ enthält weitere „druckbare“ Zeichen. Dies sind aber keine (Standard) E‑13B Symbole und sollten nicht verwendet werden.
7.12.2 CMC-7
Der Zeichenumfang von CMC-7 besteht aus 15 Zeichen, zehn Ziffern (0 bis 9) und fünf Sonderzeichen (S‑1 bis S‑5):

Schriftarten
Für CMC-7 werden folgende Schriftarten (Varianten) angeboten:
| Schriftart | Verwendung |
| IDAutomationCMC7 | Standardschrift für CMC-7. Die Verwendung dieser Schriftart sollte bei den meisten Laserdruckern zu korrekten (standardkonformen) Ergebnissen führen. |
| IDAutomationCMC7n10 | Eine um 10% „schmalere“ Variante für Drucker, die ansonsten „zu dunkel“ drucken |
| IDAutomationCMC7n25 | Eine um 25% „schmalere“ Variante für Drucker, die ansonsten „zu dunkel“ drucken |
| IDAutomationCMC7n40 | Eine um 40% „schmalere“ Variante für Drucker, die ansonsten „zu dunkel“ drucken |
Grundsätzlich sollte für CMC-7 nur die Standardschrift („IDAutomationCMC7“) verwendet werden. Bei CMC-7 sind die Toleranzen sehr eng und deshalb die Größen und Proportionen möglichst genau einzuhalten. Die zusätzlichen Schriftarten sind nur für den Fall gedacht, dass der verwendete Drucker die Größen und/oder Strichstärken nicht exakt reproduzieren sollte.
Die folgende Tabelle zeigt die verschiedenen Varianten anhand eines Beispiels[15]:
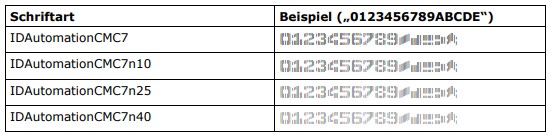
Schriftgröße
Für Bankschecks nach französischem Standard ist 12 Punkt als Schriftgröße zu benutzen. In anderen Ländern kann eventuell eine abweichende Größe definiert sein.
Beispiel
![]()
Unicode/Symbol-Umsetzung
Die nachfolgende Tabelle zeigt, wie bei der Schriftart „IDAutomationCMC7*“ die Abbildung von Unicode-Zeichen auf CMC‑7 Symbole erfolgt. Mit Hilfe dieser Tabelle kann leicht ermittelt werden, welches Unicode-Zeichen zu verwenden ist um ein bestimmtes CMC‑7 Symbol zu erzeugen.
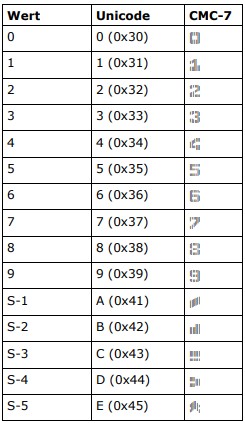
Die Schriftart „IDAutomationCMC7*“ enthält weitere „druckbare“ Zeichen. Dies sind aber keine (Standard) CMC‑7 Symbole und sollten nicht verwendet werden.
7.13 USPS
Der „United States Postal Service“ (USPS) verwendet für die Adressierung, Verteilung und Verfolgung von Briefen etc. eine Reihe verschiedener Strichcodes. Dazu gehören POSTNET, PLANET, Interleaved 2 of 5 und Code 128.
Weitere Informationen über diese Strichcodes und ihre Verwendung sind in folgenden Dokumenten zu finden:
- USPS Publication 25
- USPS Domestic Mail Manual
- USPS specifications
7.13.1 POSTNET
Der POSTNET (POSTal Numeric Encoding Technique) Strichcode wurde von dem „United States Postal Service“ (USPS) entwickelt und dient zur Kodierung von (Post-)Adressen in den USA.
Anders als die meisten anderen Strichcodes werden bei POSTNET und PLANET die Informationen nicht durch unterschiedliche Elementbreiten, sondern durch unterschiedliche Strichhöhen kodiert.
Bei den kodierten Informationen handelt es sich entweder um den Standard ZIP-Code (5 Ziffern), den so genannten ZIP+4 Code (9 Ziffern) oder um den vollständigen „Delivery Point Code“ (11 Ziffern). Der POSTNET-Strichcode enthält grundsätzlich eine Prüfziffer (Modulo 10).
7.13.2 PLANET
Der PLANET Strichcode ist ein neuerer Strichcode und wird von USPS für Antworten (Business-Reply Mails), Sortierung und Nachverfolgung (Tracking) eingesetzt.
7.13.3 FIM
Zur Unterscheidung von „Business-Reply Mails“ und „normaler Post“ werden spezielle Symbole verwendet. Diese Symbole werden in einer speziellen Schriftart (FIM) bereitgestellt.
7.13.4 Schriftarten
Für POSTNET und PLANET werden Schriftarten in jeweils zwei Varianten angeboten: Eine Standardgröße und ein Variante, bei der die Strichbreite um ca. 10% reduziert ist („n“: Narrow).
Die empfohlene Schriftgröße für alle Varianten ist 12 Punkt. Bei dieser Schriftgröße ergeben sich die nach USPS Standard definierten Abmessungen.
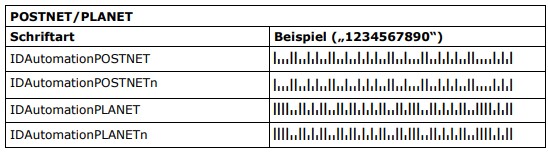
7.13.5 Funktionen für Crystal Reports
Für POSTNET und PLANET steht folgende Funktion (Visual Basic UFL) zur Verfügung:
- IDAutomationFontEncoderPostnet
USPS nutzt seit dem 10.01.2004 auch EAN-128 basierte Strichcodes (z.B. für Zustellbestätigungen). Folgende Funktion kann benutzt werden, um entsprechende Daten für die Schriftart IDAutomationC128L zu erzeugen:
- IDAutomationFontEncoderUSPS_EAN128
7.13.5.1 IDAutomationFontEncoderPostnet
Diese Funktion fügt der übergebenen Zeichenkette am Anfang ein „(“ (Startzeichen) und am Ende ein „)“ (Stoppzeichen) hinzu. Weiterhin wird von dieser Funktion die Prüfziffer berechnet und vor dem Stoppzeichen eingefügt.
| Parameter | Beschreibung |
| DataToEncode | Die als POSTNET oder PLANET zu kodierenden Daten. Es werden die Formate ZIP, ZIP+4 und ZIP+4+„Devivery Point“ unterstützt. Die Daten können „-“ und/oder Leerzeichen enthalten, diese werden automatisch unterdrückt. |
| ReturnType | Ein numerischer Wert, der angibt, welche Daten die Funktion zurückliefern soll:
0 Die notwendige Zeichenfolge für die Schriftarten „IDAutomationPOSTNET*“ bzw. „IDAutomationPLANET*“ inkl. aller Steuerzeichen (z.B. Start-, Prüf- und Stoppzeichen). 1 Die Daten in Klarschrift inkl. Prüfziffer, aber ohne Start-, und Stoppzeichen. 2 Nur die Prüfziffer |
Beispiele

7.13.5.2 IDAutomationFontEncoderUSPS_EAN128
Diese Funktion bereitet die als „USPS Delivery Confirmation“ übergebene Zeichenkette so auf, dass sie mit der Schrift IDAutomationC128* ausgegeben werden kann. Dabei werden Startcode, FCN1, Application Identifier (91), 1. Prüfziffer (Modulo 10), 2. Prüfziffer (Modulo 103) und Stoppcode automatisch berechnet und eingefügt.
| Parameter | Beschreibung |
| DataToEncode | Eine 19 oder 20-stellige Zahl (nur die ersten 19 Ziffern werden benutzt, die Prüfziffer wird immer neu berechnet). Die Zahl setzt sich dabei wie folgt zusammen:
· 2-stelliger „Service Type Code“ · 9-stellige „Customer ID“ (DUNS Number) · 8-stellige „Sequential Pacake ID“ · Prüfziffer (Modulo 10) |
| ReturnType | Ein numerische Wert, der angibt, welche Daten die Funktion zurückliefern soll:
0 Die notwendige Zeichenfolge für die Schriftarten „IDAutomationC128*“ inkl. aller Steuerzeichen (z.B. Start-, Prüf- und Stoppzeichen). 1 Die Daten in Klarschrift inkl. Prüfziffer, aber ohne Start-, und Stoppzeichen. 2 Nur die Prüfziffer |
Beispiele
| DataToEncode | Ergebnis (0, 1, 2) | IDAutomationC128L (20 pt) |
| 0112345678912345678 | ÍÊ{!,BXn{7McpJÎ
9101 1234 5678 9123 4567 80 0 |
 |
8 Druckhinweise
Bei der Frage, ob ein gedruckter Strichcode auch mit einem (oder besser mit jedem) Scanner gelesen werden kann, spielen verschiedene Faktoren mit. So sind die Anforderungen an Drucker und Scanner beispielsweise stark abhängig von der Dichte eines Strichcodes. Die meisten Strichcode-Spezifikationen geben daher Mindestwerte oder Wertebereiche für die Modulbreite sowie das Verhältnis von schmalen zu breiten Elementen vor, damit ein Mindestmaß an Kompatibilität zwischen Ausgabe- und Lesegeräten gewährleistet ist. Die Höhe des Strichcodes ist dabei meist unkritisch, sie sollte jedoch groß genug sein, um den Strichcode auch noch sicher erfassen zu können, wenn der Scanner mal etwas „schief“ gehalten wird.
Bei Druckern ist zu beachten, dass sie nur über ein begrenztes Auflösungsvermögen verfügen, d.h. Linien lassen sich weder beliebig dünn noch beliebig dicht drucken. In der Regel lässt sich nicht einmal die „nominale“ Auflösung (z.B. 600x600dpi bei typischen Laserdruckern) nutzen, da die Größe der „Druckpunkte“ je nach Technologie des Druckers (Laser, Thermo, Tinte, Nadel, …) deutlich von dem Raster abweichen kann. Als Beispiel sei hier nur das „Verlaufen“ der Tinte bei Tintenstrahldruckern genannt.
Ein Scanner kann einen Strichcode nur dann zuverlässig lesen, wenn der Drucker gleichbreite schwarze und weiße Linien auch wirklich (nahezu) gleichbreit druckt. Gleiches gilt für breite und dünne Linien: Doppelt so breite Linien müssen auch auf dem Papier doppelt so breit sein. Aber auch die Scanner selbst stellen je nach Bauart und/oder Leseabstand unterschiedliche Anforderungen an einen (gedruckten) Strichcode. So muss beispielsweise die Modulbreite größer sein, als der zum Abtasten verwendete Lichtstrahl. Ebenfalls sehr wichtig ist der Kontrast zwischen hellen und dunklen Linien[16].
Schriftgröße
Damit ein gedruckter Strichcode zuverlässig gelesen werden kann, müssen die relativen Breiten der Elemente beim Drucken erhalten bleiben. Bei einem Zweibreiten-Code (z.B. Code 39) müssen sich die schmalen Elemente klar als schmale Elemente und die breiten Elemente klar als breite Elemente erkennen lassen. Für eine optimale Lesbarkeit müssen alle schmalen Elemente (Striche und Lücken) die gleiche Breite besitzen, gleiches gilt für die breiten Elemente. Bei Mehrbreiten-Codes (z.B. Code 128) gelten diese Regeln für jede Breite.
Da Drucker nur ein begrenztes Auflösungsvermögen haben, kann die Modulbreite „X“ nicht beliebig klein gewählt werden. Für ein optimales Ergebnis sollte die Modulbreite „X“ so gewählt werden, dass sich für alle vorkommenden Elementbreiten immer ein ganzzahliges Vielfaches der Breite eines Druckerpunktes ergibt. Folgende Tabelle zeigt ein paar Beispiele anhand gängiger Druckerauflösungen:
| 203 dpi | 300 dpi | 600 dpi |
| 0,125 mm (4,92 mil) | 0,085 mm (3,33 mil) | 0,043 mm (1,67 mil) |
| 0,250 mm (9,85 mil) | 0,169 mm (6,67 mil) | 0,085 mm (3,33 mil) |
| 0,375 mm (14,8 mil) | 0,254 mm (10,0 mil) | 0,127 mm (5,00 mil) |
| 0,500 mm (19,7 mil) | 0,339 mm (13,3 mil) | 0,169 mm (6,67 mil) |
| 0,625 mm (24,6 mil) | 0,423 mm (16,7 mil) | 0,212 mm (8,33 mil) |
| 0,750 mm (29,6 mil) | 0,508 mm (20,0 mil) | 0,254 mm (10,0 mil) |
| 0,875 mm (34,5 mil) | 0,593 mm (23,3 mil) | 0,296 mm (11,7 mil) |
| 1,000 mm (39,4 mil) | 0,677 mm (26,7 mil) | 0,339 mm (13,3 mil) |
Wenn von diesen ganzzahligen Werten abgewichen wird, können durch Rundungsfehler verzerrte Verhältnisse bei den Elementbreiten entstehen. Bei genügend großer Modulbreite bzw. entsprechend hoher Druckerauflösung können die entstehenden Fehler jedoch vernachlässigt werden, d.h. sie fallen dann in den vorgesehenen Toleranzbereich des jeweiligen Strichcodes.
Wenn trotz geringer Druckerauflösungen Strichcodes mit kleinen Modulbreiten gedruckt werden sollen, muss die Schriftgröße so gewählt werden, dass sich die Verhältnisse der Elementbreiten innerhalb der spezifizierten Toleranzen des Strichcodes bewegen. Die nachfolgende Tabelle zeigt die von IDAutomation, Inc. empfohlenen Schriftgrößen:
| Schriftart | Empfohlen (bei 600 dpi) | 203 dpi | 300 dpi |
| Code 39 | 12 pt | 4 pt, 8 pt | 2,8 pt, 5,5 pt, ≥ 8 pt |
| Code 128 | 12 pt | 7,4 pt, 14,5 pt | 5 pt, 9,8 pt, 14,5 pt |
| Codabar | 12 pt | 5 pt, 10 pt | 3,6 pt, 6,9 pt, 10 pt |
| EAN/UPC | 20 pt | 5 pt, 10 pt | 3,6 pt, 6,9 pt, 10 pt |
| Interleaved 2 of 5 | 12 pt | 12,5 pt | 8,5 pt |
| MSI | 12 pt | 6 pt, 11,5 pt | 4 pt, 7,8 pt |
9 Glossar
Element
Ein Strichcode besteht aus dunklen und hellen Elementen, den Strichen und den Lücken.
Lücke
Das helle Element zwischen zwei Strichen eines Strichcodes.
Modul
Das schmalste Element in einem Strichcode wird als Modul bezeichnet. Die Breite der anderen Elemente wird als Vielfaches des Moduls ausgedrückt.
Modulbreite X
Die Breite des schmalsten Elements (Modul) wird auch als „X“ bezeichnet.
OCR
Abkürzung für „Optical Character Recognition“. Darunter versteht man maschinenlesbare Zeichen, die auch für Menschen lesbar sind. Es gibt verschiedene OCR-Schriften, die größte Verbreitung besitzen aber OCR-A und OCR-B. OCR-A wurde besonders im Hinblick auf einfache Maschinenlesbarkeit entwickelt und wirkt auf den Menschen sehr künstlich. OCR-B ist auch für Menschen leicht lesbar.
Strich
Das dunkle Element eines Strichcodes.
Symbologie
Definiert die spezifische Symbolstruktur eines Strichcodes.
Ruhezone
Die helle Zone vor und hinter der Strichkodierung. Die Ruhezone (R) ist notwendig, damit sich die Leseeinrichtung (Scanner) auf die Strichkodierung einstellen kann (z.B. Fokussierung). Die Ruhezone sollte mindestens 10X (10fache Modulbreite) bzw. 2,5mm betragen (der größere der beiden Werte ist zu verwenden).
Trennlücke
Die Lücke zwischen dem letzten Strich eines Zeichens und ersten Strich des nächsten Zeichens.
10 Weitere Informationen
Verwenden von Strichcodes in Crystal Reports
Business Objects bietet auf seiner Supportseite das Dokument „Adding Barcodes to Reports“ an. Dieses Dokument beschreibt die grundsätzliche Vorgehensweise, listet Hersteller von entsprechenden Strichcode-Schriftarten auf und bietet Links auf weitere Informationsquellen. Der Zugriff auf die aktuelle Version des Dokuments ist über die Suchfunktion auf der Supportseite (http://support.businessobjects.com/search/) möglich. Als Suchbegriff ist dazu der Name „scr_barcodes.pdf“ zu verwenden.
Funktionen für Crystal Reports (UFL)
IDAutomation, Inc. bietet folgendes „Tutorial“ an: Barcode UFL Plug-ins, Custom Functions and Formulas
EAN, EAN/UCC‑128
Detaillierte Informationen und Spezifikationen sind über die (nationalen) EAN-Organisationen erhältlich. Beispielsweise:
Centrale für Coorganisation (CCG)
EAN (Österreich)
EAN (Schweiz)
FAQs
IDAutomation, Inc. bietet FAQs zu folgenden Themen an:
Allgemeine Hinweise
Code 128 / EAN-128
EAN-13 (EAN-8, UPC-A, UPC-E)
Code 2/5 Interleaved
Code 39
11 Bekannte Probleme
Verwenden von Schriften, die mit „@“ beginnen
Die Strichcode-Schriftarten erscheinen in der Schriftauswahl von Crystal Reports teilweise doppelt. Zum Beispiel einmal als „IDAutomationC128L“ und einmal als „@IDAutomationC128L“. Die Verwendung der Varianten mit „@“-Zeichen kann zu fehlerhaften Strichcodes führen (zusätzliche Striche oder Lücken), es sollten daher grundsätzlich nur die Schriftarten ohne führendes „@“-Zeichen verwendet werden.
Exportieren im PDF-Format
Wenn (Crystal Reports) Berichte in das PDF-Format exportiert werden, kann es zu Abweichungen in der Schriftgröße kommen. Einige Strichcode-Schriftarten sind davon besonders betroffen.
[1] Dient hier nur als Beispiel für zweidimensionale Strichcodes. „DataMatrix“ ist nicht im Lieferumfang von Semiramis enthalten, kann aber zum Beispiel von „IDAutomation.com, Inc.“ erworben werden.
[2] Außerdem muss auch die Druckerauflösung beachtet werden (siehe Kapitel „Druckhinweise“)
[3] Die Auswahl der Strichcode-Schriftarten kann auch zu einem späteren Zeitpunkt getroffen bzw. wieder geändert werden, indem man unter „Systemsteuerung/Software“ die Schaltfläche „Ändern“ (Modify) auswählt.
[4] LOGMARS (Logistics Applications of Automated Marking and Reading Symbols) bzw. MIL-STD-1189B spezifiziert die Anwendung von Code 39 gemäß „United States Department of Defense“. Diese Spezifaktion sieht die Verwendung eines Prüfzeichens vor.
[5] Dabei wird von einem Druckverhältnis V = 3:1 und einer Trennlückenbreite I = X ausgegangen. Diese Werte entsprechen den ausgelieferten Schriftarten C39* bzw. HC39*.
[6] Die meisten Windows-Anwendungen behandeln das Leerzeichen gesondert und erlauben nicht statt eines Leerzeichens ein spezielles Symbol auszugeben. Das Zeichen „=“ gehört nicht zum (Standard-)Zeichenumfang von Code 39.
[7] Entspricht Code 128 mit einem „doppelten“ Startzeichen (START A/B/C + FCN1)
[8] Wenn AIs mit variabler Länge benutzt werden, müssen die Daten mit einem FCN1 Zeichen abgeschlossen werden, außer es handelt sich um die letzten Daten in dem Stichcode.
[9] Der Buchstabe „x“ ist durch eine Ziffer zu ersetzen, die die Länge der Daten angibt.
[10] Der Buchstabe „y“ ist durch eine Ziffer zu ersetzen, die die Anzahl der Nachkommastellen angibt.
[11] In Deutschland auch als „Nummer der Versandeinheit“ (NVE) bezeichnet.
[12] Abweichend von Dokumentation (IDAutomation, Inc.) ist die Prüfziffer nicht in dem Rückgabewert enthalten.
[13] Die Tabelle erhebt keinen Anspruch auf Vollständigkeit, sondern soll lediglich einen groben Überblick vermitteln. In einigen der aufgeführten Länder werden zudem auch OCR-A/B verwendet.
[14] Die Unterschiede werden teilweise erst bei hoher Druckauflösung oder Bildschirmvergrößerung (Zoom) sichtbar.
[15] Die Unterschiede werden teilweise erst bei hoher Druckauflösung oder Bildschirmvergrößerung (Zoom) sichtbar.
[16] Entscheidend ist hierbei die Wellenlänge des vom Scanner verwendeten Lichts (häufig rot).