
Kurzbeschreibung
Große Software-Systeme bestehen naturgemäß aus verschiedenen Komponenten. Dies dient unter anderem der Komplexitätsreduktion der einzelnen Komponenten, der Verteilung von Last bzw. der gezielten Nutzung begrenzter Ressourcen und nicht zuletzt der Erweiterbarkeit. Eine im Rahmen der Erweiterbarkeit häufig auftretende Anforderung ist die nach der Integration eines bestehenden Software-Systems mit einer neuen Komponenten oder gar einem weiteren Software-System. Die Fragestellungen, die in diesem Umfeld auftreten, sind in großen Teilen unabhängig vom konkreten Software-System, der gewählten Plattform oder Programmiersprache. In einem konkreten Integrationsszenario gilt es darüber hinaus die für die gegeben Rahmenbedingungen passende Schnittstellentechnologie und Architektur zu wählen.
Dieses Dokument soll eine Hilfestellung bei der Findung der richtigen Entscheidung sein. Im ersten Teil werden die verschiedenen Aspekte, die bei der Integration von Software-System eine Rolle spielen aufgeführt und ihre Auswirkungen auf Faktoren wie Performance, Antwortzeiten, Ressourcenverbrauch usw. beschreiben. Im zweiten Teil werden konkrete Möglichkeiten für die Integration eines Software-Systems beschreiben, wobei speziell auch die Besonderheiten bei der Integration mit Comarch ERP Enterprise ausgeführt sind.
Ziel dieses Dokumentes ist auch, aufzuzeigen, dass es nicht „die“ Schnittstellentechnologie gibt – und nicht geben kann – die alle Anforderungen gleichermaßen gut erfüllt. Die richtige Wahl hängt vom konkreten Szenario und den Rahmenbedingungen ab. Die beste Lösung kann gleichwohl der Austausch einer Datei im Datensystem als auch der Aufruf eines Web-Service über das Internet sein.
Die inhaltlichen Fragen einer Integration, d.h. welche Dienste, Datenstrukturen und Daten eine Schnittstelle bieten muss, sind nicht Teil dieses Dokumentes und auch sind nicht durch die Wahl der Schnittstellentechnologie zu beeinflussen.
Zielgruppe
- Entscheider
- Entwickler
Beschreibung
Client und Server
Wenn Abläufe in Software-Systemen verteilt stattfinden, übernimmt eine Komponente die Rolle eines Clients, der Anfragen stellt und eine andere Komponente die Rolle eines Servers, der Anfragen beantwortet. Im Allgemeinen befindet sich zwischen Client und Server ein Netzwerk, welches die Anfragen mit einem gegebenen Protokoll und einen bestimmten Codierung überträgt. In machen Fällen können sich die Rollen von Client und Server im Verlauf der Kommunikation oder der Zeit ändern. Beispielsweise ist ein Comarch ERP Enterprise Application Server der Server für einen Browser-Client, er ist jedoch gleichermaßen selbst ein Client eines Datenbank-Servers. Als Client wird im Folgenden immer die Komponente bezeichnet, die eine Anfrage absetzt.
Qualität von Software-Systemen
Bei der Erweiterung eines Software-Systems sollte darauf geachtet werden, dass nicht nur die Erweiterung selbst eine entsprechende Qualität besitzt, sondern auch dass die Auswirkungen auf das bestehende Software-System dessen Qualität nicht beeinträchtigen. Folgende Qualitätsmerkmale sind bei der Umsetzung von Client und Server unter anderem zu berücksichtigen
- Durchsatz
Die meisten Software-System arbeiten transaktionsorientiert. Der Durchsatz beschreibt die Anzahl der Transaktionen pro Zeit.
- Antwortzeiten
Speziell bei interaktiven Systemen, bei denen Benutzer direkt Antworten auf ihre Eingaben erwarten, sollten die Zeiten dafür ein gewisses Maß (ca. 0,5-2 Sekunden) nicht überschreiten. Es ist zu beachten, dass ein hoher Durchsatz nicht gleichbedeutend mit geringen Antwortzeiten ist und umgekehrt.
- Ressourcenverbrauch
Ressourcen sind beispielsweise Rechner, Hauptspeicher, Festplattkapazität, Netzwerkkarten, Netzwerkverbindungen, Prozessoren, Threads. Die Mengeder Ressourcen in einem Software-System ist begrenzt. Um möglichst viele Anfragen schnell bearbeiten zu können, sollten für eine Anfrage möglichst wenige Ressourcen angefordert werden und die angeforderten Ressourcen möglichst schnell wieder freigegeben werden. Gemeinsam genutzte Ressourcen müssen dabei über Sperrmechanismen geschützt werden. Dies kann den Durchsatz beeinträchtigen.
- Skalierbarkeit
Ein System sollte mit einer wachsenden Anzahl an Clients mitwachsen können um den Durchsatz zu steigern ohne dass die Antwortzeiten steigen. Dies erreicht man insbesondere über die Minimierung der Netzwerkkommunikation durch Nutzung von Caching (Datenbank-Cache, Server-Cache, Client-Cache) und durch die Parallelisierung von Aufgaben innerhalb einer Anfrage.
- Portierbarkeit
Um bei Bedarf auch andere, leistungsfähigere Hardware nutzen zu können sollte die Erweiterung portierbar sein. Einfluss haben hierbei
-
die Programmiersprache
-
die Betriebssystemplattform, sie bestimmt beispielsweise die Syntax für Pfadangaben
-
das verwendete DBMS, denn trotz der Standardisierung von SQL verwenden unterschiedliche DBMS abweichende Syntax und bieten unterschiedliche Datentypen an
-
das Kommunikationsprotokoll zwischen Client und Server
-
- Auslieferbarkeit
Wenn eine Erweiterung mehrfach installiert werden soll, muss darauf geachtet werden, dass Korrekturen und Neuerungen, die im Rahmen der Wartung und Weiterentwicklung entstehen, kontrolliert weitergegeben und mit möglichst geringen Ausfallzeiten installiert werden können.
- Sicherheit
Um die Verfügbarkeit des Systems zu gewährleisten und die in ihm enthaltenen Daten vor Zugriffen von Unbefugten zu schützen, muss es sich gegen unberechtigte Anfragen schützen können. Es gibt verschiedenste Möglichkeiten dies mit Authentifizierungs- und Authorisierungs-Mechanismen zu erreichen. Erweiterungen sollten die Sicherheitsmechanismen des bestehenden Software-Systems nicht umgehen.
- Tetstbarkeit
Erweiterungen an einem System sollten möglichst leicht testbar sein, um das korrekte Funktionieren von Erweiterungen prüfen und Probleme untersuchen zu können.
Nutzung der Infrastruktur
-
bestehenden Dienste wie Caching, Sperren und Berechtigungen usw. genutzt werden sollten um Ressourcen zu schonen und den Administrationsaufwand zu minimieren, und zum anderen, dass
-
an den Stellen, wo diese Dienste bewusst oder gezwungener Maßen nicht verwendet werden, dadurch keine Konflikte oder Fehler entstehen.
- Caching
-
Browser-Cache
-
Shared-Cache auf dem Comarch ERP Enterprise Application Server
-
Seiten-Cache auf dem Datenbank-Server
-
- Sperren
-
Semaphoren in Java (synchronized-Anweisung)
-
Business-Object-Sperren und Logische Sperren in Comarch ERP Enterprise
-
Tabellen-, Seiten- und Zeilensperren auf der Datenbank
-
- Berechtigungen
- Client-Zertifikate
- Comarch ERP Enterprise Berechtigungen und Berechtigungsrollen
-
Datenbankberechtigungen auf den Objekten und Benutzern des DBMS
Das Netzwerk
- Blockgröße
Netzwerke senden Daten standardmäßig in einzelnen Blöcken. Im Fall von TCI/IP heißen diese Blöcke Pakete können Nutzdaten bis zum Umfang von standardmäßig 4 Kilobyte tragen.
- Bandbreite
Dies ist die Menge an Information, die gleichzeitig über eine Leitung übertragen werden kann.
- Latenz
Die ISO-OSI Netzwerk-Infrastruktur definiert verschiedenen Transportschichten der ISO-OSI).Jeder Übergang in eine andere Schicht und jede Weiterleitung einer Anfrage z.B. Weiterleitung eines TCI/IP-Paketes von einem Router an den nächsten Router, kostet Zeit.
- Topologie
Die Anzahl der Knotenpunkte und ihre Verbindungen untereinander beeinflussen den Weg eines Paketes von der Quelle zum Ziel.
Hieraus ergeben sich folgende Konsequenzen:
-
Jede Anfrage kann höchstens so schnell beantwortet werden, wie es die Latenz zulässt. Dies lässt sich auch durch einen beliebig große Bandbreite nicht ändern.
-
Die Übertragungszeit einer Datenmenge, die in die Nutzdaten eines einzelnen Paketes passt, wird praktisch ausschließlich durch die Latenz bestimmt. Es ist also kontraproduktiv, Daten in Blöcken zu übertragen, die kleiner als diese Größe sind.
-
Die Erhöhung der Bandbreite hilft, die Übertragungszeit großer zusammenhängender Datenmengen zu minimieren. Wenn große Datenmengen übertragen werden, sollten sie blockweise übertragen werden, um die Bandbreite ausnutzen zu können.
Das Protokoll
- Zustandsbehaftetes oder zustandsloses Protokoll
Hält der Server einen Zustand je Client oder wird jede Anfrage als neue Anfrage von einem beliebigen Client interpretiert?
- Verschlüsseltes oder unverschlüsseltes Protokoll
Handeln Client und Server eine Verschlüsselung der Verbindung aus oder werden die Daten unverschlüsselt übertragen?
Die Anfragen
- Anzahl der Clients
Wie viele Clients stellen parallel Anfragen? - Frequenz der Anfragen
Wie viele Anfragen stellt ein Client pro Zeit? - Erwartete Antwortzeiten
Muss die Antwort im Mittel schnell verfügbar sein? - Datenvolumen
Welche Menge an Daten wird bei der Anfrage mitgeschickt und welche Menge an Daten wird als Antwort zurückerwartet? - Datenformat
Sind die Daten binär oder als Text codiert?
Ist die Struktur der Daten proprietär oder standardisiert?
Werden die Daten in der Anfrage selbst verschlüsselt? - Lesender oder Schreibender Zugriff
Will der Client nur Daten abfragen, oder diese auch verändern?
Wie aktuell müssen die gelesenen Daten sein? - Synchroner oder asynchroner Aufruf
Wie viel von der Antwort erwartet der Client unmittelbar? - Aktiver Aufruf oder Polling
Sendet der Client überhaupt eine spezifische Anfrage oder prüft an periodisch das Vorhandensein gewisser Daten an einer definierten Stelle? - Zustandsloser oder zustandsbehafter Aufruf
Hält der Server einen Zustand über mehrere Anfragen hinweg?
Anzahl der Clients
Bei zustandbehafteten Servern bedeutet jeder angemeldeten Client eine für die Dauer der Anmeldung reservierte Menge an Hauptspeicher auf dem Server. Dieser Speicher wird selten angefordert und über einer vergleichsweise lange Zeit gehalten. Bei zustandlosen Servern ist die Menge an Speicher pro Anfrage dominierend und meist höher als bei einen Anfrage an einen zustandsbehafteten Server. Wenn die Übertragung der Antwort zum Client nicht über mehrere Aufrufe aufgeteilt werden kann, werden hierbei temporär potenziell sehr große Menge an Hauptspeicher allokiert.
Frequenz der Anfragen
Erwartete Antwortzeiten
Damit die Latenz des Netzwerks nicht zu stark in Gewicht fällt, sollten Anfragen von Clients immer gebündelt (d.h. in Blöcken) erfolgen. Nur so kann die zur Verfügung stehende Bandbreite ausgenutzt werden.
Datenvolumen
Bei Anfrage sollten nur die Daten mitgesendet und angefordert werden, die auch tatsächlich benötigt werden. Im Fall eines SQL-Zugriffs auf die Datenbank sollte beispielsweise die Menge der Spalten und Zeilen im Ergebnis so klein wie möglich gehalten werden.
Datenformat
Bei der Verwendung von binären Datenformaten reduziert die zu übertragende Datenmenge und ist vor allem vor hochvolumige Datenübertragungen vorzuziehen. Inwiefern die binären Daten auf verschiedenen Plattformen korrekt interpretiert werden können hängt noch von anderen Faktoren ab. So bietet CORBA beispielsweise ein über die Plattformgrenzen hinweg kompatibles Binärformat, welches vom der ORB-Zwischenschicht wenn notwendig transparent auf die Plattformspezifika (Byte Order: Litte oder Big Endian, Encoding von Zeichen) umgesetzt wird.
Die Verwendung von textbasierten Formaten ist sinnvoll für kleine Datenmengen und wenn die beteiligten Clients und Server nur wenig Logik oder auch stark unterschiedliche Technologien (z.B. ein C++ Server und ein Perl Client) verwenden. Generell bedeutet die Verwendung textbasierten Formaten einer Vergrößerung des zu übertragenden Datenvolumens bei gleicher Menge an Nutzdaten. Diese liegt je nach Format zwischen 1,5-4 (Base64-Codierung, Hex-Codierung) bis 10-15 (XML mit Start-, Ende- und Meta-Tags). Teilweise kann das erhöhte Datenvolumen durch Komprimierungen wieder aufgefangen wer-den. Jedoch ist abzuwägen ob der daraus resultierende erhöhte Rechen- bzw. Hardware-Aufwand gerechtfertigt ist.
Die Verwendung proprietärer Datenstrukturen kann für geschlossene Systeme bei denen Client und Server aus der gleichen Hand stammen durchaus sinnvoll sein. Bei Änderungen an den Anforderungen kann so schneller und angemessener reagiert werden. Bei der Kommunikation über die Grenzen des eigenen Systems hinaus ist i.A. die Nutzung von standardisierten Formaten (z.B. EDI) angemessen.
Bei der Kommunikation über die Grenzen des eigenen Systems hinaus ist die Verschlüsselung der Daten dann relevant, wenn sie über unsichere Kanäle, z.B. über das Internet via HTTP oder als E-Mail, übertragen werden sollen. Die hier zum Einsatz kommenden Verfahren setzen dabei wieder zusätzliche Logik und Metadaten zur Verschlüsselung auf dem Client- und dem Server voraus.
Lesender oder Schreibender Zugriff
Lesende Zugriffe erfordern im Allgemeinen weniger Ressourcen als schreibende Zugriffe. Wenn das Ergebnis eines lesenden Zugriffs darüber hinaus nicht zu 100% aktuell sein muss, kann auf die Anforderung von Sperren verzichtet wer-den und es können Daten aus einem Cache zurückgeliefert werden.
Synchroner oder asynchroner Aufruf
Bei einem synchronen Aufruf wartet der Client auf eine unmittelbare Antwort des Servers. Dies ist der Normalfall, da zumindest die Bestätigung, dass die Anfrage vom Server angenommen wurde berücksichtigt werden soll. Wenn die eigentliche Antwort nicht oder erst zu einem späteren Zeitpunkt benötigt wird, hat der Server die Möglichkeit, auf das Freiwerden von Ressourcen zu warten.
Aktiver Aufruf oder Polling
Beim aktiven Aufruf des Servers durch den Client müssen Client und Server zumindest zeitweise synchron kommunizieren. Der Vorteil ist, dass der Server nur dann Daten bereitstellt, wenn der Client sie erwartet. Beim Polling prüft der Client ohne vorherige Anfrage an den Server, periodisch ob an einer für beide Seiten zugreifbaren Stelle Daten, z.B. in Form einer Datei, vorhanden sind. Polling eignet sich für die Übertragung großer Datenmengen, die vom Server ohne zusätzliche Eingangsparameter zur Verfügung gestellt werden können. Eine Rückmeldung von Fehlern auf dem Client an den Server erfolgt hierbei normalerweise nicht. Es gibt auch die Möglichkeit die Varianten „aktiver Aufruf“ und „Polling“ zu kombinieren. Hierbei sendet der Client zunächst eine Anfrage an den Server und beginnt erst danach mit dem Polling.
Zustandsloser oder zustandsbehafteter Aufruf
Bei der Verwendung von zustandslosen Aufrufen muss die Authentifizierung bei jeder Anfrage erneut erfolgen, was sich negativ auswirkt, wenn die Frequenz der Anfragen hoch ist. Darüber hinaus müssen bei zustandlosen Aufrufen komplexe Abläufe immer in eine einzige Anfrage verpackt und das gesamte Ergebnis in einer Antwort gesendet werden. Dies führt zu wenig modularen Schnitt-stellen. Da für die Bearbeitung der Anfrage hierfür meistens, zumindest temporär, die Anfragen und die Antwort vollständig im Hauptspeicher aufgebaut wer-den müssen, eignet sich diese Art des Aufrufs auch nicht für die Übermittlung von Massendaten. Bei zustandsbehafteten Aufrufen entsteht der Overhead der Authentifizierung nur ein Mal, komplexe Aufruf können in wieder verwendbare Teile gegliedert werden und die Übertragung der Eingangsparameters als auf des Ergebnisses der Anfrage kann in mehreren Blöcken erfolgen.
Schnittstellentechnologien
In diesem Abschnitt werden Schnittstellentechnologien vorgestellt, die zur Integration von Software-Systemen verwendet werden können. Dabei wird auch auf den Grad an Unterstützung eingegangen, die Comarch ERP Enterprise dafür im Standard bietet.
Dateien
Bei der Übertragung von Daten in Form von Dateien werden die Daten an einer zentralen Stelle zur Verfügung gestellt, auf die der Server schreibenden und der Client zumindest lesenden Zugriff hat.
Dateien sind auch für große Datenmengen gut geeignet. Ein Beispiel für die Verwendung von Dateien zum Datenaustausch zwischen verschiedenen Systemen bietet der BIS. Mit dem BIS lassen sich Daten automatisiert importieren oder exportieren.
Einer der Nachteile von Dateien ist das Fehlen von Transaktionen. Wenn eine Datei für einen anderen Prozess sichtbar bzw. zugreifbar wird und welcher In-halt gelesen wird hängt sehr stark vom Betriebssystem ab.
Comarch ERP Enterprise unterstützt dabei das Dateisystem des Application-Servers sowie den Knowledge Store.
Dateisystem des Application-Servers
Comarch ERP Enterprise kann auf das Dateisystem des Application-Servers zugreifen. Je nach Konfiguration des Betriebssystems stehen hier sowohl das lokale Dateisystem also auch entfernte Dateisysteme („Netzlaufwerke“) zur Verfügung.
Dateien werden über ihren Dateipfad angesprochen. Dabei ist zu beachten, dass Dateipfade vom Rechner und vom seinem Betriebssystem abhängig sind und daher möglicherweise nicht Application-Server-übergreifend verwendet werden können. Ein Möglichkeit diese Unabhängigkeit wieder zu erreichen, ist die Verwendung vom Dateipfaden relativ zum Ordner „semiramis/usr“. Der Dateiserver-Pfad zum „semiramis“-Ordner kann auf jedem Comarch ERP Enterprise Application Server in der für ihn gültigen Schreibweise abgefragt werden. (Methode com.cisag.pgm.util.ServerInfo.getFileServer Directory). Im BIS, bei der Ausgabe von Dokumenten und bei Reorganisationen stehen hierfür auch schon entsprechende Variablen („{semiramis}“) zur Verfügung.
Knowledge Store
Der Knowledge Store stellt ein datenbankgestütztes Dateisystem zur Verfügung. Seine Dateipfade sind Application-Server-übergreifend gültig und vom Betriebssystem unabhängig.
Fremdsoftware kann auf den Knowledge Store per WebDAV über https zugreifen. Die ermöglicht Zugriff direkt von Client-Rechnern aus, die keinen Zugriff auf das Dateisystem des Application-Servers besitzen. Da es sich bei WebDAV um einen relativ neuen Standard handelt, wird diese Art des Zugriffs noch nicht von allen Betriebssystemen und Anwendung angeboten. Die Authentifizierung erfolgt dabei per Zertifikat oder Kennwort.
Datenbanken
SQL (Direkter Zugriff)
Ein direkter Zugriff auf Datenbanken ist von Java aus beispielsweise über die JDBC-Schnittstelle möglich, wobei ein JDBC-Treiber für die jeweilige Datenbank verwendet werden muss. Der Zugriff auf die Datenbank kann trotz der Verwendung von JDBC vom DBMS abhängig sein.
Zugriff auf fremde Datenbanken
Aus Comarch ERP Enterprise heraus kann auch auf fremde Datenbanken zugegriffen werden. Hierfür kann beispielsweise die Standard-JDBC-Schnittstelle des JDK verwendet werden.
- Die Abbildung der Comarch ERP Enterprise Business Objects und der jeweiligen Datentypen ist DBMS-spezifisch und ihre Form wird von der Comarch ERP Enterprise Software AG nicht garantiert.
- Auf DBMS-Ebene liegt ein technisches Datenmodell vor, in dem GUIDs binäre Daten sind, und Zeitstempel in einem kompakten Format gespeichert werden, das kein DBMS direkt auswerten kann.
- Lesende Zugriffe umgehen das Comarch ERP Enterprise -Caching. Damit sinkt die Geschwindigkeit der Zugriffe.
- Schreibzugriffe umgehen das Comarch ERP Enterprise -Caching und -Locking. Damit werden potenziell inkonsistente Daten gelesen.
- Es finden, bis auf die Mittel des DBMS, keine Berechtigungsprüfungen statt.
Stattdessen sollten Comarch ERP Enterprise-ODBC oder der Comarch ERP Enterprise-Persistenzdienst verwendet werden.
Comarch ERP Enterprise-ODBC
Comarch ERP Enterprise-ODBC erlaubt den Zugriff auf Comarch ERP Enterprise-Datenbanken über eine in Comarch ERP Enterprise integrierte ODBC-Schnittstelle, die von externer Software verwendet werden kann. Der Zugriff ist unabhängig vom DBMS der Comarch ERP Enterprise-Datenbanken.
Bei Comarch ERP Enterprise-ODBC ist zu beachten, dass nur lesende Zugriffe auf die Datenbanken möglich sind. Technisch setzt der Zugriff die Verwendung von HTTPS voraus.
Comarch ERP Enterprise-ODBC stellt ein auf Basis der Comarch ERP Enterprise-Metadaten angereichertes Datenbankschema zur Verfügung. Als virtuelle Attribute sind darin Business Keys aus Beziehungen und die natürlichsprachliche Beschreibung von Valueset-Werten enthalten. Weiterhin sind virtuelle Tabellen für den Zugriff auf den Knowledge Store und dynamische Objekte enthalten. Sie können auch eigene zusätzliche Daten und Berechnungen in Form von virtuellen Tabellen und virtuellen Funktionen zugreifbar machen. Für jedes Attribut im Datenbankschema ist eine übersetzbare Beschreibung verfügbar.
Berechtigungen auf Business-Entity-Ebene werden beim Zugriff auf Comarch ERP Enterprise-ODBC ausgewertet.
Comarch ERP Enterprise-Persistenzdienst
Der Comarch ERP Enterprise-Persistenzdienst kann nur innerhalb Comarch ERP Enterprise verwendet werden. Mit einer Zwischenschicht ist jedoch ein entfernter Zugriff realisierbar. Hierfür kann beispielsweise in Comarch ERP Enterprise eine Hintergrund-Anwendung erstellt werden, die dann über CORBA oder Web-Services von extern aufgerufen wird. Durch die Unabhängigkeit vom aufrufenden Kanal sind Hintergrund-Anwendungen eine investitionssichere Alternative, da sich die Programmierer nicht mit den Gegebenheiten und Versionsabhängigkeiten eines speziellen Kanals befassen müssen.
Der Comarch ERP Enterprise-Persistenzdienst ist vom DBMS unabhängig. Er erlaubt lesende und schreibende Zugriffe und die Nutzung des Comarch ERP Enterprise-Cachings, der Sperren und optional der Berechtigungen. Es unterstützt sowohl objekt- als auch tupelbasierte Zugriff, sowie Einzel- und Massenoperationen. Es können sehr einfache Hintergrund-Anwendungen, z.B. das Ausführen eines einzelnen Datenbankzugriffes mit Hilfe von Comarch ERP Enterprise-OQL, als auch beliebige komplexe Logiken realisieren. Durch die Nutzung von bereits bestehenden Logikklassen lässt sich zudem ein hoher Grad an funktionaler Wiederverwendung erreichen.
Entfernte Aufrufe
CORBA
CORBA ist ein Protokoll für entfernte Aufrufe, der plattformübergreifend verwendbarer ist. CORBA kann zustandsbehaftet arbeiten und eignet sich daher für die Übertragung von Massendaten.
Comarch ERP Enterprise als CORBA-Server
Comarch ERP Enterprise enthält einen CORBA-Server. Das Datenformat der Schnittstelle, an das sich die Clients halten müssen, ist in einer IDL-Datei definiert.
Über die CORBA-Schnittstelle können beliebige Hintergrund-Anwendungen aufgerufen werden, die in Comarch ERP Enterprise ablaufen. Daneben steht die Funktionalität des BIS (Datenaustausch) zur Verfügung.
Bei der Anmeldung der Clients an den CORBA-Server findet eine Authentifizierung statt, und die Berechtigungen in Comarch ERP Enterprise werden geprüft.
Comarch ERP Enterprise als CORBA-Client
In einer Adaptierung kann auch von innerhalb Comarch ERP Enterprise auf einen entfernten CORBA-Server zugegriffen werden. Comarch ERP Enterprise enthält hierzu als Unterstützung im Standard nur den ORB, die zugehörigen Bibliotheken und die Dokumentation der CORBA-Beispiel-Clients für Comarch ERP Enterprise selbst, da die Art und Weise der Zugriff vollständig durch den jeweiligen CORBA-Server vorgegeben wird.
Web-Services
Web-Services verwenden das Protokoll SOAP für entfernte Aufrufe, der platt-formübergreifend verwendet werden können beziehungsweise die REST-Prinzipien werden umgesetzt bei der Realisierung eines Web Services. Sie sind eine Alternative zu CORBA, wenn keine Massendaten übertragen werden müssen, da Web Services keine zustandsbehafteten Aufrufe unterstützen.
Comarch ERP Enterprise als Web-Services-Server
Comarch ERP Enterprise enthält einen Web-Services-Server. Der Web-Services-Server erfordert die Verwendung von HTTPS. Er gibt durch eine WSDL-Datei das Datenformat der Schnittstelle (ggf. SOAP) vor, die die Clients verwenden müssen.
Über die Web-Services-Schnittstelle steht die Funktionalität analog zum CORBA-Server zur Verfügung.
Bei der Anmeldung der Clients an den Web-Services-Server findet eine Authentifizierung mittels Kennwort oder Benutzer-Zertifikat statt, und die Berechtigungen in Comarch ERP Enterprise werden geprüft.
Comarch ERP Enterprise als Web-Services-Client
Adaptierungen in Comarch ERP Enterprise können auch auf einen entfernten Web-Services-Server zugreifen. Comarch ERP Enterprise enthält hierzu als Unterstützung im Standard nur die zugehörigen Bibliotheken und die Dokumentation der Web-Services-Beispiel-Clients für Comarch ERP Enterprise selbst, da die Art und Weise der Zugriff vollständig durch den jeweiligen Web-Services-Server vorgegeben wird.
Native Protokolle
Andere Protokolle, wie TCP/IP, FTP oder Java RMI können ebenfalls verwendet werden. Sie sind insbesondere interessant, um von Comarch ERP Enterprise aus externe Server über dessen Schnittstellen anzusprechen. Comarch ERP Enterprise bietet hier jedoch keine Unterstützung im Standard.
Soll eine Adaptierung in Comarch ERP Enterprise einen Server für ein natives Protokoll realisieren, wird stattdessen empfohlen, diesen Server außerhalb von Comarch ERP Enterprise zu entwickeln und ihn über CORBA auf Comarch ERP Enterprise zugreifen zu lassen.
Kombinationen verschiedener Technologien
Performanceaspekte
Schutz gegen Ressourcenengpässe
Server-Systeme wie Comarch ERP Enterprise können nicht mit optimaler Performance arbeiten, wenn zu viele entfernte Aufrufe gleichzeitig von einem Application-Server bearbeitet werden müssen. Dies kann durch geeignete Maßnahmen vermieden werden.
Jede Session, die ein Client über entfernte Aufrufe auf einem Comarch ERP Enterprise-System öffnet, verbraucht Ressourcen wie Speicher, Rechenzeit und Datenbankverbindungen auf dem Application-Server, zu dem sich der Client verbindet. Falls für ein Szenario sehr viele Clients erforderlich sind, die alle ständig mit dem CORBA-Server verbunden sind, kann es zu Engpässen an Ressourcen kommen. Kritische Ressourcen sind in diesem Fall vor allem die Sessions (und die Datenbankverbindungen). Jede Session belegt ab dem Zeitpunkt ihrer Erzeugung einen Comarch ERP Enterprise-Thread, d. h. Heap-Speicher für den Threadstack und native Ressourcen je nach Betriebssystem. Während der Abarbeitung einer Anfrage wird ein Thread belegt. Wenn für die Bearbeitung der CORBA-Anfrage Daten von der Datenbank gelesen werden müssen, werden zusätzlich zeitweise Datenbankverbindungen belegt.
Speicher, Threads und Datenbankverbindungen sind auf dem Application-Server begrenzte Ressourcen. Ein Ressourcenengpass führt zu längeren Bearbeitungszeiten eines entfernten Aufrufes. Im schlimmsten Fall kann die Stabilität des Application-Servers insgesamt gefährdet sein.
Um Ressourcenengpässe zu vermeiden, gibt es mehrere Möglichkeiten. Die Grundidee dabei ist, den Zugriff auf kritische Ressourcen zu koordinieren, um zu viele gleichzeitige Zugriffe zu vermeiden.
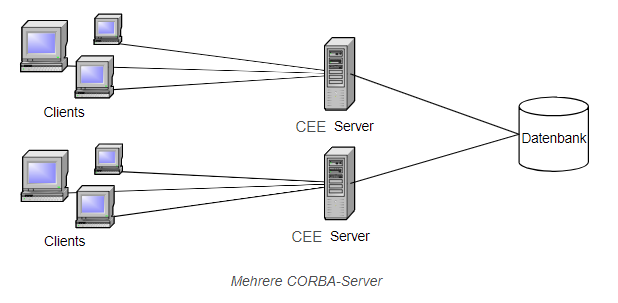
In der ersten Lösungsmöglichkeit (Abb.1) werden mehrere Comarch ERP Enterprise Application Server verwendet, auf die die Zugriffe der Clients verteilt werden. Im Beispiel werden CORBA-Clients verwendet, die beschriebene Idee gilt jedoch allgemein.
Durch das Verteilen auf mehrere Comarch ERP Enterprise Application Server wird der Speicherverbrauch pro Application-Server verringert. Allerdings kann es bei dieser Lösung zu einer hohen Beanspruchung der Datenbank kommen, falls viele An-fragen zur selben Zeit an die Application Server gelangen.
In der 2. Lösungsmöglichkeit (Abbildung 2) wird ein eigenständiger, von Comarch ERP Enterprise unabhängiger Prozess („CORBA Proxy Queue“) verwendet. Die Anfragen der Clients gehen zunächst an diesen Prozess, der sie in eine Warteschlange einreiht und dann eine begrenzte Anzahl von ihnen gleichzeitig an Comarch ERP Enterprise weitergibt. Damit sind die Zahl von CORBA-Sessions und die Zahl der Datenbankverbindungen in Comarch ERP Enterprise begrenzt. Die „CORBA Proxy Queue“ agiert als Server für die entfernten Aufrufe und als CORBA–Client. Die Implementierung einer solchen Queue kann daher in einer beliebigen Programmiersprache erfolgen, die auf den Anwendungsfall abgestimmt ist.
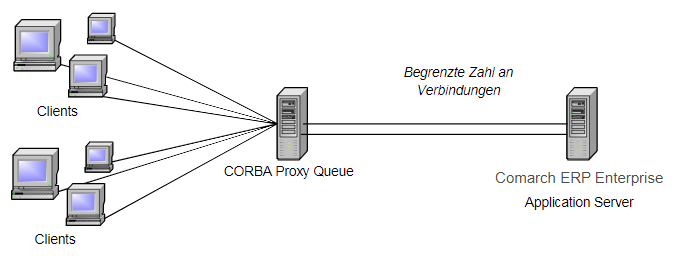
Bei beiden vorgestellten Lösungen wird davon ausgegangen, dass jeder Prozess auf einem eigenen Rechner läuft und dessen begrenzte Ressourcen damit exklusiv zur Verfügung hat. Auch eine „CORBA Proxy Queue“ sollte immer auf einem eigenen Rechner laufen. Schon bei der Entwicklung einer Anbindung an Comarch ERP Enterprise über entfernte Aufrufe sollten Tests unter Berücksichtigung der zu erwartenden Anzahl an Clients durchgeführt werden. Dabei können Sie feststellen, ob Maßnahmen zum Ressourcenschutz im konkreten Fall notwendig sind.